🎞️ Транскрипция аудио- и видеофайлов
Режим транскрипции аудио и видео (офлайн-режим) специально разработан для обработки существующих аудио- и видеофайлов. Вся обработка выполняется локально, что гарантирует сохранение вашей коммерческой тайны и безопасности данных.
🚀 Быстрый старт
- Импорт файлов: Перетащите аудио/видеофайлы непосредственно в окно программы или нажмите «[Select File]
- Выбор режима и модели: Выберите необходимый способ обработки в правой части интерфейса.
- Немедленный запуск: Нажмите кнопку запуска внизу. Вы сможете наблюдать за ходом обработки в реальном времени (Инициализация -> Предварительная обработка -> Сегментация -> Распознавание).
1. Аудиоформаты и предварительная обработка
Owl Meeting обладает мощной совместимостью с файлами, но понимание следующих деталей перед началом может значительно повысить точность:
- Поддержка форматов: Нативная поддержка MP3, WAV, M4A, MP4, MKV, MOV, FLAC и почти всех других основных аудио/видеоформатов.
- Улучшение шумоподавления: Если в вашей записи присутствует значительный фоновый шум, рекомендуется включить «Улучшение шумоподавления» на правой панели. После завершения обработки вы можете свободно переключаться между оригинальным и улучшенным звуком в плеере, чтобы проверить эффект.
- Рекомендация по каналам: Для многоканальных видеофайлов рекомендуется использовать встроенные инструменты для предварительного извлечения/конвертации в монофонический звук для получения более точного результата распознавания.
 Перетаскивание файлов и поддержка форматов
Перетаскивание файлов и поддержка форматов
2. Режим распознавания и сегментация
Вы можете гибко комбинировать стратегии распознавания в зависимости от сложности содержимого файла:
- Normal: Для транскрипции всего файла используется одна и та же модель распознавания голоса. Просто и эффективно, самая высокая скорость.
- Smart: Используется в сочетании с идентификацией говорящих. Вы можете назначать эксклюзивные модели для разных идентифицированных говорящих (например, назначить Модель 1 Говорящему А, а Модель 2 — Говорящему Б).
- Стратегия сегментации:
- Временной интервал (VAD): Автоматически сегментирует на основе пауз в голосе, подходит для личных заявлений и подкастов.
- Разделение говорящих: Автоматически нарезает на основе характеристик голоса. Совет: Перед началом необходимо указать модель голосовых отпечатков (китайский/английский); другие языки можно выбрать на основе языковой семьи.
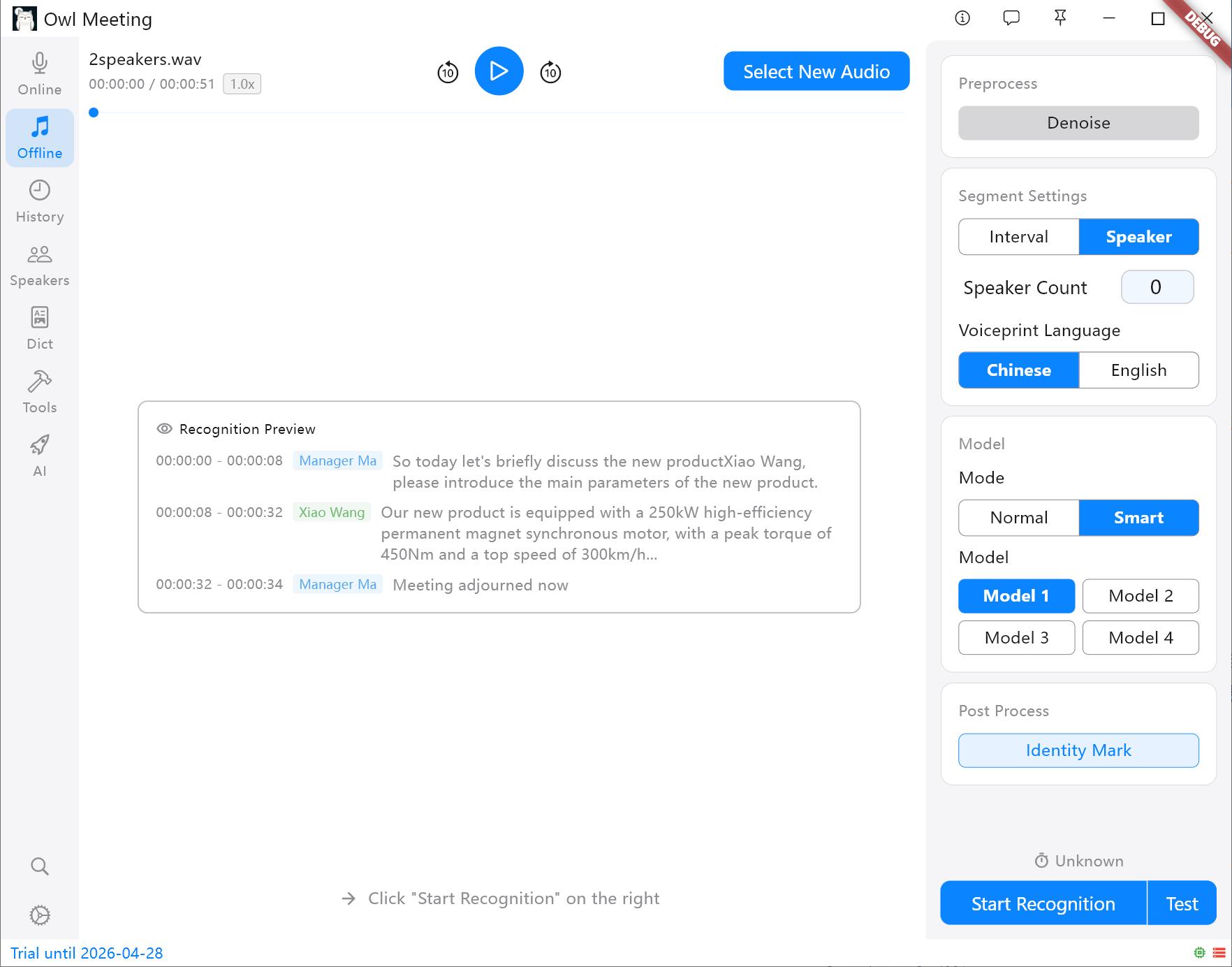 Методы сегментации и панель настроек
Методы сегментации и панель настроек
3. Тестовый режим
Предварительный просмотр эффекта распознавания настроек.
- Тестовый режим: Перед обработкой очень длинного аудио вы можете использовать функцию тестирования, чтобы проверить, соответствуют ли текущие параметры ожиданиям (будет использованы текущие параметры для случайного выбора трех минут аудио для распознавания).
4. Эксклюзивные настройки и тонкая настройка
В панели офлайн-настроек параметры сегментации VAD (порог обнаружения голоса, минимальное время тишины/голоса/максимальное время голоса, заполнение краев) такие же, как и в распознавании в реальном времени. Подробности см. в документации Транскрипция в реальном времени. Ниже приведены элементы конфигурации, доступные исключительно для транскрипции файлов:
Разделение говорящих и маркировка
Если в качестве метода сегментации выбрано «Говорящий», следующие параметры определяют качество разделения:
- Speaker Count: Если вы точно знаете, сколько человек говорят в аудиозаписи, укажите конкретное число (1–10) для лучшего эффекта. Если установлено значение «Авто», порог кластеризации сам определит количество человек.
- Cluster Threshold (действует только в режиме «Авто»): Контролирует чувствительность системы к звуковым различиям. Чем ниже значение, тем легче разделить разные тембры на разных людей (один человек может быть разделен на двоих); чем выше значение, тем легче сгруппировать похожие тембры как одного и того же человека (два человека могут быть объединены).
- Минимальное время голоса: Голосовые сегменты короче этой длительности будут отброшены, что позволит отфильтровать очень короткие шумы, такие как кашель или междометия.
- Максимальный интервал объединения: Соседние сегменты одного и того же говорящего с временным интервалом менее этого значения будут автоматически объединены для уменьшения фрагментации сегментации.
- Маркировка личности: При включении система будет сравнивать идентифицированных говорящих с теми, кто уже внесен в библиотеку голосовых отпечатков, и автоматически подписывать их настоящие имена. Это также является обязательным условием для использования «Интеллектуального режима».
- Язык голосового отпечатка: Выберите «китайский» для китайских сценариев и «английский» для английских сценариев. Примечание: Пространства признаков моделей голосовых отпечатков китайского и английского языков несовместимы; выбор неправильного языка приведет к полной неудаче сопоставления. Другие языки необходимо тестировать на основе их языковых семей.
- Порог соответствия распознавания (требуется маркировка личности): Личность определяется только тогда, когда результат сравнения голосового отпечатка выше этого значения. Не следует устанавливать его слишком высоким, иначе известные сотрудники могут быть не распознаны.
Расширенная конфигурация сегментации
- Интеллектуальное объединение: Автоматически объединяет короткие предложения на основе временного интервала между соседними сегментами, что сокращает количество фрагментированных сегментов и помогает повысить общую точность распознавания.
- Интервал объединения: Объединение запускается, когда интервал между двумя сегментами меньше этого значения (в секундах).
Специфическая конфигурация модели
- Квантованная версия Модели 1: При включении скорость вывода немного выше, но точность немного ниже, что мало влияет на большинство сценариев.
- Язык Модели 1: Как правило, варианта «Авто» достаточно; ручное указание языка (китайский/английский/японский/корейский), когда он явно известен, может улучшить качество вывода.
- Встроенная пунктуация Модели 1 + Преобразование текста в цифры: Включает встроенную пунктуацию модели и преобразование чисел, например, выводя «пятьдесят километров» как «50 километров».
Системные службы
- Преобразование текста в цифры: Поддерживается только для китайского языка, преобразует произносимые числа в стандартные форматы.
- Пунктуация (китайский, английский): Если пунктуация в результатах распознавания ненормальна (например, после включения интеллектуального объединения появляется большое количество точек), этот пункт можно включить для исправления пунктуации (модели пунктуации необходимо сначала загрузить в разделе «Управление моделями»).
5. Более эффективная постобработка
После завершения распознавания вы можете использовать встроенные инструменты для прямой генерации высококачественных документов:
- Преобразование упрощенного/традиционного письма: В один клик переключайтесь между упрощенным и традиционным китайским письмом (с поддержкой вариантов Тайваня и Гонконга).
- Удаление дубликатов контента: Автоматически удаляет повторяющиеся слова, вызванные наложением аудио или галлюцинациями модели.
- Замена профессиональных слов: Воспользуйтесь функцией «Профессиональный словарь», чтобы одним кликом исправить технические термины или инициалы имен в тексте.
6. Экстремальная производительность
Благодаря глубоко оптимизированному локальному движку вывода Owl Meeting может достигать экстремальных скоростей даже на процессоре обычного офисного компьютера:
- Компьютеры начального уровня/старые (например, i5-4210m): 30-минутный аудиофайл может быть обработан примерно за 3 минуты.
- Основные домашние/офисные компьютеры (например, i5-11400H): 30-минутный аудиофайл обычно занимает всего около 1 минуты.
7. Часто задаваемые вопросы и советы
- В: Почему в документации неоднократно подчеркивается необходимость конвертации многоканального звука в моно?
О: Многоканальные записи (стерео) в сложных условиях подвержены помехам из-за эха. После конвертации в моно извлечение характеристик голосового отпечатка ИИ-движком будет более чистым, что может значительно повысить точность разделения говорящих. - В: Идентифицированные говорящие превратились в Speaker_0, Speaker_1...?
О: Это временные идентификаторы, назначенные системой. Вы можете нажать на эти идентификаторы прямо на странице результатов для глобального переименования. Система автоматически их зарегистрирует, и они вступят в силу в экспортированных позже файлах SRT или TXT. - В: Я хочу, чтобы распознанный текст был напрямую конвертирован в традиционный китайский?
О: После завершения распознавания нажмите кнопку «Преобразование упрощенного/традиционного письма» внизу и выберите соответствующий код региона (например, «традиционный китайский» или «Тайвань»), чтобы одним кликом конвертировать весь текст.