성문 및 화자 관리
성문 라이브러리는 Owl Meeting이 "누가 말하고 있는지"를 알 수 있게 하는 핵심 기능입니다. 각 개인의 음성 샘플을 미리 녹음함으로써 시스템은 파일 전사 시 화자의 이름을 자동으로 인식하고 태깅할 수 있으며 개인별로 가장 적합한 인식 모델을 지정할 수도 있습니다.
1. 화자 추가
- 왼쪽 도구 모음에서 "성문 라이브러리"로 들어갑니다.
- "인원 추가"를 클릭하고 이름(필수)과 메모(선택)를 입력합니다.
- 해당 화자에게 인식 모델 지정: 파일 전사의 "지능형 모드"를 켜면 시스템이 여기에서 지정된 모델을 사용하여 해당 화자의 음성을 자동으로 인식합니다.
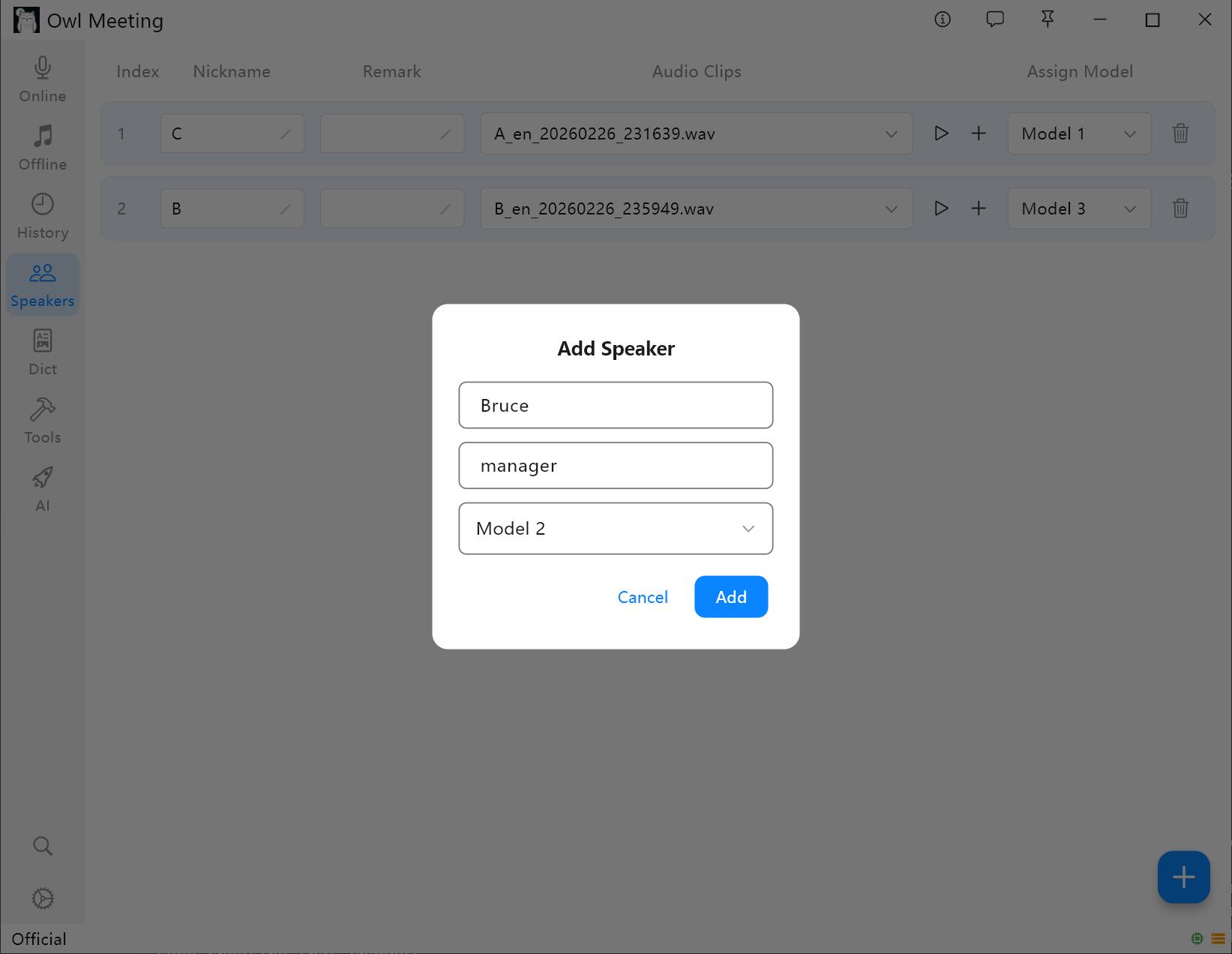 성문 라이브러리 관리 인터페이스
성문 라이브러리 관리 인터페이스
2. 성문 샘플 추가
- 화자를 선택하고 "오디오 추가"를 클릭합니다.
- 해당 화자의 명확한 음성이 포함된 오디오 파일을 선택합니다.
- 자르기 창에서 시작/종료 시간을 설정하고 미리 듣기를 클릭하여 확인합니다.
- 성문 언어를 선택합니다: 중국어 샘플은 "중국어", 영어 샘플은 "English"를 선택합니다. 다른 언어는 어계에 따라 가장 가까운 것을 선택할 수 있습니다.
- 저장을 클릭하면 시스템이 자동으로 성문 특징을 추출하고 해당 화자에게 연결합니다.
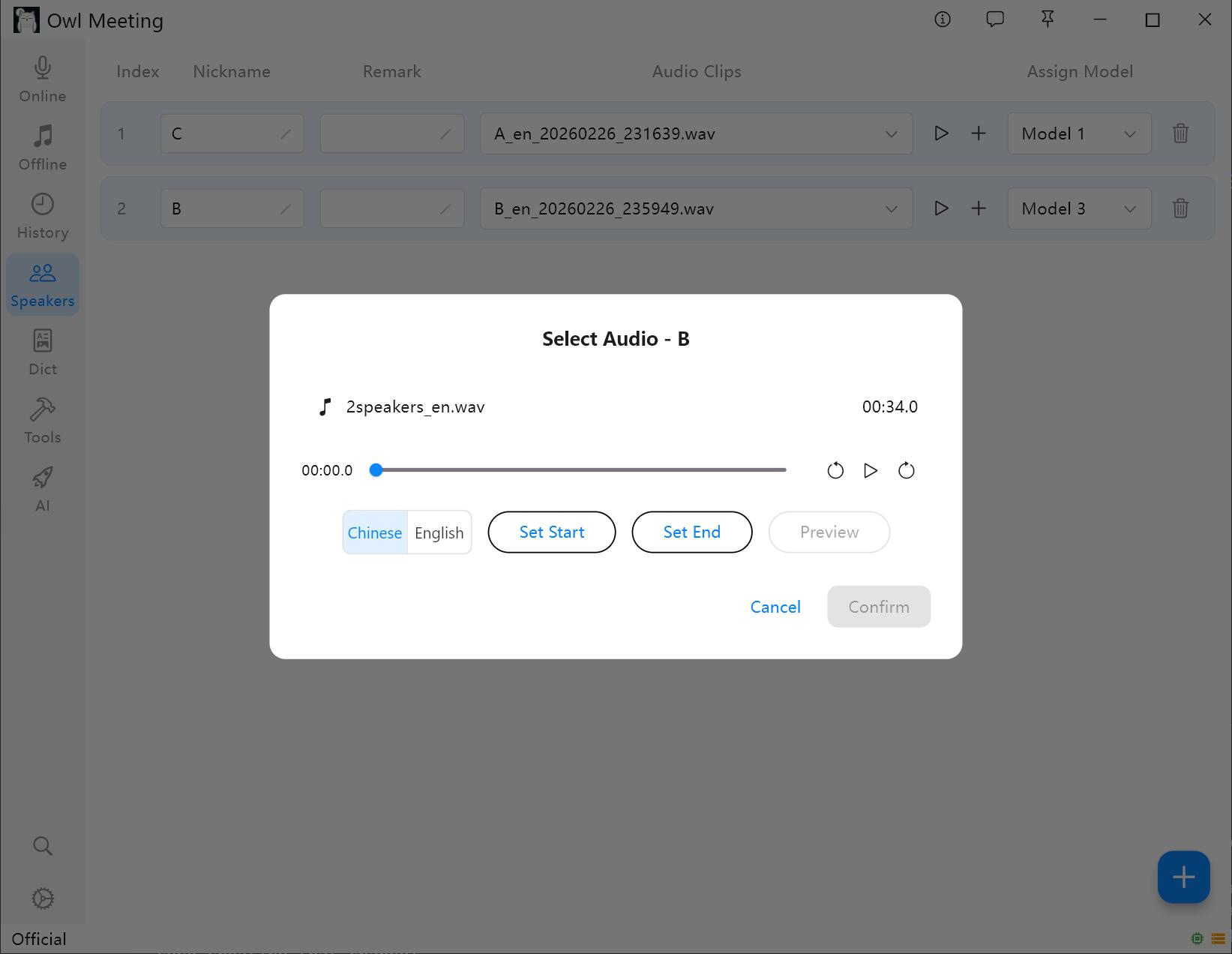 성문 샘플 추가 및 자르기
성문 샘플 추가 및 자르기
샘플 수집 모범 사례
- 오디오 품질: 배경이 조용하고 대상 화자의 목소리만 있는 클립을 선택하고 여러 명이 동시에 말하는 구간은 피하십시오.
- 시간 권장 사항: 각 샘플 구간은 5~30초면 충분합니다. 너무 짧으면 특징이 부족하고 너무 길어도 추가적인 이점은 없습니다.
- 다중 샘플: 한 화자에게 여러 샘플을 추가할 수 있습니다. 동일인이라도 대면이나 전화 등 상황에 따라 음색이 크게 다를 경우 여러 상황의 샘플을 추가하면 인식률이 향상됩니다.
- 언어 일치: 샘플 추가 시 선택한 언어는 파일 전사 설정의 "성문 언어"와 일치해야 합니다. 그렇지 않으면 일치가 완전히 무효화됩니다. 중영 성문 모델의 특징 공간은 서로 호환되지 않습니다.
3. 일상 유지 관리
- 화자의 이름, 메모 및 지정 모델을 언제든지 수정할 수 있습니다.
- 다른 샘플을 전환하여 보고 직접 들어볼 수 있습니다.
- 샘플을 삭제하면 해당 로컬 오디오 파일도 동시에 삭제됩니다.
4. 전사에서 성문 라이브러리를 유효하게 하는 방법
성문 라이브러리는 주로 오프라인 파일 전사에서 효과를 발휘합니다. 전사 결과에 화자의 이름을 자동으로 표시하려면 다음 조건을 동시에 만족해야 합니다.
- 세그먼트 방식으로 "화자"를 선택.
- "ID 태깅" 스위치를 켬.
- 파일 전사 설정의 "성문 언어"가 샘플 추가 시 선택한 언어와 일치함.
위 조건을 만족하면 인식 결과의 화자 태그가 성문 라이브러리에 입력된 실명으로 자동 교체됩니다.
5. 자주 묻는 질문
- Q: 인식 결과에 이름이 표시되지 않고 Speaker_0, Speaker_1로만 표시됩니다.
A: 위의 "전사에서 성문 라이브러리 유효 조건"의 3개 항목을 하나씩 확인하십시오. 가장 흔한 원인은 "ID 태깅"을 켜는 것을 잊었거나 성문 언어가 일치하지 않는 것입니다. - Q: 이름은 표시되지만 다른 사람으로 나옵니다.
A: 인식 일치 임계값을 높이거나(파일 전사 설정의 "화자 분리 및 태깅" 영역), 해당 화자에 대해 더 명확한 성문 샘플을 다시 추가해 보십시오. - Q: 자동 인식된 인원수가 맞지 않습니다.
A: 설정에서 "화자 수"를 수동으로 지정하는 것이 권장됩니다. 자동 모드를 사용하는 경우 "클러스터링 임계값"을 미세 조정하여 소리 차이에 대한 시스템의 민감도를 제어할 수 있습니다.
권장: 라이브러리 구축 시 자주 참석하는 각 멤버에 대해 1~2개의 명확한 음성 샘플을 추가하십시오. 성문 라이브러리가 구축되면 이후의 모든 파일 전사에서 신원을 자동 인식할 수 있어 반복 설정이 필요 없습니다.