🤖 Integração do Assistente de IA
Use modelos implantados no Ollama para processar os resultados do reconhecimento. Você pode personalizar modelos.
1. Configurar o serviço de IA
Ollama local (recomendado, totalmente offline)
- Visite ollama.com/download para descarregar e instalar o Ollama.
- Verifique o endereço do serviço nas configurações de IA do Owl Meeting (o padrão é
http://localhost:11434/api). - Clique em "Testar" para confirmar que a conexão está normal.
- Pesquise e descarregue o modelo necessário (por exemplo,
qwen3:4b) na biblioteca de modelos do Ollama.
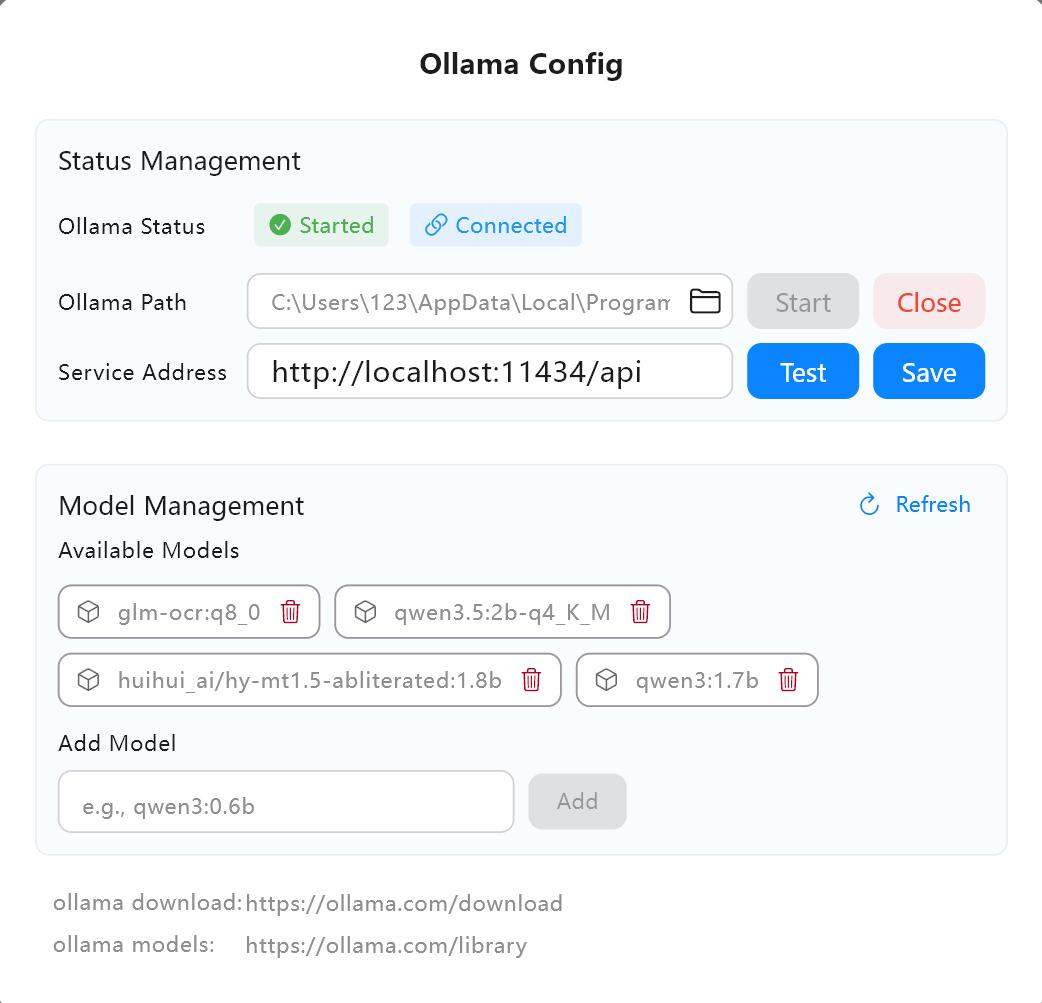 Interface de configuração do serviço de IA
Interface de configuração do serviço de IA
2. Quatro tipos de tarefas
- Tradução: Traduz os resultados do reconhecimento para outros idiomas. Pode especificar o idioma de origem e o de destino.
- Correção: Corrige erros de digitação e gramática, e otimiza a estrutura das frases para uma melhor fluidez.
- Resumo: Gera atas de reuniões ou resumos de conteúdo.
- Personalizado: Utilize modelos de prompt personalizados para processar os resultados de acordo com as suas necessidades (por exemplo, extrair pontos de ação, gerar listas de tarefas, etc.).
3. Três modos de entrada
- Individual: Processa os segmentos um a um. Este é o único modo disponível ao utilizar a IA durante a transcrição em tempo real.
- Lote: Combina vários resultados e envia-os para o modelo em conjunto para uma maior eficiência. O tamanho do lote é personalizável.
- Texto completo: Envia todos os resultados do reconhecimento como um texto completo de uma só vez. Ideal para gerar resumos de reuniões ou traduções integrais.
4. IA em tempo real vs. IA offline
- IA em tempo real: Durante o processo de transcrição em tempo real, cada segmento reconhecido é enviado automaticamente para o modelo para processamento e exibido de forma síncrona. Requer o início prévio da tarefa de IA na barra lateral. Apenas o modo "Individual" é suportado.
- IA offline: Processa os resultados da transcrição concluídos na página de detalhes do histórico. Suporta os modos "Individual", "Lote" e "Texto completo".
5. Parâmetros do modelo personalizados
Configuração integrada para parâmetros comuns de LLM (por exemplo, temperatura, top_p). Utilizadores avançados podem ativar o painel de parâmetros do modelo para ajuste fino ou passar parâmetros personalizados no formato JSON.
6. Perguntas frequentes (FAQ)
- Q: Não consegue ligar ao Ollama?
A: Verifique se o Ollama está a ser executado e se o endereço do serviço está correto (padrão:http://localhost:11434/api). - Q: Velocidade de saída lenta?
A: Mude para um modelo com menos parâmetros (por exemplo, 1.5B ou 4B) ou altere o modo de entrada de "Texto completo" para "Individual". - Q: O modo em tempo real indica "Clique primeiro no botão azul"?
A: As tarefas de IA em tempo real requerem o início do motor de IA clicando primeiro no botão azul na barra lateral.
7. Modelos recomendados
- Tarefas de tradução: Recomendado HY-MT1.5-1.8B — um modelo de tradução profissional que suporta vários idiomas com uma velocidade de inferência muito elevada.
- Tarefas gerais: Recomendada a série Qwen (por exemplo, 4B ou 8B), que possui excelentes capacidades de compreensão.