🤖 Intégration de l'assistant IA
Appelle les modèles déployés dans Ollama pour traiter les résultats de reconnaissance. Possibilité de personnaliser les modèles pour diverses tâches.
1. Configuration du service IA
Ollama local (recommandé, entièrement hors ligne)
- Visitez ollama.com/download pour télécharger et installer Ollama.
- Vérifiez l'adresse du service dans les paramètres IA d'Owl Meeting (par défaut
http://localhost:11434/api). - Cliquez sur « Tester » pour confirmer que la connexion est normale.
- Recherchez et téléchargez le modèle requis (ex:
qwen3:4b) dans la bibliothèque de modèles Ollama.
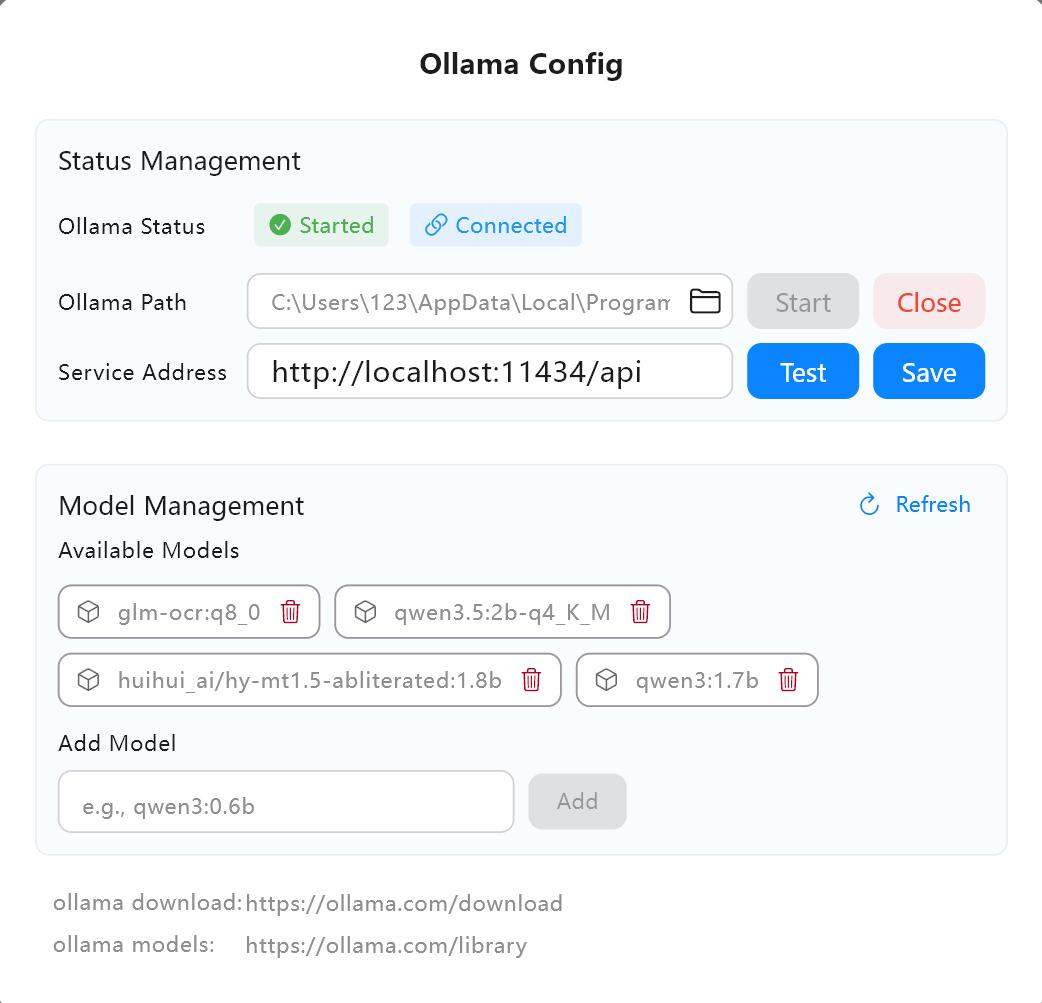 Interface de configuration des services d'IA
Interface de configuration des services d'IA
2. Quatre types de tâches
- Traduction : Traduit les résultats de reconnaissance dans d'autres langues. Vous pouvez spécifier la langue source et la langue cible.
- Correction : Corrige les fautes de frappe et les erreurs grammaticales, et optimise la structure des phrases pour une meilleure fluidité.
- Résumé : Génère des comptes-rendus de réunion ou des résumés de contenu.
- Personnalisé : Utilisez des modèles de prompts personnalisés pour traiter les résultats selon vos besoins (ex: extraction de points d'action, génération de listes de tâches, etc.).
3. Trois modes d'entrée
- Individuel : Traite les segments un par un. C'est le seul mode disponible lors de l'utilisation de l'IA pendant la transcription en temps réel.
- Lot : Combine plusieurs résultats et les envoie ensemble au modèle pour une meilleure efficacité. La taille du lot est personnalisable.
- Texte complet : Envoie tous les résultats de reconnaissance comme un texte complet en une seule fois. Idéal pour générer des résumés de réunion ou des traductions intégrales.
4. IA en temps réel vs. IA hors ligne
- IA en temps réel : Pendant le processus de transcription en temps réel, chaque segment reconnu est automatiquement envoyé au modèle pour traitement et les résultats s'affichent de manière synchrone. Nécessite de démarrer d'abord la tâche IA dans la barre latérale. Seul le mode « Individuel » est supporté.
- IA hors ligne : Traite les résultats de transcription terminés sur la page des détails de l'historique. Supporte les modes « Individuel », « Lot » et « Texte complet ».
5. Paramètres de modèle personnalisés
Configuration intégrée pour les paramètres courants des LLM (ex: temperature, top_p). Les utilisateurs avancés peuvent activer le panneau des paramètres du modèle pour un réglage fin ou passer des paramètres personnalisés au format JSON.
6. Foire aux questions (FAQ)
- Q : Impossible de se connecter à Ollama ?
A : Vérifiez si Ollama est en cours d'exécution et si l'adresse du service est correcte (par défaut :http://localhost:11434/api). - Q : Vitesse de sortie lente ?
A : Passez à un modèle avec moins de paramètres (ex: 1.5B ou 4B), ou changez le mode d'entrée de « Texte complet » à « Individuel ». - Q : Le mode temps réel indique « Veuillez d'abord cliquer sur le bouton bleu » ?
A : Les tâches IA en temps réel nécessitent que le moteur IA soit démarré en cliquant d'abord sur le bouton bleu dans la barre latérale.
7. Modèles recommandés
- Tâches de traduction : Recommandé HY-MT1.5-1.8B — un modèle de traduction professionnel supportant plusieurs langues avec une vitesse d'inférence très rapide.
- Tâches générales : Recommandé séries Qwen3 (ex: 4B ou 8B), disposant d'une excellente capacité de compréhension.