🤖 AI 어시스턴트 통합
Ollama에 배포된 모델을 호출하여 인식 결과를 처리합니다. 다양한 작업을 위해 템플릿을 사용자 지정할 수 있습니다.
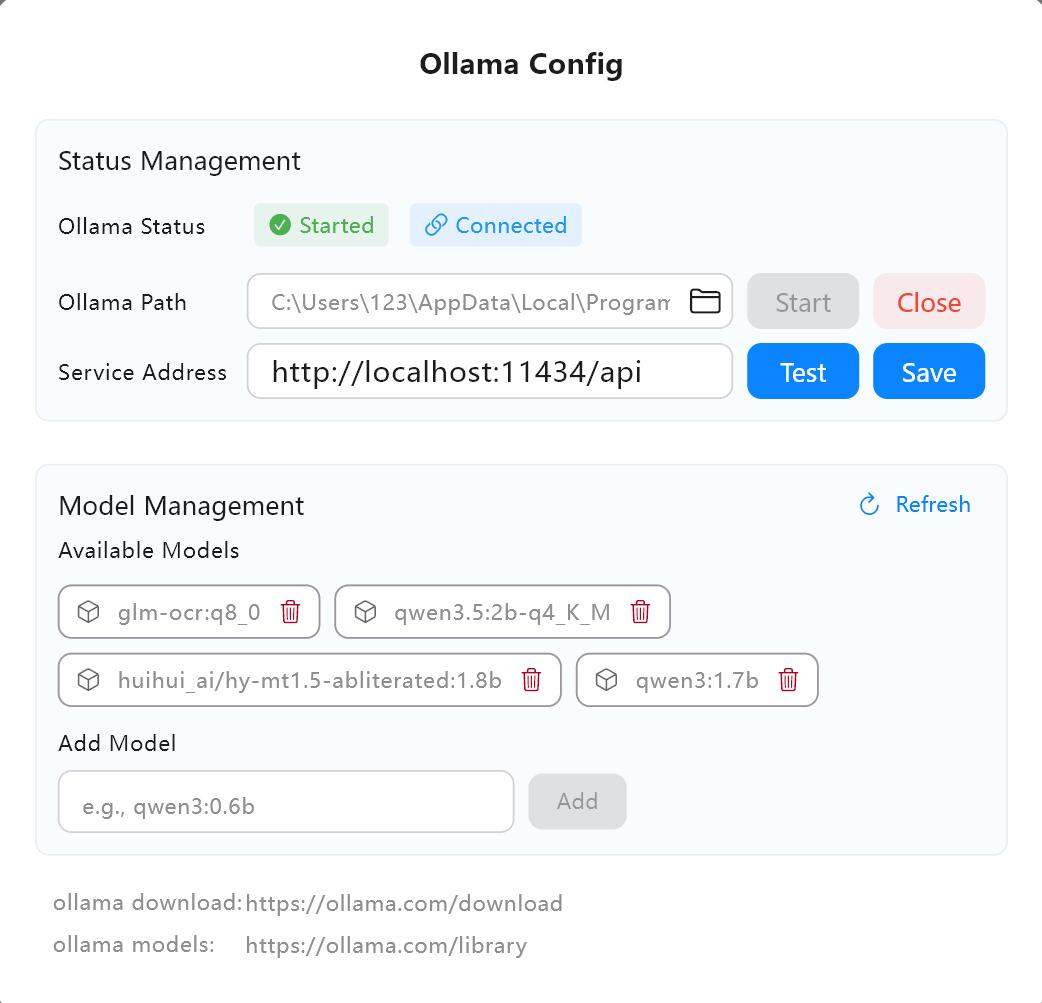
1. AI 서비스 구성
로컬 Ollama (권장, 완전 오프라인)
- ollama.com/download에 접속하여 Ollama를 다운로드하고 설치합니다.
- Owl Meeting의 AI 설정에서 서비스 주소를 확인합니다(기본값은
http://localhost:11434/api입니다). - "테스트"를 클릭하여 연결이 정상인지 확인합니다.
- Ollama 모델 라이브러리에서 필요한 모델(예:
qwen3:4b)을 검색하고 다운로드(pull)합니다.
 AI 서비스 설정 인터페이스
AI 서비스 설정 인터페이스
2. 네 가지 작업 유형
- 번역: 인식 결과를 다른 언어로 번역합니다. 원본 언어와 대상 언어를 지정할 수 있습니다.
- 교정: 오타 및 문법 오류를 수정하고, 문장 구조를 최적화하여 가독성을 높입니다.
- 요약: 회의록 또는 콘텐츠의 핵심 요약을 생성합니다.
- 사용자 정의: 나만의 프롬프트 템플릿을 사용하여 필요에 맞는 형태(예: 실행 항목 추출, 할 일 목록 생성 등)로 결과를 처리합니다.
3. 세 가지 입력 모드
- 개별: 세그먼트를 하나씩 처리합니다. 실시간 인식 중 AI 기능을 사용할 때 이용 가능한 유일한 모드입니다.
- 배치: 여러 결과를 묶어서 모델에 한꺼번에 전송하여 효율성을 높입니다. 배치 크기는 사용자 지정이 가능합니다.
- 전체 텍스트: 모든 인식 결과를 한 번에 모든 텍스트로 전송합니다. 회의 요약이나 전체 번역에 적합합니다.
4. 실시간 AI vs 오프라인 AI
- 실시간 AI: 실시간 인식 과정에서 각 인식 세그먼트가 자동으로 모델에 전송되어 처리되고 실시간으로 표시됩니다. 먼저 사이드바에서 AI 작업을 시작해야 합니다. '개별' 모드만 지원합니다.
- 오프라인 AI: 기록 상세 페이지에서 완료된 전사 결과를 처리합니다. '개별', '배치', '전체 텍스트' 모드를 모두 지원합니다.
5. 사용자 정의 모델 파라미터
일반적인 LLM 파라미터(예: temperature, top_p)에 대한 설정이 내장되어 있습니다. 고급 사용자는 미세 조정(fine-tuning)을 위해 모델 파라미터 패널을 활성화하거나 JSON 형식의 사용자 정의 파라미터를 전달할 수 있습니다.
6. 자주 묻는 질문(FAQ)
- Q: Ollama에 연결할 수 없습니까?
A: Ollama가 실행 중인지, 서비스 주소가 올바른지 확인하십시오(기본값:http://localhost:11434/api). - Q: 결과 출력 속도가 느립니까?
A: 파라미터 규모가 작은 모델(예: 1.5B 또는 4B)로 전환하거나 입력 모드를 '전체 텍스트'에서 '개별'로 변경해 보십시오. - Q: 실시간 모드에서 "먼저 파란색 버튼을 클릭하세요"라는 메시지가 표시됩니까?
A: 실시간 AI 작업은 먼저 사이드바에서 파란색 버튼을 클릭하여 AI 엔진을 활성화해야 합니다.
7. 권장 모델
- 번역 작업: HY-MT1.5-1.8B를 권장합니다 — 다국어를 지원하고 추론 속도가 매우 빠른 전문 번역 모델입니다.
- 일반 작업: 뛰어난 이해 능력을 갖춘 Qwen3 시리즈(예: 4B 또는 8B)를 권장합니다.