🎞️ 오디오 및 비디오 파일 전사
오디오 및 비디오 전사 모드(오프라인 모드)는 기존의 녹음 및 비디오 파일을 처리하기 위해 특별히 설계되었습니다. 모든 작업은 로컬에서 완료되므로 비즈니스 비밀과 데이터 보안이 보장됩니다.
🚀 빠른 시작
- 파일 가져오기: 오디오/비디오 파일을 소프트웨어 창으로 직접 드래그하거나 중앙의 "파일 선택"을 클릭합니다.
- 모드 및 모델 선택: 인터페이스 오른쪽에서 필요한 처리 방식을 선택합니다.
- 즉시 시작: 아래의 시작 버튼을 클릭합니다. 처리 진행 상황(초기화 -> 전처리 -> 세그먼트 -> 인식)을 실시간으로 확인할 수 있습니다.
1. 오디오 형식 및 전처리
Owl Meeting은 강력한 파일 호환성을 갖추고 있지만, 시작하기 전에 다음 세부 사항을 이해하면 정확도를 크게 향상시킬 수 있습니다.
- 형식 지원: MP3, WAV, M4A, MP4, MKV, MOV, FLAC 등 거의 모든 주요 오디오/비디오 형식을 기본적으로 지원합니다.
- 노이즈 제거 강화: 녹음에 상당한 배경 노이즈가 있는 경우 오른쪽 패널에서 "노이즈 제거 강화"를 활성화하는 것이 좋습니다. 처리가 완료된 후 플레이어에서 원음과 향상된 음을 자유롭게 전환하여 효과를 확인할 수 있습니다.
- 채널 권장 사항: 다채널 비디오 파일의 경우 더 정확한 인식 환경을 위해 내장 도구를 사용하여 먼저 모노 오디오로 추출/변환하는 것이 좋습니다.
 파일 드래그 및 형식 지원
파일 드래그 및 형식 지원
2. 인식 모드 및 세그먼트
파일 내용의 복잡성에 따라 인식 전략을 유연하게 조합할 수 있습니다.
- 일반 모드: 전사 작업을 위해 파일 전체에서 동일한 음성 인식 모델을 사용합니다. 단순하고 직접적이며 속도가 가장 빠릅니다.
- 지능형 모드: 화자 식별과 함께 사용됩니다. 식별된 서로 다른 화자에게 전용 모델을 할당할 수 있습니다(예: 화자 A에게 모델 1, 화자 B에게 모델 2 지정).
- 세그먼트 전략:
- 시간 간격 (VAD): 음성 일시 중지를 기반으로 자동으로 세그먼트를 나누며 개인적인 진술 및 팟캐스트에 적합합니다.
- 화자 분리: 음성 특징에 따라 자동으로 나눕니다. 팁: 처리를 시작하기 전에 성문 모델(중/영)을 지정해야 합니다. 다른 언어는 어계에 따라 선택할 수 있습니다.
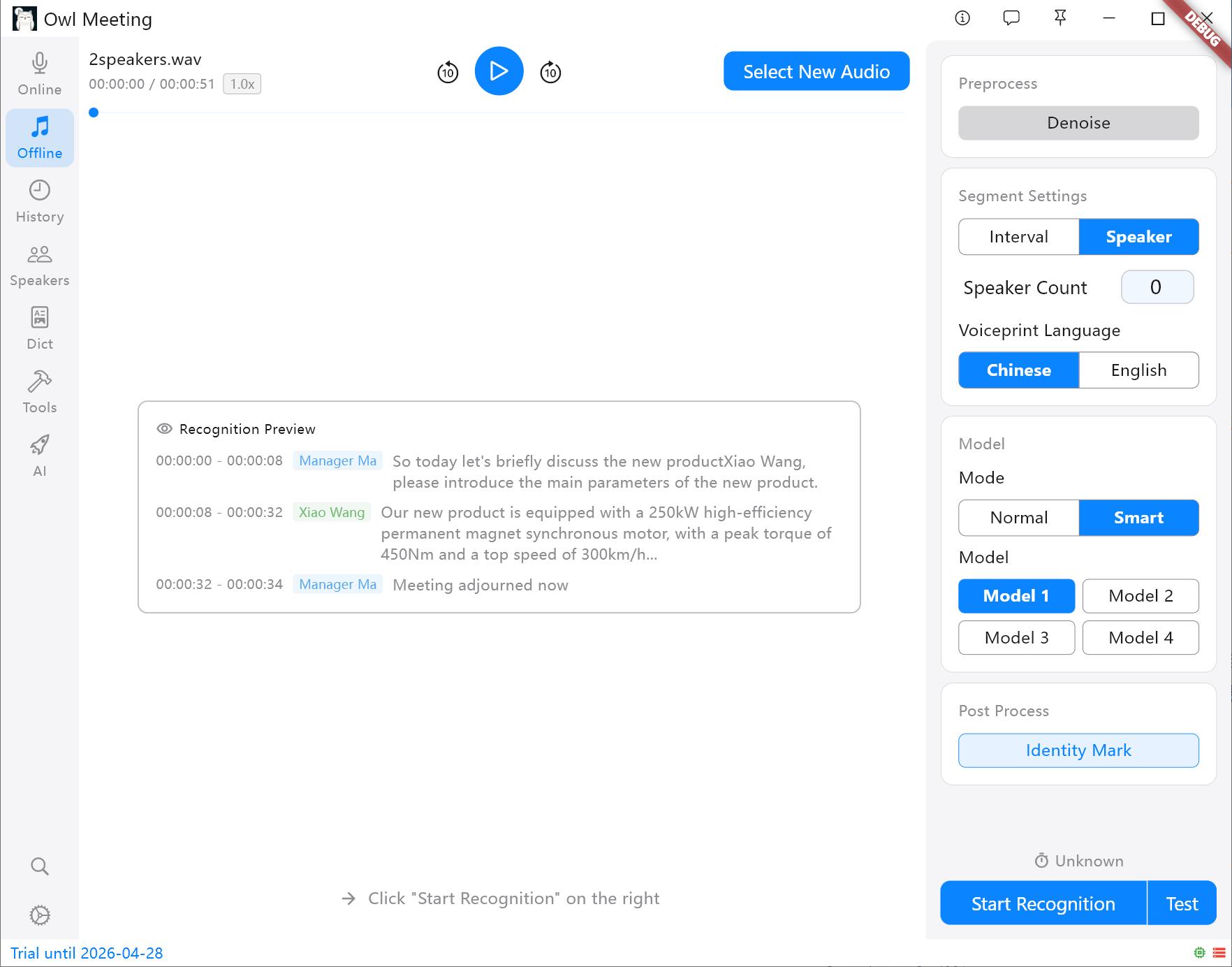 세그먼트 방식 및 설정 패널
세그먼트 방식 및 설정 패널
3. 테스트 모드
설정 항목의 인식 효과를 미리 봅니다.
- 테스트 모드: 초장시간 오디오를 처리하기 전에 테스트 기능을 사용하여 현재 매개변수가 예상대로 작동하는지 확인할 수 있습니다(현재 매개변수를 사용하여 인식을 위해 3분 분량의 오디오를 무작위로 선택함).
4. 전용 설정 및 미세 조정
오프라인 설정 패널에서 VAD 세그먼트 매개변수(음성 판정 임계값, 최소 정적/음성/최대 음성 시간, 여백 채우기)는 실시간 인식과 동일합니다. 자세한 내용은 실시간 전사 문서를 참조하십시오. 다음은 파일 전사 전용 구성 항목입니다.
화자 분리 및 태깅
세그먼트 방식을 "화자"로 선택한 경우 다음 매개변수가 분리 품질을 결정합니다.
- 화자 수: 오디오에서 몇 명이 말하는지 명확하게 알고 있는 경우 구체적인 숫자(1~10)를 직접 지정하면 가장 좋은 효과를 볼 수 있습니다. "자동"으로 설정하면 클러스터링 임계값에 의해 인원수가 자동으로 판단됩니다.
- 클러스터링 임계값("자동" 모드에서만 유효): 소리 차이에 대한 시스템의 민감도를 제어합니다. 값이 낮을수록 서로 다른 음색을 서로 다른 사람으로 분리하기 쉽고(한 사람이 두 사람으로 나뉠 수 있음), 값이 높을수록 비슷한 음색을 동일 인물로 묶기 쉽습니다(두 사람이 하나로 합쳐질 수 있음).
- 최소 음성 시간: 이 시간보다 짧은 음성 세그먼트는 폐기되어 기침이나 감탄사 같은 매우 짧은 소음을 걸러냅니다.
- 최대 병합 간격: 시간 간격이 이 값보다 짧은 동일 화자의 인접한 세그먼트는 자동으로 병합되어 조각난 세그먼트가 줄어듭니다.
- ID 태깅: 활성화하면 식별된 화자를 성문 라이브러리에 이미 입력된 인원과 비교하여 실명을 자동으로 태깅합니다. 이는 "지능형 모드"를 사용하기 위한 전제 조건이기도 합니다.
- 성문 언어: 중국어 시나리오에서는 "중국어", 영어 시나리오에서는 "영어"를 선택합니다. 주의: 중영 성문 모델의 특징 공간은 서로 호환되지 않습니다. 잘못 선택하면 일치가 완전히 무효화됩니다. 다른 언어는 어계에 따라 직접 테스트해야 합니다.
- 인식 일치 임계값(ID 태깅 활성화 필요): 성문 비교 결과가 이 값보다 높을 때만 ID가 판정됩니다. 너무 높게 설정하면 알려진 인원이 인식되지 않을 수 있습니다.
세그먼트 고급 구성
- 지능형 병합: 인접한 음성 세그먼트 간의 시간 간격에 따라 짧은 문장을 자동으로 병합하여 조각난 세그먼트를 줄이고 전반적인 인식 정확도 향상에 도움을 줍니다.
- 병합 간격: 두 세그먼트 사이의 간격이 이 값(초)보다 작을 때 병합이 실행됩니다.
모델 특정 구성
- 모델 1 양자화 버전: 활성화하면 추론 속도가 약간 빨라지지만 정밀도가 약간 저하됩니다. 대부분의 시나리오에서 큰 영향은 없습니다.
- 모델 1 언어: 일반적으로 "자동"이면 충분합니다. 오디오 사용 언어(중/영/일/한)를 명확히 알고 있는 경우 수동으로 지정하면 출력 품질을 높일 수 있습니다.
- 모델 1 내장 문장 부호 + 텍스트를 숫자로: 모델의 내장 문장 부호 및 숫자 변환 기능을 활성화합니다. 예를 들어 "오십 킬로미터"를 "50 킬로미터"로 출력합니다.
시스템 서비스
- 텍스트를 숫자로: 중국어만 지원하며 구어체 숫자를 표준 형식으로 변환합니다(예: "오십 킬로" → "50km").
- 문장 부호(중, 영): 인식 결과의 문장 부호가 비정상적인 경우(예: 지능형 병합 활성화 후 마침표가 너무 많이 나타나는 경우) 문장 부호 복구를 위해 이 항목을 활성화할 수 있습니다(먼저 "모델 관리"에서 문장 부호 모델을 다운로드해야 함).
5. 더 효율적인 후처리
식별이 완료되면 내장 도구를 사용하여 고품질 원고를 직접 생성할 수 있습니다.
- 간번체 변환: 간체와 번체를 원클릭으로 변환합니다(대만 및 홍콩 번체 일치 지원).
- 중복 내용 제거: 오디오 중첩이나 모델의 환각으로 인해 발생하는 중복된 텍스트를 자동으로 제거합니다.
- 전문 용어 대체: "전문 용어 사전" 기능을 사용하여 텍스트에 나타나는 전문 용어 또는 이름 이니셜을 원클릭으로 수정합니다.
6. 최고의 성능 표현
고도로 최적화된 로컬 추론 엔진 덕분에 일반 사무용 컴퓨터의 CPU에서도 Owl Meeting은 매우 빠른 속도를 낼 수 있습니다.
- 보급형/오래된 컴퓨터 (예: i5-4210m): 30분 분량의 오디오는 약 3분 만에 완료됩니다.
- 주요 가정용/사무용 컴퓨터 (예: i5-11400H): 30분 분량의 오디오는 일반적으로 약 1분 정도 소요됩니다.
7. 자주 묻는 질문 및 팁
- Q: 왜 문서에서 다채널을 모노로 변환하라고 반복해서 강조하나요?
A: 다채널(스테레오) 녹음은 복잡한 환경에서 에코 간섭을 일으키기 쉽습니다. 모노로 변환한 후 AI 엔진에 의한 성문 특징 추출이 더 순수해지며 화자 분리의 정확도를 크게 향상시킬 수 있습니다. - Q: 식별된 화자가 Speaker_0, Speaker_1...로 바뀌었나요?
A: 이는 시스템에서 할당한 임시 ID입니다. 결과 페이지에서 이러한 ID를 직접 클릭하여 글로벌 이름 변경을 수행할 수 있습니다. 시스템은 이를 자동으로 기록하며 후속 내보낸 SRT 또는 TXT 파일에 반영됩니다. - Q: 인식된 텍스트를 직접 번체로 변환하고 싶나요?
A: 인식이 완료되면 아래의 "간번체 변환" 버튼을 클릭하고 해당하는 지역 코드("번체 중국어" 또는 "대만 번체" 등)를 선택하여 텍스트 전체를 한 번에 변환할 수 있습니다.
팁: 다채널 비디오 파일의 경우 가장 정확한 인식 환경을 위해 내장 도구를 사용하여 먼저 모노 오디오로 추출/변환하는 것이 좋습니다.