🎞️ Transkrypcja plików audio i wideo
Tryb transkrypcji audio i wideo (tryb offline) został zaprojektowany specjalnie do przetwarzania istniejących plików audio i wideo. Proces odbywa się w całości lokalnie, co gwarantuje zachowanie tajemnicy handlowej i bezpieczeństwo danych.
🚀 Szybki start
- Importuj pliki: Przeciągnij pliki audio/wideo bezpośrednio do okna oprogramowania lub kliknij „Wybierz plik” na środku.
- Wybierz tryb i model: Wybierz wymaganą metodę przetwarzania po prawej stronie interfejsu.
- Rozpocznij natychmiast: Kliknij przycisk „Start” poniżej. Możesz obserwować postęp przetwarzania w czasie rzeczywistym (Inicjalizacja -> Przetwarzanie wstępne -> Segmentacja -> Rozpoznawanie).
1. Formaty audio i przetwarzanie wstępne
Owl Meeting posiada silną kompatybilność z plikami, ale zrozumienie poniższych szczegółów przed rozpoczęciem może znacznie poprawić dokładność:
- Obsługa formatów: Natywna obsługa MP3, WAV, M4A, MP4, MKV, MOV, FLAC i prawie wszystkich innych głównych formatów audio/wideo.
- Wzmocnienie redukcji szumów: Jeśli nagranie zawiera znaczne szumy tła, zaleca się włączenie opcji „Wzmocnienie redukcji szumów” w prawym panelu. Po zakończeniu przetwarzania możesz dowolnie przełączać się między dźwiękiem oryginalnym a wzmocnionym w odtwarzaczu, aby sprawdzić efekt.
- Zalecenie dotyczące kanałów: W przypadku wielokanałowych plików wideo zaleca się użycie wbudowanych narzędzi do wcześniejszego wyodrębnienia/konwersji na dźwięk mono, aby uzyskać dokładniejsze rozpoznawanie.
 Przeciąganie plików i obsługa formatów
Przeciąganie plików i obsługa formatów
2. Tryb rozpoznawania i segmentacja
Możesz elastycznie łączyć strategie rozpoznawania w zależności od złożoności treści pliku:
- Tryb zwykły: Cały plik korzysta z tego samego modelu rozpoznawania głosu do transkrypcji. Prosty i bezpośredni, najszybszy.
- Tryb inteligentny: Używany w połączeniu z identyfikacją osób mówiących. Możesz przypisać wyłączne modele do różnych zidentyfikowanych osób (np. przypisać Model 1 Osobie A i Model 2 Osobie B).
- Strategia segmentacji:
- Interwał czasowy (VAD): Automatycznie segmentuje na podstawie pauz w głosie, odpowiedni dla oświadczeń osobistych i podcastów.
- Separacja osób mówiących: Automatycznie tnie na podstawie cech głosu. Wskazówka: Przed rozpoczęciem należy określić model odcisku głosu (chiński/angielski); inne języki można wybrać na podstawie rodziny językowej.
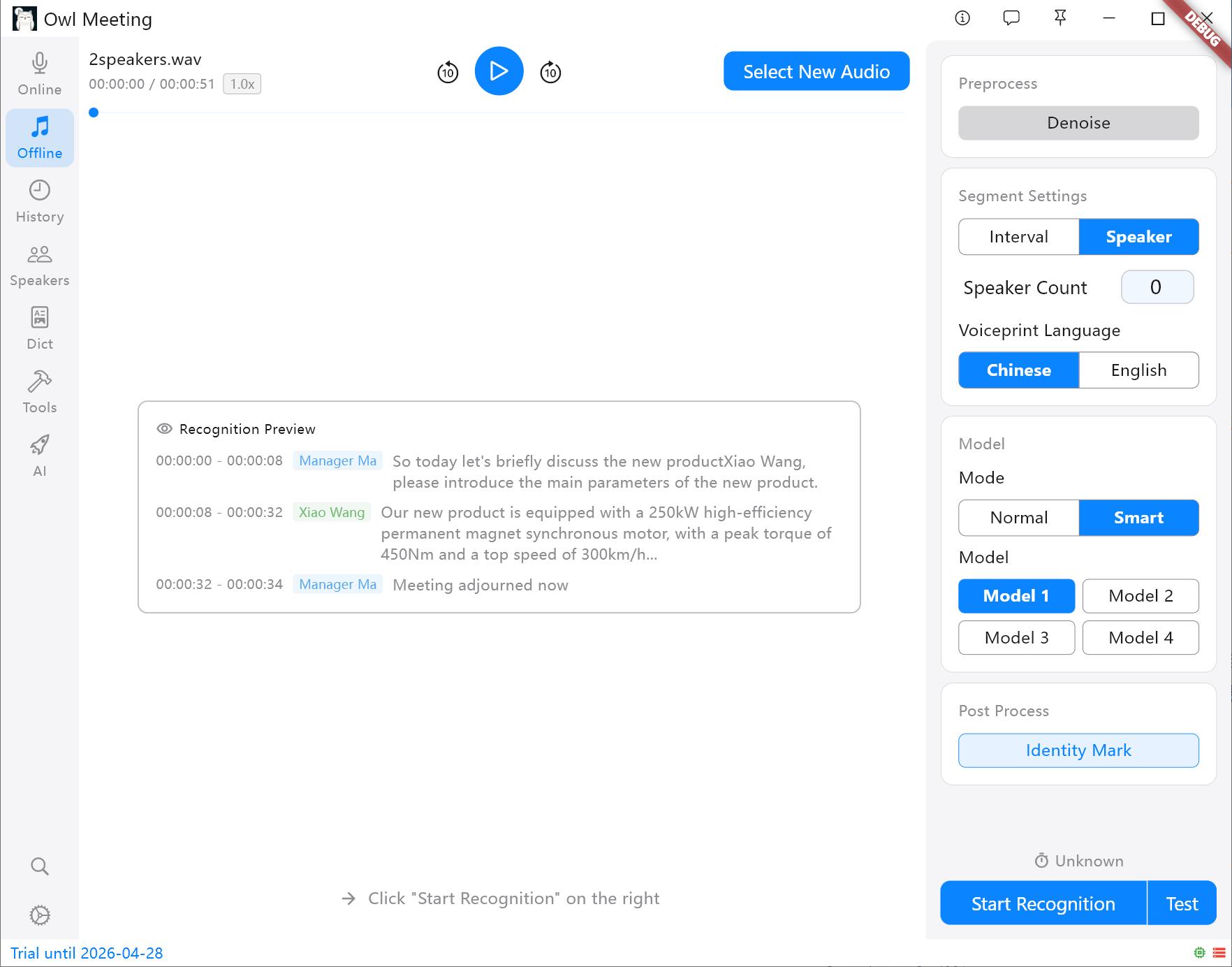 Metody segmentacji i panel ustawień
Metody segmentacji i panel ustawień
3. Tryb testowy
Podgląd efektu rozpoznawania ustawień.
- Tryb testowy: Przed przetwarzaniem bardzo długiego dźwięku możesz użyć funkcji testowej, aby sprawdzić, czy bieżące parametry spełniają oczekiwania (zostaną użyte bieżące parametry do losowego wybrania trzech minut dźwięku do rozpoznania).
4. Wyjątkowe ustawienia i dostrajanie
W panelu ustawień offline parametry segmentacji VAD (Próg wykrywania głosu, Minimalny czas ciszy/mowy/Maksymalny czas mowy, Wypełnienie krawędzi) są takie same jak w rozpoznawaniu w czasie rzeczywistym. Szczegóły znajdują się w dokumentacji Transkrypcja w czasie rzeczywistym. Poniżej znajdują się elementy konfiguracji dostępne wyłącznie dla transkrypcji plików:
Separacja i tagowanie osób mówiących
Gdy metoda segmentacji jest ustawiona na „Osoba mówiąca”, następujące parametry określają jakość separacji:
- Liczba osób mówiących: Jeśli dokładnie wiesz, ile osób mówi w nagraniu, bezpośrednio określ konkretną liczbę (1–10), aby uzyskać najlepszy efekt. Ustawienie tej opcji na „Auto” pozwoli progowi klastrowania określić liczbę osób.
- Próg klastrowania (skuteczny tylko w trybie „Auto”): Kontroluje wrażliwość systemu na różnice w dźwięku. Im niższa wartość, tym łatwiej oddzielić różne barwy głosu jako proces różnym osobom (jedna osoba może zostać podzielona na dwie); im wyższa wartość, tym łatwiej grupować podobne barwy głosu jako tę samą osobę (dwie osoby mogą zostać połączone).
- Minimalny czas mowy: Segmenty mowy krótsze niż ten czas zostaną odrzucone, co pozwoli odfiltrować bardzo krótkie dźwięki, takie jak kaszel lub wykrzykniki.
- Maksymalny interwał łączenia: Sąsiednie segmenty tej samej osoby z interwałem czasowym krótszym niż ta wartość zostaną automatycznie połączone, aby ograniczyć fragmentację segmentacji.
- Tagowanie tożsamości: Po włączeniu system porówna zidentyfikowane osoby z osobami już wprowadzonymi do biblioteki odcisków głosu i automatycznie oznaczy ich prawdziwe nazwiska. Jest to również warunek wstępny korzystania z „Trybu inteligentnego”.
- Język odcisku głosu: Wybierz „chiński” dla scenariuszy chińskich i „angielski” dla scenariuszy angielskich. Uwaga: Przestrzenie cech modeli odcisków głosu chińskiego i angielskiego są niekompatybilne; wybranie niewłaściwego języka spowoduje całkowite niepowodzenie dopasowania. Inne języki należy przetestować na podstawie ich rodzin językowych.
- Próg dopasowania rozpoznawania (wymaga tagowania tożsamości): Tożsamość jest określana tylko wtedy, gdy wynik porównania odcisku głosu jest wyższy niż ta wartość. Nie należy go ustawiać zbyt wysoko, w przeciwnym razie znane osoby mogą nie zostać rozpoznane.
Zaawansowana konfiguracja segmentacji
- Inteligentne łączenie: Automatycznie łączy krótkie zdania na podstawie interwału czasowego między sąsiednimi segmentami, co ogranicza liczbę pofragmentowanych segmentów i pomaga poprawić ogólną dokładność rozpoznawania.
- Interwał łączenia: Łączenie jest wyzwalane, gdy interwał między dwoma segmentami jest mniejszy niż ta wartość (w sekundach).
Konfiguracja specyficzna dla modelu
- Kwantyzowana wersja Modelu 1: Po włączeniu prędkość wnioskowania jest nieco większa, ale dokładność jest nieco niższa, co ma niewielki wpływ na większość scenariuszy.
- Język Modelu 1: Zazwyczaj opcja „Auto” jest wystarczająca; ręczne określenie języka (chiński/angielski/japoński/koreański), gdy jest on wyraźnie znany, może poprawić jakość wyników.
- Wbudowana interpunkcja modelu 1 + Zamiana tekstu na cyfry: Włącza wbudowaną interpunkcję modelu i konwersję liczb, na przykład wyświetlając „pięćdziesiąt kilometrów” jako „50 kilometrów”.
Usługi systemowe
- Zamiana tekstu na cyfry: Obsługiwane tylko dla języka chińskiego, konwertuje liczby mówione na formaty standardowe.
- Interpunkcja (chiński, angielski): Jeśli interpunkcja w wynikach rozpoznawania jest nieprawidłowa (na przykład po włączeniu inteligentnego łączenia pojawia się duża liczba kropek), można włączyć tę opcję w celu naprawy interpunkcji (modele interpunkcji należy najpierw pobrać w sekcji „Zarządzanie modelami”).
5. Wydajniejsze przetwarzanie końcowe
Po zakończeniu rozpoznawania możesz użyć wbudowanych narzędzi do bezpośredniego generowania wysokiej jakości dokumentów:
- Konwersja uproszczony/tradycyjny: Jedno kliknięcie, aby przełączyć się między chińskim uproszczonym a tradycyjnym (z obsługą wariantów z Tajwanu i Hongkongu).
- Usuwanie duplikatów treści: Automatycznie usuwa powtarzające się słowa spowodowane nakładaniem się dźwięku lub halucynacjami modelu.
- Zastępowanie profesjonalnych słów: Skorzystaj z funkcji „Słownik profesjonalny”, aby jednym kliknięciem poprawić terminy techniczne lub inicjały nazwisk w tekście.
6. Najwyższa wydajność
Dzięki głęboko zoptymalizowanemu lokalnemu silnikowi wnioskowania Owl Meeting może osiągać ekstremalne prędkości nawet na procesorze zwykłego komputera biurowego:
- Komputery podstawowe/starsze (np. i5-4210m): 30-minutowy plik audio można przetworzyć w około 3 minuty.
- Główne bilety komputery domowe/biurowe (np. i5-11400H): 30-minutowy plik audio zajmuje zazwyczaj tylko około 1 minuty.
7. FAQ i wskazówki
- P: Dlaczego w dokumentacji wielokrotnie podkreśla się konieczność konwersji dźwięku wielokanałowego na mono?
O: Nagrania wielokanałowe (stereo) są podatne na zakłócenia echem w złożonych środowiskach. Po konwersji na mono wyodrębnianie cech odcisku głosu przez silnik AI będzie czystsze, co może znacznie poprawić dokładność separacji osób mówiących. - P: Czy zidentyfikowane osoby zmieniły się w Speaker_0, Speaker_1...?
O: Są to identyfikatory tymczasowe przypisane przez system. Możesz kliknąć te identyfikatory bezpośrednio na stronie wyników, aby zmienić ich nazwę globalnie. System automatycznie je zarejestruje i będą one obowiązywać w wyeksportowanych później plikach SRT lub TXT. - P: Chcę, aby rozpoznany tekst został bezpośrednio skonwertowany na chiński tradycyjny?
O: Po zakończeniu rozpoznawania kliknij przycisk „Konwersja uproszczony/tradycyjny” poniżej i wybierz odpowiedni kod regionu (np. „chiński tradycyjny” lub „Tajwan”), aby jednym kliknięciem skonwertować cały tekst.