声紋と言語識別管理
声紋ライブラリは、Owl Meetingが「誰が話しているかを知る」ためのコア機能です。各個人の音声サンプルを事前に録音しておくことで、システムはファイルの文字起こし時に発言者の名前を自動的に識別してタグ付けしたり、個人ごとに最適な認識モデルを指定したりすることができます。
1. 話者の追加
- 左側のツールバーから [声紋ライブラリ] に入ります。
- Add をクリックし、名前(必須)と備考(任意)を入力します。
- その話者に 認識モデルを指定する: ファイル文字起こし の「インテリジェントモード」を有効にすると、システムはここで指定されたモデルを使用して、その話者の音声を自動的に認識します。
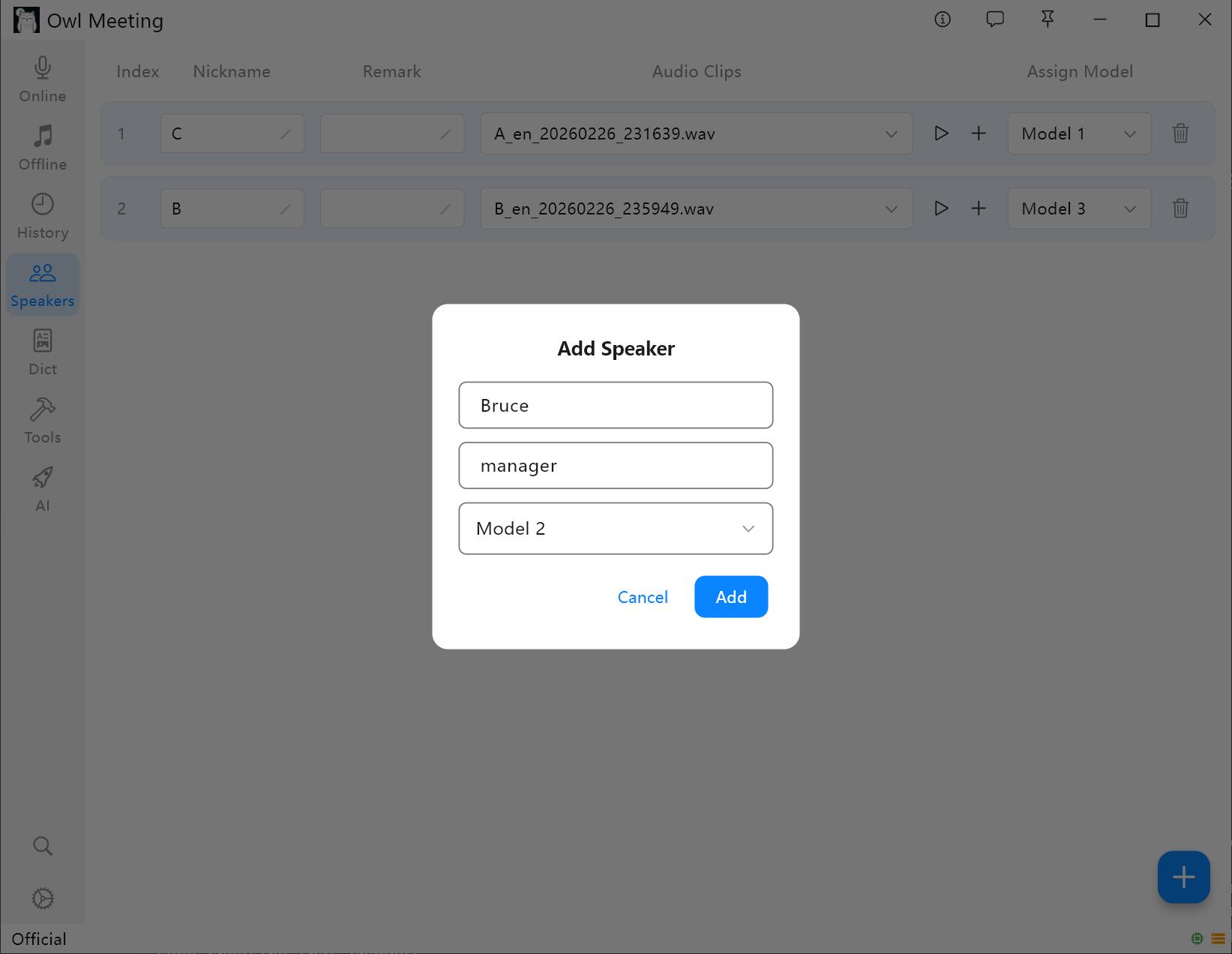 声紋ライブラリ管理インターフェース
声紋ライブラリ管理インターフェース
2. 声紋サンプルの追加
- 話者を選択し、[音声を添加] をクリックします。
- その話者のクリアな肉声が含まれているオーディオファイルを選択します。
- トリミングウィンドウで開始/終了時間を設定し、試聴して確認します。
- 声紋言語 を選択します:中国語のサンプルは「中国語」、英語のサンプルは「English」を選択します。その他の言語は語系に基づいて最も近いものを選択できます。
- [Save] をクリックすると、システムは自動的に声紋特徴を抽出し、その話者に関連付けます。
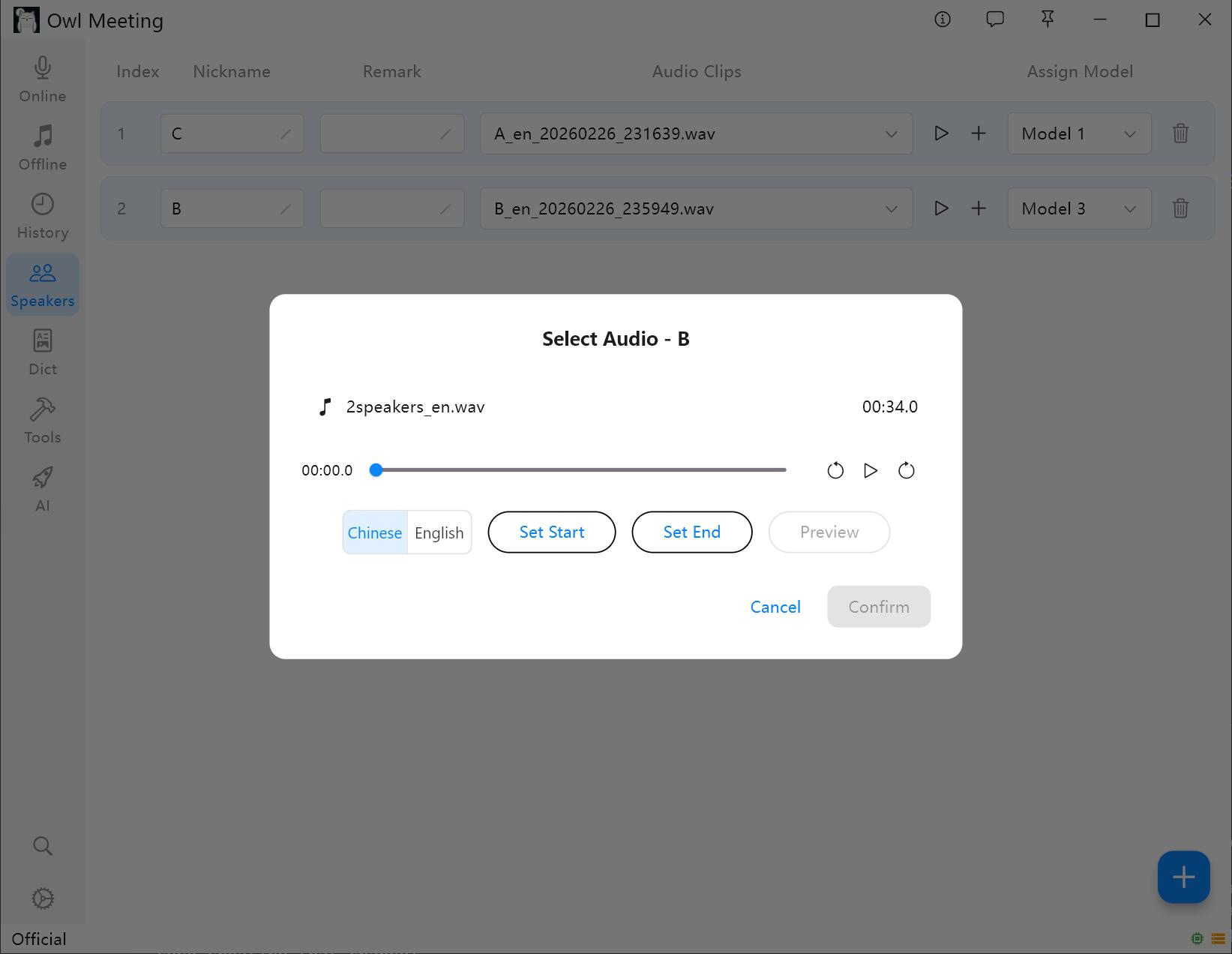 声紋サンプルの追加とトリミング
声紋サンプルの追加とトリミング
サンプル収集のベストプラクティス
- オーディオ品質:背景が静かで、ターゲットの話者の声だけが含まれているクリップを選択し、複数人が同時に話している部分は避けてください。
- 推奨時間:各サンプルセグメントは5〜30秒で十分です。短すぎると特徴が不十分になり、長すぎても追加のメリットはありません。
- 複数のサンプル:1人の話者に対して複数のサンプルを追加できます。同じ人でも、対面や電話など異なる状況で音色が大きく異なる場合、複数の状況のサンプルを追加することで認識率が向上します。
- 言語の一致:サンプル追加時に選択した言語は、ファイル文字起こし設定 の「声紋言語」と一致している必要があります。そうでない場合、照合は完全に無効になります。中英声紋モデルの特徴空間は互いに互換性がありません。
3. 日常のメンテナンス
- 話者の名前、備考、指定モデルはいつでも変更できます。
- 異なるサンプルを切り替えて表示し、直接試聴できます。
- サンプルを削除すると、対応するローカルオーディオファイルも同時に削除されます。
4. 文字起こしで声紋ライブラリを有効にする方法
声紋ライブラリは、主に オフラインファイル文字起こし で効果を発揮します。文字起こし結果に話者の名前を自動的に表示させるには、以下の条件を同時に満たす必要があります。
- セグメンテーション方法で [話者分離] を選択。
- 本人タグ付け スイッチをオン。
- ファイル文字起こし設定の [声紋言語] が、サンプル追加時に選択した言語と一致している。
上記の条件を満たすと、認識結果の話者タグが声紋ライブラリに入力された実名に自動的に置き換わります。
5. よくある質問
- Q: 認識結果に名前が表示されず、Speaker_0、Speaker_1としか表示されません。
A: 上記の「文字起こしで声紋ライブラリを有効にする方法」の3つの項目を1つずつ確認してください。最も一般的な原因は、「本人タグ付け」をオンにし忘れているか、声紋言語が一致していないことです。 - Q: 名前は表示されますが、別の人になっています。
A: 認識一致しきい値を上げる(ファイル文字起こし設定 の「話者分離とマーキング」エリア)か、該当する話者に対してよりクリアな声紋サンプルを再度追加してみてください。 - Q: 自動識別された人数が正しくありません。
A: 設定で「話者数」を手動で指定することをお勧めします。自動モードを使用する場合は、「クラスタリングしきい値」を微調整して、音の違いに対するシステムの感度を制御できます。
アドバイス: ライブラリ構築時に、よく参加する各メンバーに対して1〜2つのクリアな肉声サンプルを追加しておくとよいでしょう。声紋ライブラリが整えば、以降のすべてのファイル文字起こしで身元を自動識別できるようになり、繰り返し設定する必要がなくなります。