Marquage vocal et gestion des locuteurs
La bibliothèque d'empreintes vocales est la fonction centrale d'Owl Meeting pour « savoir qui parle ». En pré-enregistrant des échantillons de voix pour chaque personne, le système peut identifier et marquer automatiquement le nom du locuteur lors de la transcription des fichiers, et même spécifier le modèle de reconnaissance le plus approprié pour chaque individu.
1. Ajouter un locuteur
- Accédez à [Speakers] dans la barre d'outils de gauche.
- Cliquez sur [Add Speaker], renseignez le nom (obligatoire) et des remarques (facultatif).
- Attribuez un modèle de reconnaissance pour le locuteur : lorsque le [Smart] dans Transcription de fichiers est activé, le système utilisera automatiquement le modèle spécifié ici pour reconnaître la voix du locuteur.
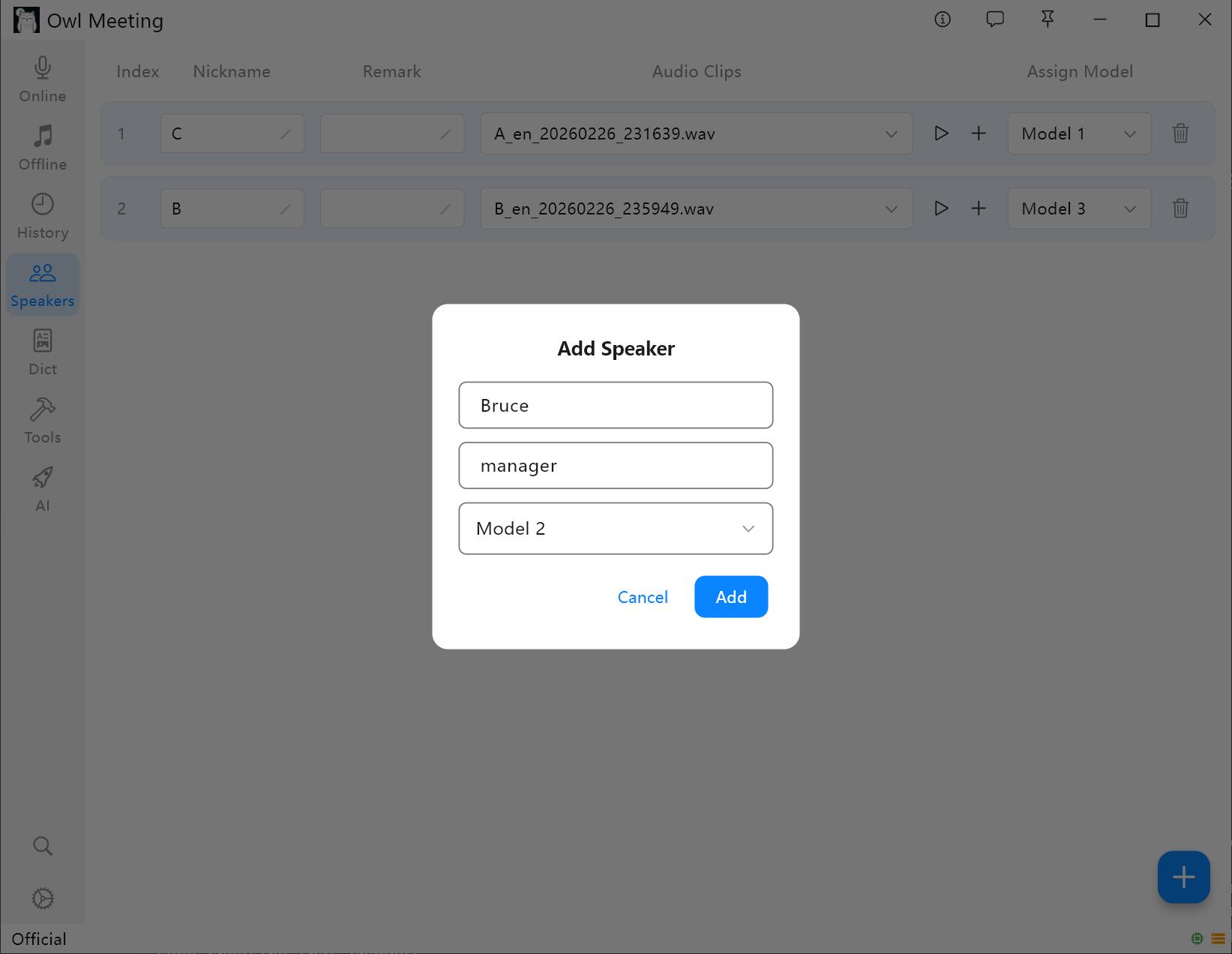 Interface de gestion de la bibliothèque d'empreintes vocales
Interface de gestion de la bibliothèque d'empreintes vocales
2. Ajouter des échantillons d'empreintes vocales
- Sélectionnez un locuteur et cliquez sur [Add Audio].
- Sélectionnez un fichier audio contenant une voix humaine claire du locuteur.
- Définissez l'heure de début/fin dans la fenêtre de rognage, et cliquez sur lecture pour confirmer.
- Sélectionnez [Voiceprint Language] : sélectionnez « Chinois » pour les échantillons chinois et « Anglais » pour les échantillons anglais. Les autres langues peuvent être sélectionnées en fonction de la famille linguistique.
- Cliquez sur enregistrer, le système extraira automatiquement les caractéristiques de l'empreinte vocale et les associera au locuteur.
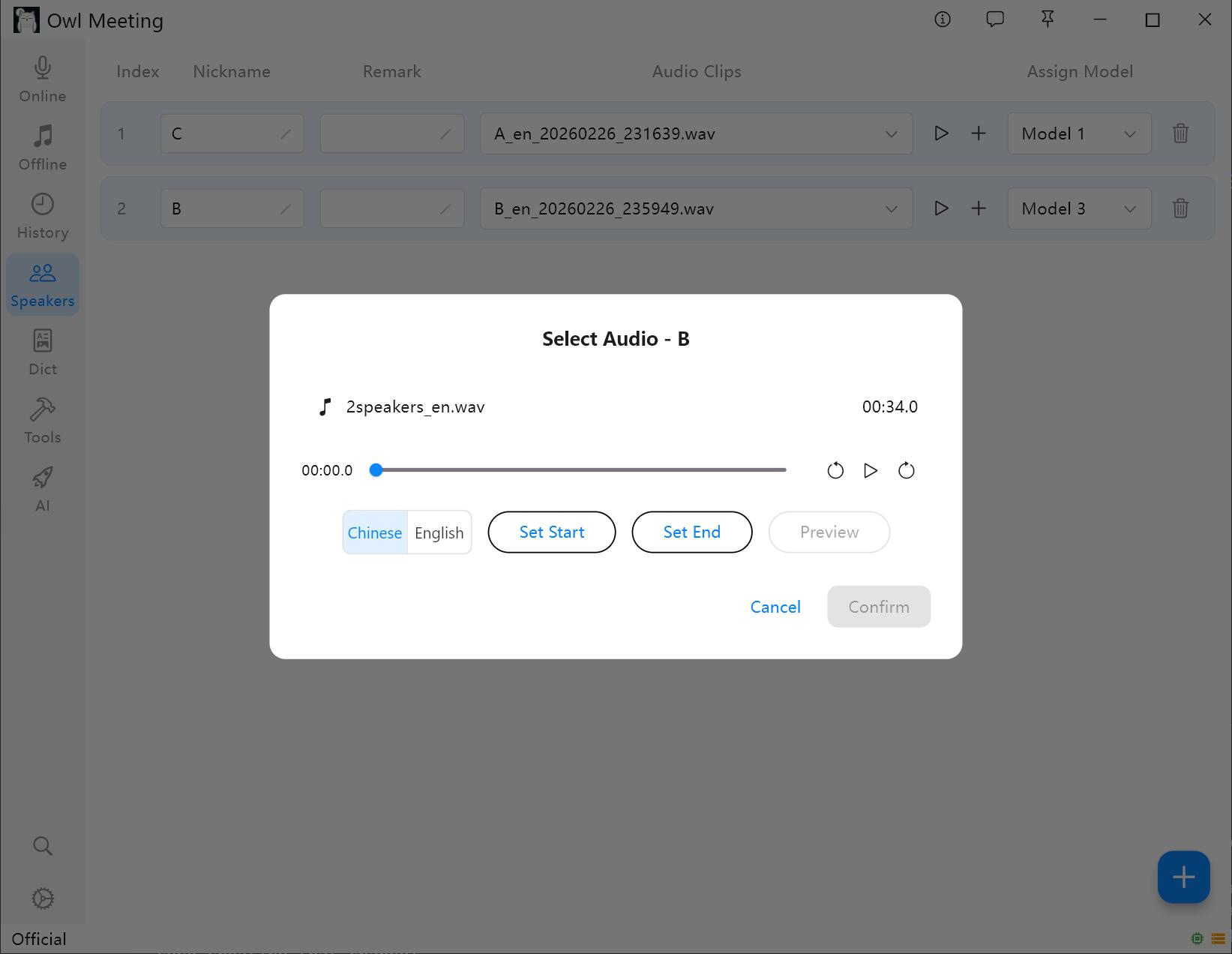 Ajout et rognage d'échantillons d'empreintes vocales
Ajout et rognage d'échantillons d'empreintes vocales
Meilleures pratiques pour la collecte d'échantillons
- Qualité audio : choisissez des clips avec un arrière-plan calme et seulement la voix du locuteur cible, et évitez les segments où plusieurs personnes parlent en même temps.
- Recommandation de durée : chaque segment d'échantillon doit durer de 5 à 30 secondes. Les caractéristiques sont insuffisantes s'il est trop court, et il n'y a aucun avantage supplémentaire s'il est trop long.
- Échantillons multiples : un locuteur peut avoir plusieurs échantillons ajoutés. Si la même personne présente une grande différence de timbre dans différents scénarios (comme en face à face/au téléphone), ajouter plusieurs échantillons provenant de différents scénarios peut améliorer le taux de reconnaissance.
- Correspondance linguistique : la langue sélectionnée lors de l'ajout des échantillons doit être cohérente avec la [Voiceprint Language] dans les paramètres de transcription de fichiers ; sinon, la correspondance échouera complètement. Les espaces de caractéristiques des modèles d'empreintes vocales chinois et anglais sont incompatibles entre eux.
3. Maintenance quotidienne
- Modifiez le nom, les remarques et le modèle spécifié du locuteur à tout moment.
- Basculez entre la visualisation de différents échantillons et écoutez-les directement.
- Lors de la suppression d'un échantillon, le fichier audio local correspondant sera nettoyé en même temps.
4. Comment la bibliothèque d'empreintes vocales prend effet dans la transcription
La bibliothèque d'empreintes vocales joue principalement un rôle dans la Transcription de fichiers hors ligne. Pour que les résultats de la transcription affichent automatiquement le nom du locuteur, les conditions suivantes doivent être remplies simultanément :
- Sélectionnez [Speaker] comme méthode de segmentation.
- Activez l'interrupteur [Identity Mark].
- La [Voiceprint Language] dans les paramètres de transcription de fichiers est cohérente avec la langue choisie lors de l'ajout des échantillons.
Une fois ces conditions remplies, l'étiquette du locuteur dans le résultat de reconnaissance sera automatiquement remplacée par le vrai nom saisi dans la bibliothèque d'empreintes vocales.
5. FAQ et dépannage
- Q : Pourquoi les résultats de reconnaissance n'affichent-ils que Speaker_0, Speaker_1 et aucun nom ?
R : Veuillez vérifier les trois éléments de « Comment la bibliothèque d'empreintes vocales prend effet dans la transcription » un par un. La raison la plus courante est l'oubli de l'activation du [Identity Mark] ou une incohérence de la langue de l'empreinte vocale. - Q : Les noms sont marqués, mais ils sont incorrectement attribués aux mauvaises personnes ?
R : Essayez d'augmenter le [Identity Threshold] (dans la zone « Diarisation du locuteur et marquage » des paramètres de transcription de fichiers), ou ajoutez à nouveau des échantillons d'empreintes vocales plus clairs pour le locuteur correspondant. - Q : Le nombre de personnes reconnues automatiquement est incorrect ?
R : Il est recommandé de spécifier manuellement le « Nombre de locuteurs » dans les paramètres. Si vous utilisez le mode automatique, vous pouvez affiner le [Cluster Threshold] pour contrôler la sensibilité du système aux différences sonores.