Prise en main
Owl Meeting est un outil de productivité vocale Windows qui fonctionne à 100 % localement. Tout le traitement de reconnaissance vocale et d'IA est effectué sur votre ordinateur sans avoir besoin d'une connexion Internet, et les données ne sont jamais exportées. En suivant ce guide, vous pourrez réaliser votre première transcription en quelques minutes.
1. Installation et configuration système requise
- Source d'installation : Recherchez "Owl Meeting" sur le Microsoft Store pour l'installer et profiter des mises à jour automatiques.
- Dépendance logicielle : Le moteur de reconnaissance vocale nécessite le support de Visual C++ Redistributable. Si une invite apparaît lors du premier lancement, veuillez le télécharger et l'installer comme guidé, puis redémarrer le logiciel.
- Configuration requise : Windows 10/11, architecture x64. Aucun GPU dédié n'est requis ; le processeur d'un ordinateur de bureau ordinaire est suffisant pour un fonctionnement fluide.
2. Téléchargement des [Models]
Après le premier lancement, vous devez télécharger les [Models] d'IA dans la page [Settings] → Gestion des [Models]. Une fois le téléchargement terminé, le logiciel peut fonctionner entièrement [Offline] :
![Interface de gestion et de téléchargement des [Models] loading=](../images/1.jpg) Interface de gestion et de téléchargement des [Models]
Interface de gestion et de téléchargement des [Models]
| Modèle | Description de la fonction | Vitesse |
|---|---|---|
| Modèle 1 (Recommandé) | Prend en charge le chinois, l'anglais, le japonais et le coréen. Extrêmement rapide, convient à la plupart des scénarios. Préféré pour les nouveaux utilisateurs. | Vitesse Extrême |
| Modèle 2 | Spécialisé dans la reconnaissance des dialectes chinois. Doit être utilisé avec le modèle de ponctuation. | Normale |
| Modèle 3 | Prend en charge l'anglais et 26 langues européennes (italien, espagnol, allemand, français, etc.). | Vitesse Extrême |
| Modèle 4 | Couverture la plus large : mandarin, dialectes chinois, anglais, japonais, coréen, russe, français, allemand, arabe, etc., plus de 30 langues. | Normale |
| Modèle de ponctuation | Prend en charge le complètement de la ponctuation en chinois et en anglais. Peut être activé pour corriger les problèmes de ponctuation dans les résultats. |
3. Lancez rapidement votre première transcription
Owl Meeting propose deux modes de travail principaux :
Transcription en temps réel (mode [Online])
Convient aux réunions en cours, aux conférences ou aux appels vidéo :
- Cliquez sur [Online] pour accéder à l'interface de transcription en temps réel.
- Sélectionnez la source sonore : Microphone (réunions en face à face), Son système (webcasts/vidéos) ou mode double canal (Tencent Meeting/Zoom, etc.).
- Sélectionnez le modèle de reconnaissance ; le Modèle 1 est recommandé pour les nouveaux utilisateurs.
- Cliquez sur [Start Recording], et le texte s'affichera à l'écran en temps réel.
Pour des [Settings] détaillés et des fonctionnalités avancées, veuillez vous référer à la documentation de la Transcription en temps réel.
Transcription de fichiers (mode [Offline])
Convient au traitement de fichiers audio ou vidéo existants :
- Cliquez sur [Offline] pour accéder à l'interface de transcription de fichiers.
- Faites glisser des fichiers audio/vidéo dans la fenêtre ou cliquez sur "Sélectionner un fichier". Prend en charge MP3, WAV, M4A, MP4, MKV et d'autres formats courants.
- Sélectionnez le modèle et la méthode de segmentation à droite. Modèle 1 + Segmentation par intervalle de temps est recommandé.
- Cliquez sur [Start Recognition] ; la progression s'affichera en temps réel.
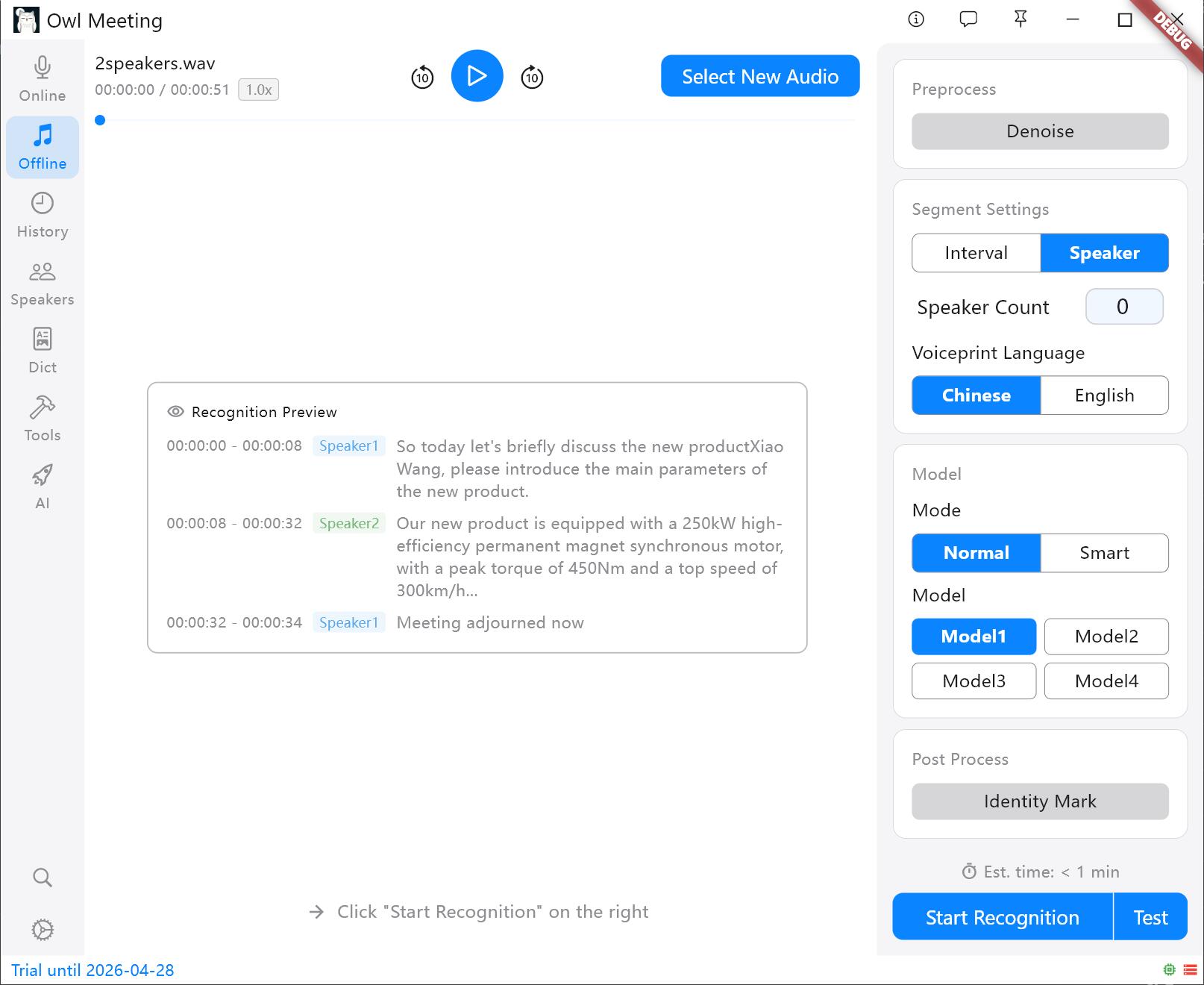 Interface de transcription de fichiers
Interface de transcription de fichiers
Pour des [Settings] détaillés et des fonctionnalités avancées, veuillez vous référer à la documentation de la Transcription de fichiers.
4. Configuration recommandée pour les nouveaux utilisateurs
Si vous êtes un nouvel utilisateur, la configuration suivante peut vous aider à démarrer rapidement :
- Modèle de reconnaissance : Modèle 1 (Rapide, bonne performance générale)
- Méthode de segmentation : Intervalle de temps (auto-segmentation VAD)
- Mode de reconnaissance : Mode régulier
- Réduction de bruit : Désactivé pour un audio clair, activé pour les environnements bruyants
Les fonctionnalités avancées telles que la séparation des locuteurs, la Reconnaissance de locuteurs, le Dictionnaire personnalisé et l'Assistant IA peuvent être utilisées plus tard pour optimiser progressivement les effets.