🤖 AI アシスタントの統合
Ollama にデプロイされたモデルを呼び出して、認識結果を処理します。テンプレートをカスタマイズして、さまざまなタスクを処理可能です。
1. AI サービスの構成
ローカル Ollama (推奨、完全オフライン)
- ollama.com/download にアクセスして、Ollama をダウンロードしインストールします。
- Owl Meeting の AI 設定でサービスアドレスを確認します(デフォルトは
http://localhost:11434/api)。 - 「テスト」をクリックして、接続が正常であることを確認します。
- Ollama モデルライブラリで必要なモデル(例:
qwen3:4b)を検索してプルします。
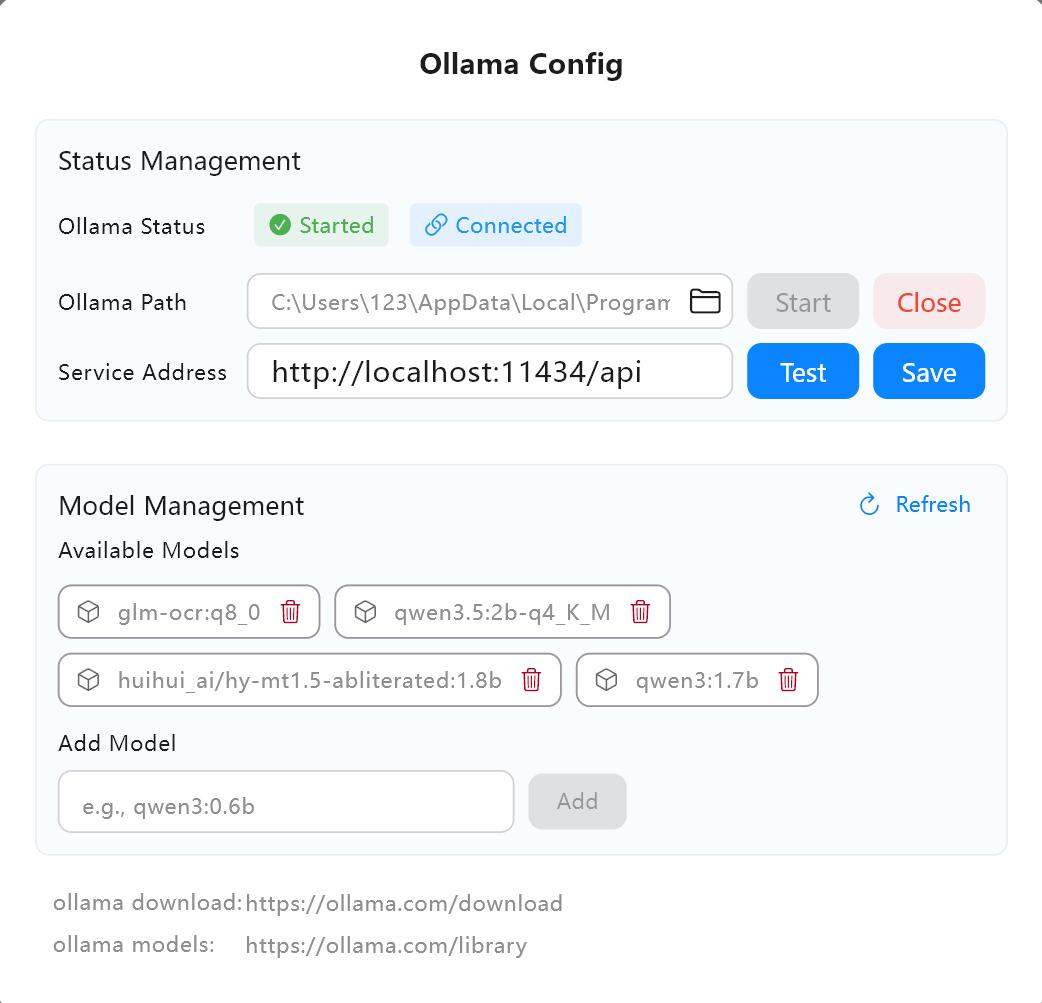 AI サービス設定インターフェース
AI サービス設定インターフェース
2. 4種類のタスクタイプ
- 翻訳:認識結果を他の言語に翻訳します。ソース言語とターゲット言語を指定できます。
- 校正:誤字脱字や文法ミスを修正し、文章構造を最適化して読みやすくします。
- 要約:会議の議事録や内容の要約を生成します。
- カスタム:独自のプロンプトテンプレートを使用して、ニーズに合わせて結果を処理します(例:アクションアイテムの抽出、To-do リストの生成など)。
3. 3種類の入力モード
- シングル:セグメントを1つずつ処理します。リアルタイム認識中に AI を使用する場合は、このモードのみが利用可能です。
- バッチ:複数の結果を結合してまとめてモデルに送信し、効率を高めます。バッチサイズはカスタマイズ可能です。
- フルテキスト:すべての認識結果を一度に完全なテキストとして送信します。会議の要約や全文翻訳に最適です。
4. リアルタイム AI とオフライン AI
- リアルタイム AI:リアルタイム認識中に、認識された各セグメントを自動的にモデルに送信して処理し、同期して表示します。まずサイドバーで AI タスクを開始する必要があります。「シングル」モードのみをサポートします。
- オフライン AI:履歴詳細ページで完了した認識結果を処理します。「シングル」、「バッチ」、「フルテキスト」の各モードをサポートします。
5. カスタムモデルパラメータ
一般的な LLM パラメータ(temperature、top_p など)の組み込み構成。上級ユーザーは、微調整のためにモデルパラメータパネルを有効にしたり、JSON 形式でカスタムパラメータを渡したりできます。
6. よくある質問 (FAQ)
- Q: Ollama に接続できませんか?
A: Ollama が実行されているか、およびサービスアドレスが正しいかを確認してください。デフォルトはhttp://localhost:11434/apiです。 - Q: 出力速度が遅いですか?
A: パラメータ数の少ないモデル(例:1.5B または 4B)に切り替えるか、入力モードを「フルテキスト」から「シングル」に変更してください。 - Q: リアルタイムモードで「最初に青いボタンをクリックしてください」と表示されますか?
A: リアルタイム AI タスクでは、まずサイドバーの青いボタンをクリックして AI エンジンを起動する必要があります。
7. 推奨モデル
- 翻訳タスク:推奨 HY-MT1.5-1.8B — 複数の言語をサポートし、推論速度が非常に速いプロフェッショナルな翻訳モデルです。
- 全般的なタスク:推奨 Qwen3 シリーズ(例:4B または 8B)。優れた理解能力を備えています。