Zarządzanie wzorcami głosu i mówcami
Biblioteka wzorców głosu to kluczowa funkcja aplikacji Owl Meeting pozwalająca „wiedzieć, kto mówi”. Dzięki wcześniejszemu nagraniu próbek głosu każdej osoby, system może automatycznie rozpoznawać i oznaczać nazwisko mówcy podczas transkrypcji plików, a nawet przypisywać najbardziej odpowiedni model rozpoznawania dla różnych osób.
1. Dodawanie mówcy
- Przejdź do „Biblioteki wzorców głosu” na lewym pasku narzędzi.
- Kliknij „Dodaj osobę”, wpisz imię i nazwisko (wymagane) oraz uwagi (opcjonalnie).
- Przypisz model rozpoznawania dla mówcy: po włączeniu „Trybu inteligentnego” w transkrypcji plików, system automatycznie użyje modelu wskazanego w tym miejscu do rozpoznawania głosu mówcy.
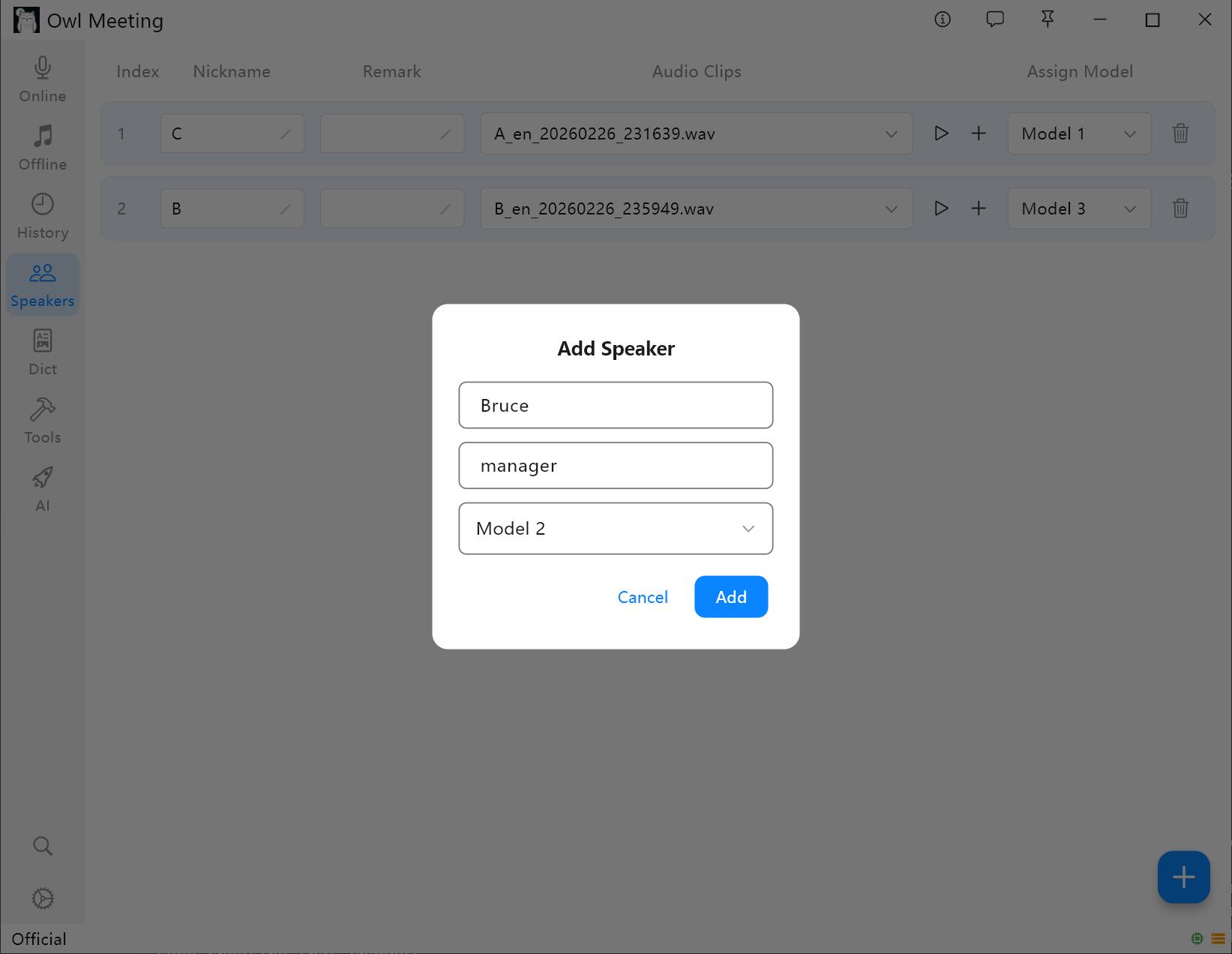 Interfejs zarządzania biblioteką wzorców głosu
Interfejs zarządzania biblioteką wzorców głosu
2. Dodawanie próbek wzorców głosu
- Wybierz mówcę i kliknij „Dodaj audio”.
- Wybierz plik audio zawierający wyraźny ludzki głos wybranego mówcy.
- Ustaw czas rozpoczęcia i zakończenia w oknie przycinania, a następnie kliknij odsłuch, aby potwierdzić.
- Wybierz Język wzorca głosu: wybierz „Chiński” dla próbek chińskich oraz „English” dla próbek angielskich. Inne języki można wybierać na podstawie grup językowych.
- Kliknij zapisz – system automatycznie wyodrębni cechy wzorca głosu i powiąże je z mówcą.
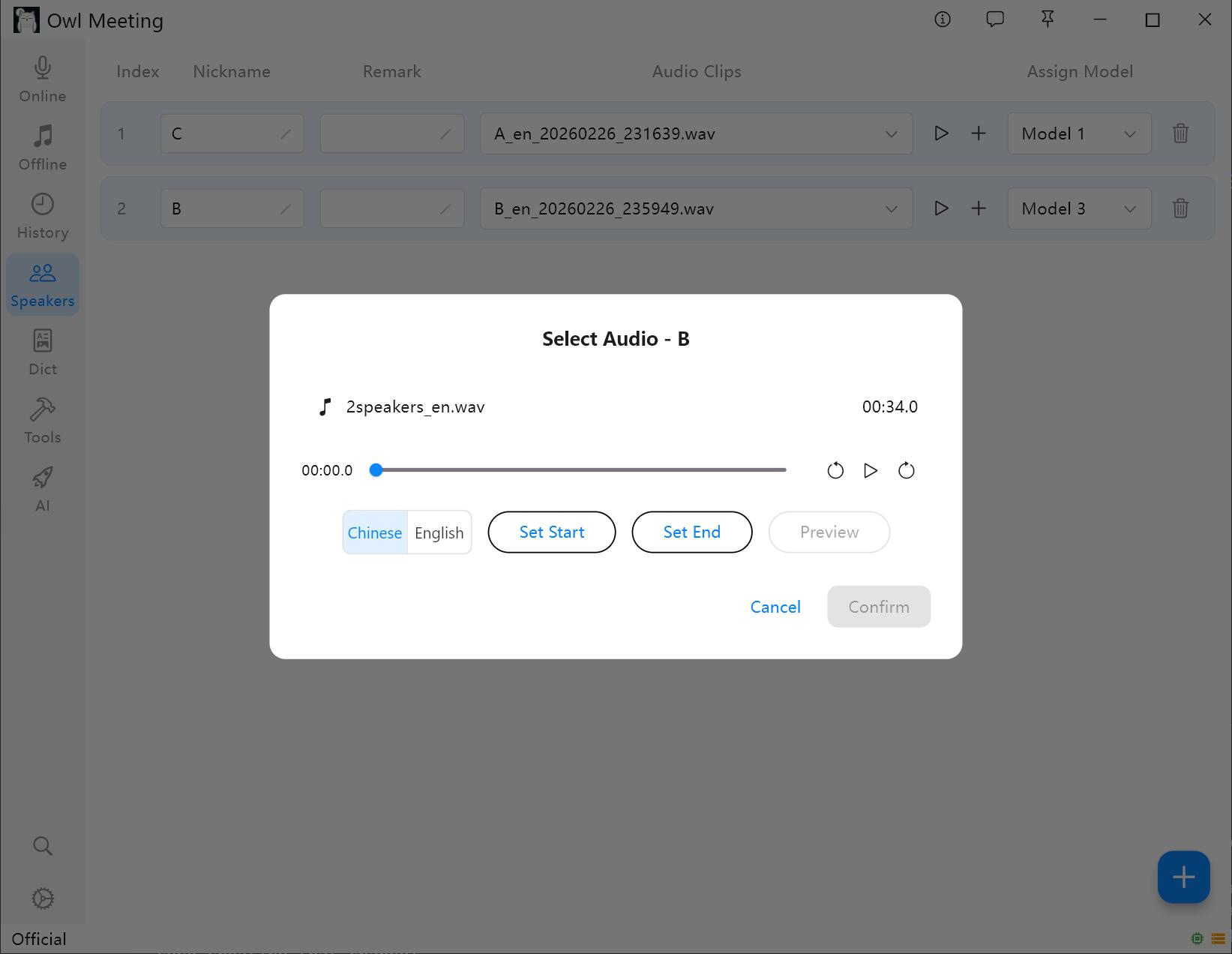 Dodawanie i przycinanie próbek wzorców głosu
Dodawanie i przycinanie próbek wzorców głosu
Najlepsze praktyki przy zbieraniu próbek
- Jakość audio: wybieraj nagrania z cichym tłem i tylko głosem docelowego mówcy; unikaj segmentów, w których kilka osób mówi jednocześnie.
- Zalecany czas trwania: każdy segment próbki powinien trwać od 5 do 30 sekund. Cecha jest niewystarczająca, jeśli jest za krótka, a nie ma dodatkowych korzyści, jeśli jest zbyt długa.
- Wiele próbek: dla jednego mówcy można dodać wiele próbek. Jeśli ta sama osoba wykazuje dużą różnicę w barwie głosu w różnych scenariuszach (np. rozmowa twarzą w twarz / przez telefon), dodanie większej liczby próbek z różnych scenariuszy może poprawić współczynnik rozpoznawania.
- Zgodność języka: język wybrany podczas dodawania próbek musi być zgodny z „Językiem wzorca głosu” w ustawieniach transkrypcji plików; w przeciwnym razie dopasowanie całkowicie zawiedzie. Przestrzenie cech chińskich i angielskich modeli wzorców głosu są ze sobą niekompatybilne.
3. Codzienna konserwacja
- W dowolnym momencie możesz zmienić imię i nazwisko mówcy, uwagi oraz przypisany model.
- Przełączaj się między wyświetlaniem różnych próbek i odsłuchuj je bezpośrednio.
- Podczas usuwania próbki powiązany lokalny plik audio zostanie usunięty w tym samym czasie.
4. Jak wykorzystać wzorce głosu podczas transkrypcji
Biblioteka wzorców głosu odgrywa rolę głównie w transkrypcji plików offline. Aby wyniki transkrypcji automatycznie wyświetlały nazwę mówcy, muszą zostać spełnione jednocześnie następujące warunki:
- Wybierz „Mówcę” jako metodę segmentacji.
- Włącz przełącznik „Oznaczanie tożsamości”.
- „Język wzorca głosu” w ustawieniach transkrypcji plików jest zgodny z językiem wybranym podczas dodawania próbek.
Po spełnieniu powyższych warunków tag mówcy w wyniku rozpoznawania zostanie automatycznie zastąpiony prawdziwym nazwiskiem wprowadzonym do biblioteki wzorców głosu.
5. FAQ i rozwiązywanie problemów
- P: Dlaczego wyniki rozpoznawania pokazują tylko Speaker_0, Speaker_1 zamiast imion i nazwisk?
O: Sprawdź kolejno trzy punkty w sekcji „Jak wykorzystać wzorce głosu podczas transkrypcji”. Najczęstszą przyczyną jest zapomnienie o włączeniu „Oznaczania tożsamości” lub niezgodność języka wzorca głosu. - P: Nazwiska są oznaczone, ale nieprawidłowo przypisane do niewłaściwych osób?
O: Spróbuj zwiększyć „Próg dopasowania rozpoznawania” (w obszarze „Diaryzacja mówców i oznaczanie” w Ustawieniach transkrypcji plików) lub dodaj ponownie wyraźniejsze próbki wzorca głosu dla danego mówcy. - P: Liczba automatycznie rozpoznanych osób jest nieprawidłowa?
O: Zaleca się ręczne określenie „Liczby mówców” w ustawieniach. Jeśli korzystasz z trybu automatycznego, możesz doprecyzować „Próg klasteryzacji”, aby kontrolować wrażliwość systemu na różnice w dźwięku.
Sugestia: dodaj 1-2 wyraźne próbki ludzkiego głosu dla każdego stałego uczestnika podczas tworzenia biblioteki. Po utworzeniu biblioteki wzorców głosu wszystkie kolejne transkrypcje plików będą mogły automatycznie identyfikować tożsamość bez konieczności powtarzania konfiguracji.