🤖 Integracja asystenta AI
Wykorzystaj modele wdrożone w Ollama do przetwarzania wyników rozpoznawania. Możesz używać niestandardowych szablonów.
1. Konfiguracja usługi AI
Lokalna Ollama (zalecana, w pełni offline)
- Odwiedź ollama.com/download, aby pobrać i zainstalować Ollama.
- Sprawdź adres usługi w ustawieniach AI Owl Meeting (domyślnie
http://localhost:11434/api). - Kliknij "Testuj", aby potwierdzić, że połączenie jest prawidłowe.
- Wyszukaj i pobierz wymagany model (np.
qwen3:4b) w bibliotece modeli Ollama.
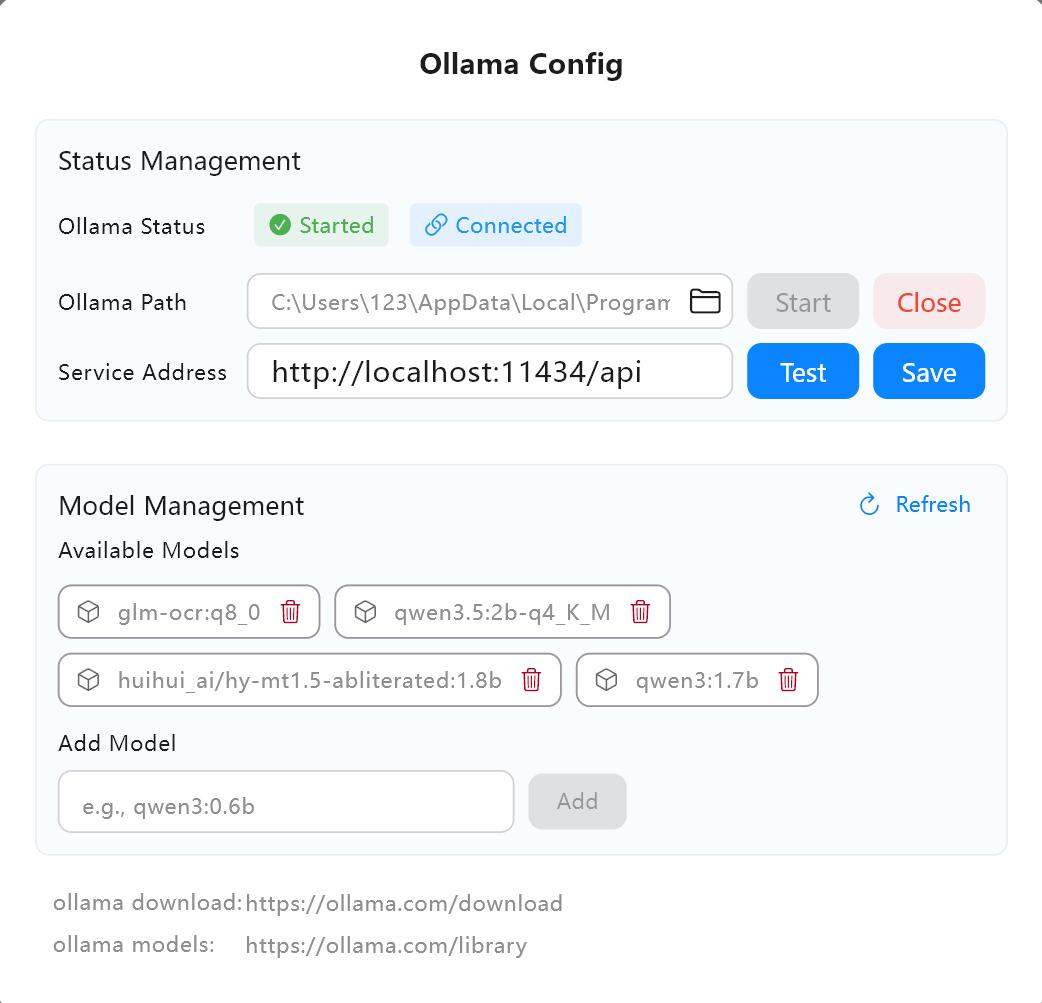 Interfejs konfiguracji usługi AI
Interfejs konfiguracji usługi AI
2. Cztery rodzaje zadań
- Tłumaczenie: Tłumaczenie wyników rozpoznawania na inne języki. Możesz określić język źródłowy i docelowy.
- Korekta: Poprawia literówki i błędy gramatyczne oraz optymalizuje strukturę zdań dla lepszej płynności.
- Podsumowanie: Generuje protokoły ze spotkań lub podsumowania treści.
- Niestandardowe: Używaj niestandardowych szablonów promptów, aby przetwarzać wyniki zgodnie ze swoimi potrzebami (np. wyodrębnianie zadań do wykonania, generowanie list To-do itp.).
3. Trzy tryby wprowadzania
- Pojedynczy: Przetwarza segmenty jeden po drugim. Jest to jedyny tryb dostępny podczas korzystania z AI w trakcie transkrypcji na żywo.
- Seryjny: Łączy wiele wyników i wysyła je do modelu razem w celu zwiększenia wydajności. Rozmiar serii można dostosować.
- Pełny tekst: Wysyła wszystkie wyniki rozpoznawania jako kompletny tekst za jednym razem. Idealny do generowania podsumowań spotkań lub pełnych tłumaczeń tekstu.
4. AI w czasie rzeczywistym a AI offline
- AI w czasie rzeczywistym: Podczas procesu transkrypcji na żywo każdy rozpoznany segment jest automatycznie wysyłany do modelu w celu przetworzenia i wyświetlany synchronicznie. Wymaga uprzedniego uruchomienia zadania AI na pasku bocznym. Obsługiwany jest tylko tryb „Pojedynczy”.
- AI offline: Przetwarza zakończone wyniki transkrypcji na stronie szczegółów historii. Obsługuje tryby „Pojedynczy”, „Seryjny” i „Pełny tekst”.
5. Niestandardowe parametry modelu
Wbudowana konfiguracja typowych parametrów LLM (np. temperatura, top_p). Zaawansowani użytkownicy mogą włączyć panel parametrów modelu w celu dokładnego dostrojenia lub przekazać niestandardowe parametry w formacie JSON.
6. Często zadawane pytania (FAQ)
- Q: Nie można połączyć się z Ollama?
A: Sprawdź, czy Ollama jest uruchomiona i czy adres usługi jest poprawny (domyślnie:http://localhost:11434/api). - Q: Niska prędkość generowania?
A: Przełącz się na model o mniejszej liczbie parametrów (np. 1.5B lub 4B) lub zmień tryb wprowadzania z „Pełny tekst” na „Pojedynczy”. - Q: Tryb rzeczywisty wyświetla komunikat „Najpierw kliknij niebieski przycisk”?
A: Zadania AI w czasie rzeczywistym wymagają uruchomienia silnika AI poprzez kliknięcie niebieskiego przycisku na pasku bocznym.
7. Polecane modele
- Zadania tłumaczeniowe: Polecany HY-MT1.5-1.8B — profesjonalny model tłumaczeniowy obsługujący wiele języków z bardzo szybkim czasem odpowiedzi.
- Zadania ogólne: Polecana seria Qwen (np. 4B lub 8B), posiadająca doskonałe zdolności rozumienia tekstu.