🎞️ Transcription de fichiers audio et vidéo
Le mode de transcription audio et vidéo (mode hors ligne) est conçu spécifiquement pour le traitement des fichiers audio et vidéo existants. Tout le traitement est effectué localement, garantissant ainsi votre secret professionnel et la sécurité de vos données.
🚀 Démarrage rapide
- Importer des fichiers : Faites glisser les fichiers audio/vidéo directement dans la fenêtre du logiciel, ou cliquez sur « Sélectionner un fichier » au centre.
- Sélectionner le mode et le modèle : Choisissez le mode de traitement requis à droite de l'interface.
- Démarrer immédiatement : Cliquez sur le bouton de démarrage en bas. Vous pouvez voir la progression du traitement en temps réel (Initialisation -> Prétraitement -> Segmentation -> Reconnaissance).
1. Formats audio et prétraitement
Owl Meeting possède une forte compatibilité de fichiers, mais comprendre les détails suivants avant de commencer peut améliorer considérablement la précision :
- Formats pris en charge : Prise en charge native de MP3, WAV, M4A, MP4, MKV, MOV, FLAC et de presque tous les autres formats audio/vidéo majeurs.
- Amélioration par réduction du bruit : Si votre enregistrement comporte un bruit de fond important, il est recommandé d'activer l' « Amélioration par réduction du bruit » sur le panneau de droite. Une fois le traitement terminé, vous pouvez basculer librement entre le son original et le son amélioré dans le lecteur pour tester l'effet.
- Recommandation de canal : Pour les fichiers vidéo multicanal, il est recommandé d'utiliser les outils intégrés pour extraire/convertir d'abord en audio mono afin d'obtenir une expérience de reconnaissance plus précise.
 Glisser-déposer de fichiers et formats pris en charge
Glisser-déposer de fichiers et formats pris en charge
2. Mode de reconnaissance et segmentation
Vous pouvez combiner de manière flexible les stratégies de reconnaissance en fonction de la complexité du contenu du fichier :
- Mode régulier : L'intégralité du fichier utilise le même modèle de reconnaissance vocale pour la transcription. Simple et direct, la vitesse la plus rapide.
- Smart : Utilisé conjointement avec l' identification des locuteurs. Vous pouvez attribuer des modèles exclusifs à différents locuteurs identifiés (par exemple, attribuer le modèle 1 au locuteur A et le modèle 2 au locuteur B).
- Stratégie de segmentation :
- Intervalle de temps (VAD) : Segmente automatiquement en fonction des pauses vocales, convient aux déclarations personnelles et aux podcasts.
- Séparation des locuteurs : Coupe automatiquement en fonction des caractéristiques vocales. Conseil : Vous devez spécifier un modèle d'empreinte vocale (chinois/anglais) avant de commencer ; d'autres langues peuvent être sélectionnées en fonction de leur famille linguistique.
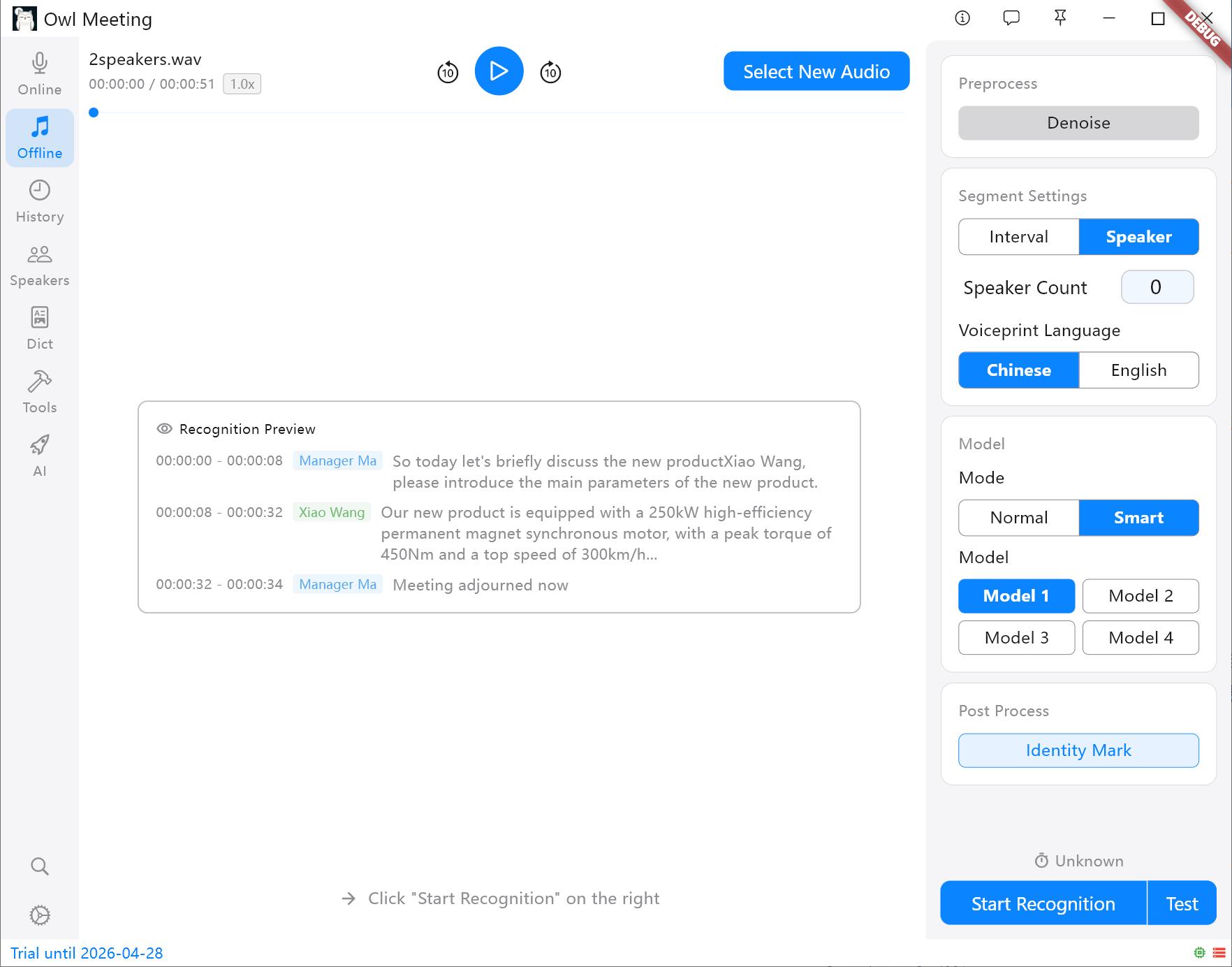 Méthodes de segmentation et panneau de configuration
Méthodes de segmentation et panneau de configuration
3. Mode test
Aperçu de l'effet de reconnaissance des réglages.
- Mode test : Avant de traiter un audio très long, vous pouvez utiliser la fonction de test pour vérifier si les paramètres actuels répondent aux attentes (elle utilisera les paramètres actuels pour sélectionner au hasard trois minutes d'audio pour la reconnaissance).
4. Réglages exclusifs et ajustement fin
Sur le panneau de réglage hors ligne, les paramètres de segmentation VAD (seuil de détection vocale, temps de silence/parole min/parole max, remplissage des bords) sont les mêmes que pour la reconnaissance en temps réel. Pour plus de détails, consultez la documentation de Transcription en temps réel. Voici les paramètres de configuration exclusifs à la transcription de fichiers :
Séparation et marquage des locuteurs
Lorsque la méthode de segmentation est réglée sur [Speaker], les paramètres suivants déterminent la qualité de la séparation :
- Nombre de locuteurs : Si vous savez précisément combien de personnes parlent dans l'audio, spécifiez directement le nombre exact (1~10) pour obtenir le meilleur effet. Si vous réglez sur « Auto », le seuil de regroupement déterminera le nombre de personnes.
- Cluster Threshold (uniquement efficace en mode « Auto ») : Contrôle la sensibilité du système aux différences sonores. Plus la valeur est basse, plus il est facile de séparer différents timbres en différentes personnes (une personne peut être divisée en deux) ; plus la valeur est élevée, plus il est facile de regrouper les timbres similaires comme étant la même personne (deux personnes peuvent être fusionnées).
- Temps de parole min : Les segments de parole plus courts que cette durée seront rejetés, filtrant les bruits très courts tels que la toux ou les interjections.
- Intervalle de fusion max : Les segments adjacents du même locuteur dont l'intervalle de temps est inférieur à cette valeur seront automatiquement fusionnés pour réduire la segmentation fragmentée.
- Identity Mark : Lorsqu'il est activé, le système comparera les locuteurs identifiés avec ceux déjà saisis dans la bibliothèque d'empreintes vocales et étiquettera automatiquement leurs noms réels. C'est également une condition préalable à l'utilisation du [Smart].
- Langue d'empreinte vocale : Sélectionnez « Chinois » pour les scénarios chinois et « Anglais » pour les scénarios anglais. Remarque : Les espaces de caractéristiques des modèles d'empreintes vocales chinois et anglais sont incompatibles ; choisir la mauvaise langue entraînera l'échec total de la correspondance. Les autres langues doivent être testées en fonction de leur famille linguistique.
- Identity Threshold (nécessite le Marquage d'identité) : L'identité n'est déterminée que lorsque le résultat de la comparaison de l'empreinte vocale est supérieur à cette valeur. Il ne doit pas être réglé trop haut, sinon les personnes connues pourraient ne pas être reconnues.
Configuration avancée de la segmentation
- Fusion intelligente : Fusionne automatiquement les phrases courtes en fonction de l'intervalle de temps entre les segments adjacents, ce qui réduit les segments fragmentés et aide à améliorer la précision globale de la reconnaissance.
- Intervalle de fusion : La fusion est déclenchée lorsque l'intervalle entre deux segments est inférieur à cette valeur (secondes).
Configuration spécifique au modèle
- Modèle 1 version quantifiée : Lorsqu'elle est activée, la vitesse d'inférence est légèrement plus rapide, mais la précision est légèrement réduite, ce qui a peu d'impact sur la plupart des scénarios.
- Modèle 1 langue : En général, « Auto » convient ; spécifier manuellement la langue (chinois/anglais/japonais/coréen) lorsqu'elle est clairement connue peut améliorer la qualité de la sortie.
- Modèle 1 ponctuation intégrée + texte en chiffre : Active la ponctuation et la conversion de chiffres intégrées du modèle, par exemple en affichant « cinquante kilomètres » comme « 50 kilomètres ».
Services système
- Texte en chiffre : Uniquement pris en charge pour le chinois, convertissant les nombres parlés au format standard.
- Ponctuation (chinois, anglais) : Si la ponctuation dans les résultats de reconnaissance est anormale (par exemple, si après l'activation de la Fusion intelligente une grande quantité de points apparaît), cet élément peut être activé pour la réparation de la ponctuation (les modèles de ponctuation doivent d'abord être téléchargés dans « Gestion des modèles »).
5. Pos-traitement plus efficace
Une fois la reconnaissance terminée, vous pouvez utiliser des outils intégrés pour générer directement des transcriptions de haute qualité :
- Conversion Simplifié/Traditionnel : Conversion en un clic entre le chinois simplifié et le chinois traditionnel (prend en charge la correspondance pour le chinois traditionnel de Taïwan et de Hong Kong).
- Déduplication de contenu : Supprime automatiquement les mots répétés causés par le chevauchement audio ou les hallucinations du modèle.
- Remplacement de termes professionnels : Utilisez la fonction « Dictionnaire professionnel » pour corriger en un clic les termes professionnels ou les initiales de noms dans le texte.
6. Performances extrêmes
Grâce au moteur d'inférence local profondément optimisé, Owl Meeting peut atteindre des vitesses extrêmes même sur le processeur d'un ordinateur de bureau ordinaire :
- Ordinateurs d'entrée de gamme/anciens (par exemple i5-4210m) : Un fichier audio de 30 minutes peut être traité en environ 3 minutes.
- Ordinateurs domestiques/de bureau grand public (par exemple i5-11400H) : Un fichier audio de 30 minutes ne prend généralement qu'environ 1 minute.
7. FAQ et astuces
- Q : Pourquoi la documentation insiste-t-elle à plusieurs reprises sur la conversion du multicanal en mono ?
R : Les enregistrements multicanaux (stéréo) sont sujets aux interférences d'écho dans les environnements complexes. Après la conversion en mono, l'extraction des caractéristiques de l'empreinte vocale par le moteur d'IA sera plus pure, ce qui peut améliorer considérablement la précision de la séparation des locuteurs. - Q : Les locuteurs identifiés sont devenus Speaker_0, Speaker_1... ?
R : Ce sont des identifiants temporaires attribués par le système. Vous pouvez cliquer directement sur ces identifiants sur la page des résultats pour le renommage global. Le système les enregistrera automatiquement et ils prendront effet dans les fichiers SRT ou TXT exportés ultérieurement. - Q : Je souhaite que le texte reconnu soit directement converti en chinois traditionnel ?
A : Une fois la reconnaissance terminée, cliquez sur le bouton « Conversion Simplifié/Traditionnel » ci-dessous et sélectionnez le code régional correspondant (comme « Chinois traditionnel » ou « Taïwan Traditionnel ») pour convertir l'intégralité du texte en un seul clic.