🎞️ 音ビデオファイル文字起こし
音ビデオ文字起こしモード(オフラインモード)は、既存の録音やビデオファイルを処理するために特別に設計されています。すべての処理はローカルで完了するため、ビジネス上の秘密とデータのセキュリティが確保されます。
🚀 クイックスタート
- ファイルをインポート:音ビデオファイルをソフトウェアウィンドウに直接ドラッグするか、中央の [Select File]
- モードとモデルを選択:インターフェースの右側で必要な処理方法を選択します。
- すぐに開始:下の[Start]ボタンをクリックします。処理の進行状況(初期化 -> 前処理 -> 分割 -> 認識)をリアルタイムで確認できます。
1. オーディオ形式と前処理
Owl Meeting は強力なファイル互換性を備えていますが、開始前に以下の詳細を理解しておくと、精度を大幅に向上させることができます:
- 形式のサポート:MP3, WAV, M4A, MP4, MKV, MOV, FLAC など、ほぼすべての主要な音ビデオ形式をネイティブにサポートしています。
- ノイズ除去の強化:録音に大きな背景ノイズがある場合は、右側のパネルにある「ノイズ除去の強化」を有効にすることをお勧めします。処理が完了した後、プレーヤーで原音と強調音を自由に切り替えて効果を確認できます。
- チャンネルの推奨:多チャンネルのビデオファイルの場合、より正確な認識体験を得るために、まず内蔵ツールを使用してモノラルオーディオに抽出/変換することをお勧めします。
 ファイルのドラッグインと形式のサポート
ファイルのドラッグインと形式のサポート
2. 認識モードとセグメンテーション
ファイル内容の複雑さに応じて、認識戦略を柔軟に組み合わせることができます:
- 通常モード:ファイル全体で同じ音声認識モデルを使用して文字起こしを行います。シンプルで直接的、最も高速です。
- インテリジェントモード:話者識別と併用します。識別された異なる話者に専用のモデルを割り当てることができます(例:話者 A にモデル 1、話者 B にモデル 2 を割り当てる)。
- セグメンテーション戦略:
- 時間間隔 (VAD):音声の途切れに基づいて自動的に分割し、個人の陳述やポッドキャストに適しています。
- 話者分離:音声の特徴に基づいて自動的に切り出します。ヒント:処理を開始する前に、声紋モデル(中/英)を指定する必要があります。その他の言語は語系に基づいて選択できます。
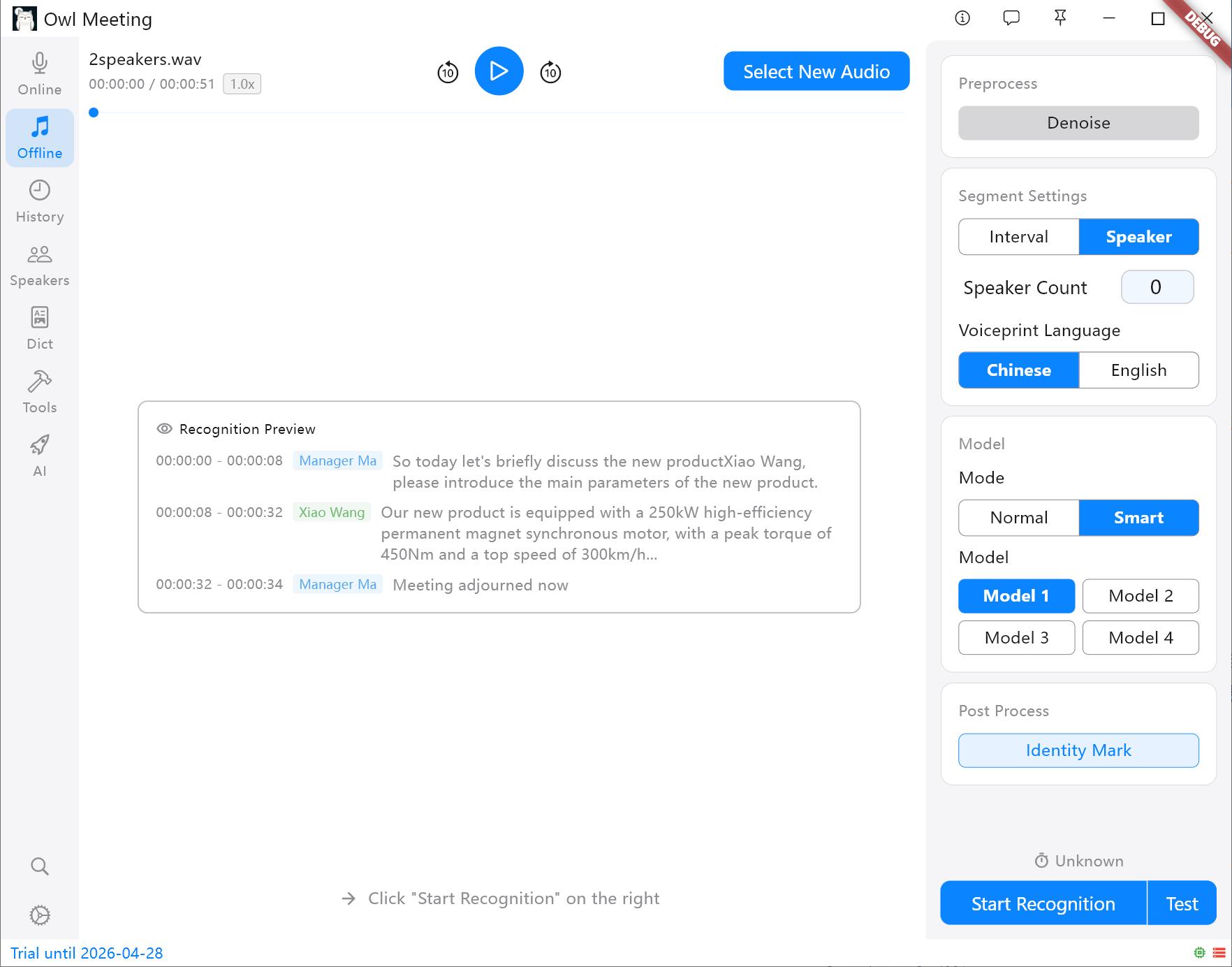 セグメンテーション方式と設定パネル
セグメンテーション方式と設定パネル
3. テストモード
設定項目の認識効果をプレビューします。
- テストモード:超長時間オーディオを処理する前に、テスト機能を使用して現在のパラメータが期待どおりかどうかを確認できます(現在のパラメータを使用して、認識のために 3 分間のオーディオをランダムに抽出します)。
4. 専用設定と微調整
オフライン設定パネルの VAD セグメンテーションパラメータ(音声判定しきい値、最小静止/音声/最大音声時間、パディング)は、リアルタイム認識と同じです。詳細はリアルタイム書き起こしドキュメントを参照してください。以下は、ファイル文字起こし専用の構成項目です:
話者分離とタグ付け
セグメンテーション方式で「話者」を選択した場合、以下のパラメータが分離の品質を決定します:
- 話者の数:オーディオ内に何人が話しているかが明確にわかっている場合は、具体的な数値(1〜10)を直接指定すると、最高の効果が得られます。「自動」に設定すると、クラスタリングしきい値によって人数が自動的に判断されます。
- クラスタリングしきい値(「自動」モードでのみ有効):音の違いに対するシステムの感度を制御します。値が低いほど、異なる音色を別々の人と見なしやすくなります(一人が二人に分割される可能性があります)。値が高いほど、似た音色を同一人物としてまとめやすくなります(二人が一人に統合される可能性があります)。
- 最小音声時間:この時間より短い音声セグメントは破棄され、せきや間投詞などの非常に短いノイズがフィルタリングされます。
- 最大統合間隔:この値より短い時間間隔を持つ同一話者の隣接するセグメントは自動的に統合され、断片的なセグメントが減少します。
- ID タグ付け:有効にすると、識別された話者が声紋ライブラリにすでに入力されている人物と比較され、本名が自動的にタグ付けされます。これは「インテリジェントモード」を使用するための前提条件でもあります。
- 声紋言語:中国語のシーンには「中国語」、英語のシーンには「英語」を選択します。注意:中英声紋モデルの特徴空間は互換性がありません。選択を間違えると、一致が完全に無効になります。その他の言語については、語系に基づいてご自身でテストする必要があります。
- 認識一致しきい値(ID タグ付けを有効にする必要があります):声紋比較結果がこの値より高い場合にのみ ID が判定されます。高く設定しすぎると、既知の人物が認識されない可能性があります。
セグメンテーションの高度な構成
- インテリジェント統合:隣接する音声セグメント間の時間間隔に基づいて短い文を自動的に統合し、断片的なセグメントを減らし、全体的な認識精度の向上に役立ちます。
- 統合間隔:2 つのセグメントの間隔がこの値(秒)より短いときに統合が実行されます。
モデル固有の構成
- モデル 1 量子化バージョン:有効にすると、推論速度がわずかに速くなりますが、精度がわずかに低下します。ほとんどのシーンで大きな影響はありません。
- モデル 1 言語:通常は「自動」で問題ありません。オーディオの言語(中/英/日/韓)が明確にわかっている場合は、手動で指定すると出力品質を向上させることができます。
- モデル 1 内蔵句読点 + テキストから数字へ:モデルに備わっている句読点と数字の変換を有効にします。例:「五十キロメートル」を「50キロメートル」と出力します。
システムサービス
- テキストから数字へ:中国語のみをサポートし、口語的な数字を「五十キロ」から「50km」などの標準形式に変換します。
- 句読点(中、英):認識結果の句読点が異常な場合(たとえば、インテリジェント統合を有効にした後に大量の句点が表示される場合)、この項目を有効にして句読点の修復を行うことができます(あらかじめ「モデル管理」で句読点モデルをダウンロードしておく必要があります)。
5. より効率的な後処理
文字起こしが完了したら、内蔵ツールを使用して高品質な原稿を直接作成できます:
- 簡繁変換:簡体字と繁体字をワンクリックで変換します(台湾および香港の繁体字一致をサポート)。
- 内容の重複削除:オーディオのオーバーラップやモデルの幻覚によって生じる重複したテキストを自動的に削除します。
- 専門用語の置換:「専門用語辞書」機能を使用して、テキスト内の専門用語や名前の略称をワンクリックで修正します。
6. 究極のパフォーマンス表現
高度に最適化されたローカル推論エンジンのおかげで、Owl Meeting は一般的なオフィス PC の CPU でも非常に高速に動作します:
- エントリーレベル/旧型コンピュータ(例:i5-4210m):30 分のオーディオは約 3 分で完了します。
- 主流の家庭用/オフィス用コンピュータ(例:i5-11400H):30 分のオーディオは通常約 1 分しかかかりません。
7. よくある質問とヒント
- Q:なぜドキュメントで、多チャンネルをモノラルに変換するように繰り返し強調されているのですか?
A:多チャンネル(ステレオ)録音は、複雑な環境でエコー干渉を引き起こしやすくなります。モノラルに変換することで、AI エンジンによる声紋特徴の抽出がより純粋になり、話者分離の精度を大幅に向上させることができます。 - Q:識別された話者が Speaker_0, Speaker_1... になりましたか?
A:これはシステムによって割り当てられた一時的な ID です。結果ページでこれらの ID を直接クリックして、グローバルな名前変更を行うことができます。システムはそれらを自動的に記録し、その後エクスポートされる SRT または TXT で有効になります。 - Q:認識されたテキストを直接繁体字に変換したいのですが?
A:認識が完了したら、下の「簡繁変換」ボタンをクリックし、対応するリージョンコード(「繁体字中国語」や「台繁」など)を選択すると、テキスト全体をワンクリックで変換できます。
ヒント: 多チャンネルのビデオファイルの場合、最も正確な認識体験を得るために、まず内蔵ツールを使用してモノラルオーディオに抽出/変換することをお勧めします。