🎞️ Transcrição de ficheiros de áudio e vídeo
O modo de transcrição de áudio e vídeo (modo offline) foi concebido especificamente para o processamento de ficheiros de áudio e vídeo existentes. Todo o processamento é concluído localmente, garantindo o seu segredo comercial e a segurança dos seus dados.
🚀 Início Rápido
- Importar ficheiros: Arraste diretamente os ficheiros de áudio/vídeo para a janela do software ou clique em "Selecionar ficheiro" no centro.
- Selecionar modo e modelo: Selecione o método de processamento pretendido no lado direito da interface.
- Iniciar de imediato: Clique no botão Iniciar abaixo. Pode ver o progresso do processamento em tempo real (Inicialização -> Pré-processamento -> Segmentação -> Reconhecimento).
1. Formatos de áudio e pré-processamento
O Owl Meeting possui uma forte compatibilidade de ficheiros, mas compreender os seguintes detalhes antes de começar pode melhorar significativamente a precisão:
- Suporte de Formatos: Suporte nativo para MP3, WAV, M4A, MP4, MKV, MOV, FLAC e quase todos os outros formatos de áudio/vídeo principais.
- Melhoria de redução de ruído: Se a sua gravação tiver um ruído de fundo significativo, recomenda-se que ative a "Melhoria de redução de ruído" no painel direito. Após o processamento, pode alternar livremente entre o som original e o som melhorado no leitor para testar o efeito.
- Recomendação de canal: Para ficheiros de vídeo multicanais, recomenda-se a utilização de ferramentas incorporadas para primeiro extrair/converter para áudio mono para obter uma experiência de reconhecimento mais precisa.
 Arrastar e largar ficheiros e suporte de formatos
Arrastar e largar ficheiros e suporte de formatos
2. Modo de reconhecimento e segmentação
Pode combinar de forma flexível as estratégias de reconhecimento com base na complexidade do conteúdo do ficheiro:
- Modo Regular: O ficheiro completo utiliza o mesmo modelo de reconhecimento de voz para a transcrição. Simples e direto, a velocidade mais rápida.
- Modo Inteligente: Utilizado em conjunto com a identificação de oradores. Pode atribuir modelos exclusivos a diferentes oradores identificados (por exemplo, atribuir o Modelo 1 ao Orador A e o Modelo 2 ao Orador B).
- Estratégia de Segmentação:
- Intervalo de Tempo (VAD): Segmenta automaticamente com base em pausas de voz, adequado para declarações pessoais e podcasts.
- Separação de oradores: Corta automaticamente com base nas características da voz. Sugestão: Deve especificar um modelo de impressão vocal (Chinês/Inglês) antes de começar; outros idiomas podem ser selecionados com base na família linguística.
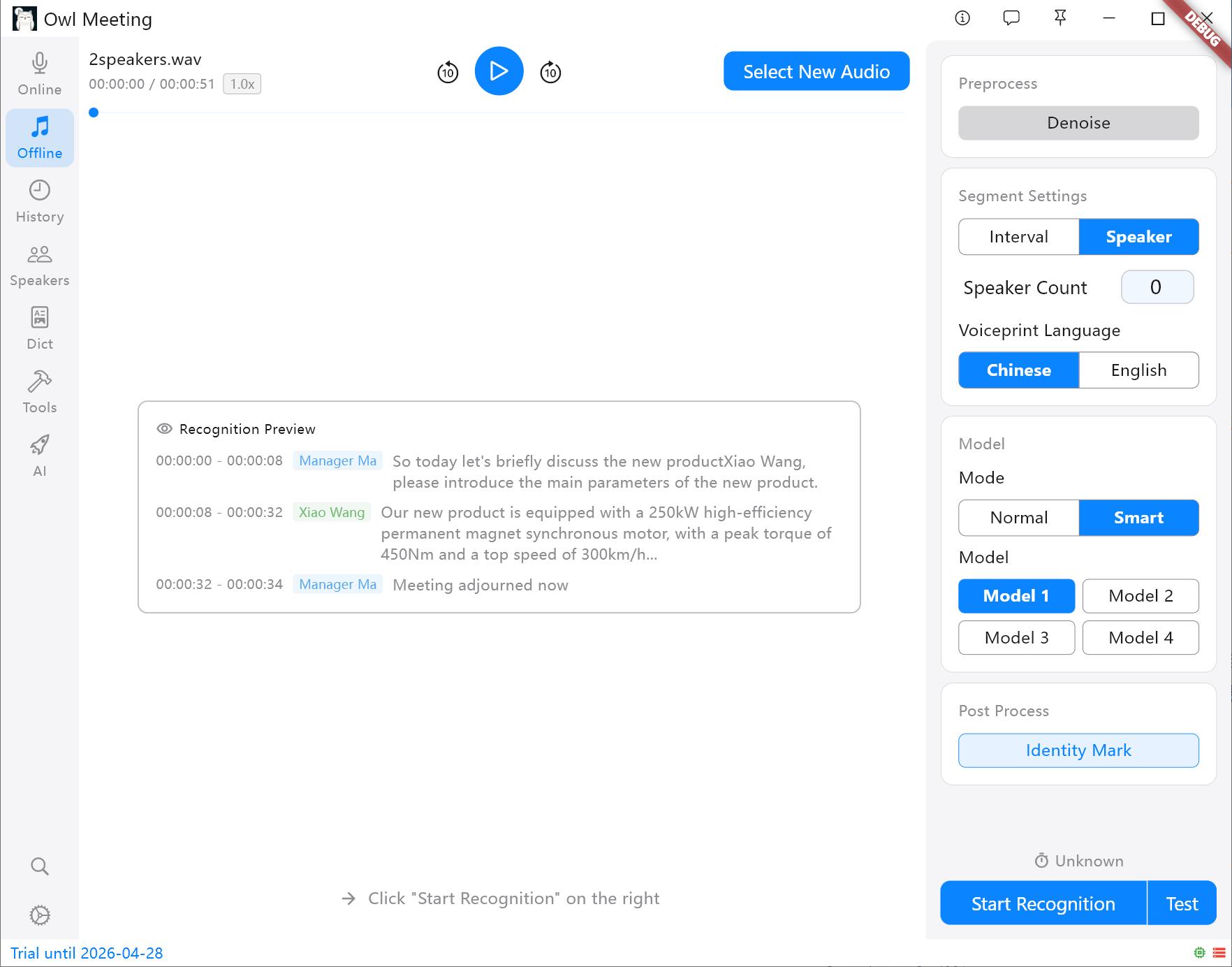 Métodos de segmentação e painel de definições
Métodos de segmentação e painel de definições
3. Modo de teste
Pré-visualize o efeito de reconhecimento das definições.
- Modo de teste: Antes de processar áudios super longos, pode utilizar a função de teste para verificar se os parâmetros atuais correspondem às expectativas (utiliza os parâmetros atuais para selecionar aleatoriamente três minutos de áudio para reconhecimento).
4. Definições exclusivas e ajuste fino
No painel de definições offline, os parâmetros de segmentação VAD (limiar de detecção de voz, tempo de silêncio/voz mín/voz máx, preenchimento de bordas) são os mesmos que no reconhecimento em tempo real. Para mais detalhes, consulte a documentação de Transcrição em tempo real. Seguem-se os itens de configuração exclusivos para a transcrição de ficheiros:
Separação e marcação de oradores
Quando o método de segmentação é definido como "Orador", os seguintes parâmetros determinam a qualidade da separação:
- Número de oradores: Se souber claramente quantas pessoas estão a falar no áudio, especifique diretamente o número exato (1~10) para obter o melhor efeito. Se definir como "Auto", o limiar de agrupamento determinará o número de pessoas.
- Limiar de agrupamento (apenas eficaz no modo "Auto"): Controla a sensibilidade do sistema às diferenças de som. Quanto mais baixo for o valor, mais fácil será separar timbres diferentes em pessoas diferentes (uma pessoa pode ser dividida em duas); quanto mais alto o valor, mais fácil é agrupar timbres semelhantes como a mesma pessoa (duas pessoas podem ser fundidas).
- Tempo de voz mín: Os segmentos de voz mais curtos do que esta duração serão descartados, filtrando ruídos muito curtos, como tosses ou interjeições.
- Intervalo máx. de fusão: Os segmentos adjacentes do mesmo orador com um intervalo de tempo inferior a este valor serão automaticamente fundidos para reduzir a segmentação fragmentada.
- Marcação de identidade: Quando ativado, o sistema comparará os oradores identificados com os que já foram inseridos na biblioteca de impressões vocais e etiquetará automaticamente os seus nomes reais. Este é também um pré-requisito para utilizar o "Modo Inteligente".
- Idioma da impressão vocal: Selecione "Chinês" para cenários em chinês e "Inglês" para cenários em inglês. Nota: Os espaços de características dos modelos de impressão vocal chinês e inglês são incompatíveis; a escolha errada resultará numa falha total de correspondência. Outros idiomas devem ser testados com base nas suas famílias linguísticas.
- Limiar de correspondência de reconhecimento (requer marcação de identidade): A identidade só é determinada quando o resultado da comparação da impressão vocal for superior a este valor. Não deve ser definido um valor demasiado elevado, caso contrário, o pessoal conhecido poderá não ser reconhecido.
Configuração avançada de segmentação
- Fusão inteligente: Funde automaticamente frases curtas com base no intervalo de tempo entre segmentos adjacentes, reduzindo os segmentos fragmentados e ajudando a melhorar a precisão global do reconhecimento.
- Intervalo de fusão: A fusão é ativada quando o intervalo entre dois segmentos é inferior a este valor (segundos).
Configuração específica do modelo
- Modelo 1 Versão quantizada: Quando ativado, a velocidade de inferência é um pouco maior, mas a precisão é ligeiramente reduzida, o que tem pouco impacto na maioria dos cenários.
- Modelo 1 Idioma: Geralmente, "Auto" está correto; especificar manualmente o idioma (chinês/inglês/japonês/coreano) quando é claramente conhecido pode melhorar a qualidade de saída.
- Modelo 1 Pontuação incorporada + Texto para número: Ativa a pontuação incorporada do modelo e a conversão de números, por exemplo, apresentando "cinquenta quilómetros" como "50 quilómetros".
Serviços de sistema
- Texto para número: Suportado apenas para chinês, convertendo números falados para formatos padrão.
- Pontuação (chinês, inglês): Se a pontuação nos resultados do reconhecimento for anormal (por exemplo, após ativar a Fusão inteligente, aparecer um grande número de pontos), este item pode ser ativado para reparação de pontuação (os modelos de pontuação devem ser descarregados primeiro em "Gestão de modelos").
5. Pós-processamento mais eficiente
Uma vez concluído o reconhecimento, pode utilizar ferramentas incorporadas para gerar diretamente transcrições de alta qualidade:
- Conversão Simplificado/Tradicional: Conversão com um clique entre chinês simplificado e tradicional (suporta a correspondência para chinês tradicional de Taiwan e Hong Kong).
- Deduplicação de conteúdos: Remove automaticamente palavras duplicadas causadas pela sobreposição de áudio ou alucinações do modelo.
- Substituição de palavras profissionais: Utilize a função "Dicionário Profissional" para corrigir com um clique termos profissionais ou iniciais de nomes no texto.
6. Desempenho extremo
Graças ao motor de inferência local profundamente otimizado, o Owl Meeting pode atingir velocidades extremas mesmo no processador de um computador de escritório normal:
- Computadores de entrada/antigos (ex: i5-4210m): Um ficheiro de áudio de 30 minutos pode ser concluído em cerca de 3 minutos.
- Computadores domésticos/de escritório comuns (ex: i5-11400H): Um ficheiro de áudio de 30 minutos demora normalmente apenas cerca de 1 minuto.
7. FAQ e Dicas
- P: Porque é que a documentação enfatiza repetidamente a conversão de multicanais para mono?
R: As gravações multicanais (estéreo) estão sujeitas a interferências de eco em ambientes complexos. Após a conversão para mono, a extração das características da impressão vocal pelo motor de IA será mais pura, o que pode melhorar significativamente a precisão da separação de oradores. - P: Os oradores identificados tornaram-se Speaker_0, Speaker_1...?
R: São IDs temporários atribuídos pelo sistema. Pode clicar diretamente nestes IDs na página de resultados para mudar o nome global. O sistema registá-los-á automaticamente e eles entrarão em vigor nos ficheiros SRT ou TXT exportados posteriormente. - P: Quero que o texto reconhecido seja convertido diretamente para chinês tradicional?
R: Após a conclusão do reconhecimento, clique no botão "Conversão Simplificado/Tradicional" abaixo e selecione o código regional correspondente (como "Chinês tradicional" ou "Taiwan tradicional") para converter todo o texto com um clique.