Голосовые отпечатки и управление дикторами
Библиотека голосовых отпечатков — это ключевая функция Owl Meeting, позволяющая системе «знать, кто говорит». Благодаря предварительной записи образцов голоса каждого участника, система может автоматически распознавать и указывать имя диктора при транскрибации файлов, а также назначать наиболее подходящую модель распознавания для каждого человека.
1. Добавление диктора
- Перейдите в раздел [Speakers] на левой панели инструментов.
- Нажмите [Add Speaker], укажите имя (обязательно) и примечания (опционально).
- Назначьте модель распознавания для диктора: при включении «Интеллектуального режима» в транскрибации файлов система будет автоматически использовать указанную здесь модель для распознавания голоса данного диктора.
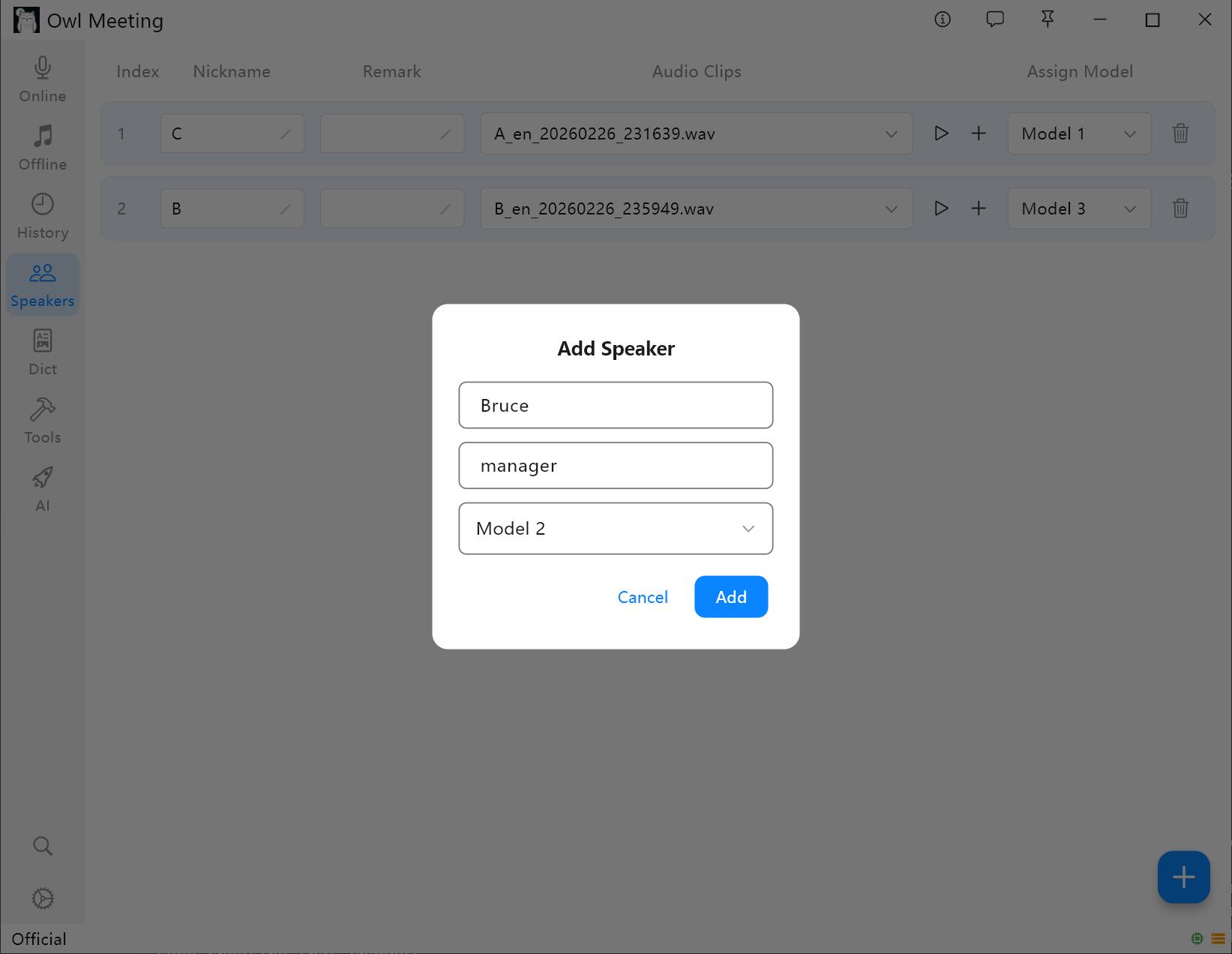 Интерфейс управления библиотекой голосовых отпечатков
Интерфейс управления библиотекой голосовых отпечатков
2. Добавление образцов голоса
- Выберите диктора и нажмите [Add Audio].
- Выберите аудиофайл, содержащий четкую человеческую речь данного диктора.
- Установите время начала/окончания в окне обрезки и нажмите кнопку прослушивания для подтверждения.
- Выберите Язык голосового отпечатка: выберите «Китайский» для китайских образцов и «English» для английских. Другие языки можно выбирать по языковой группе.
- Нажмите «Сохранить», система автоматически извлечет характеристики голоса и свяжет их с диктором.
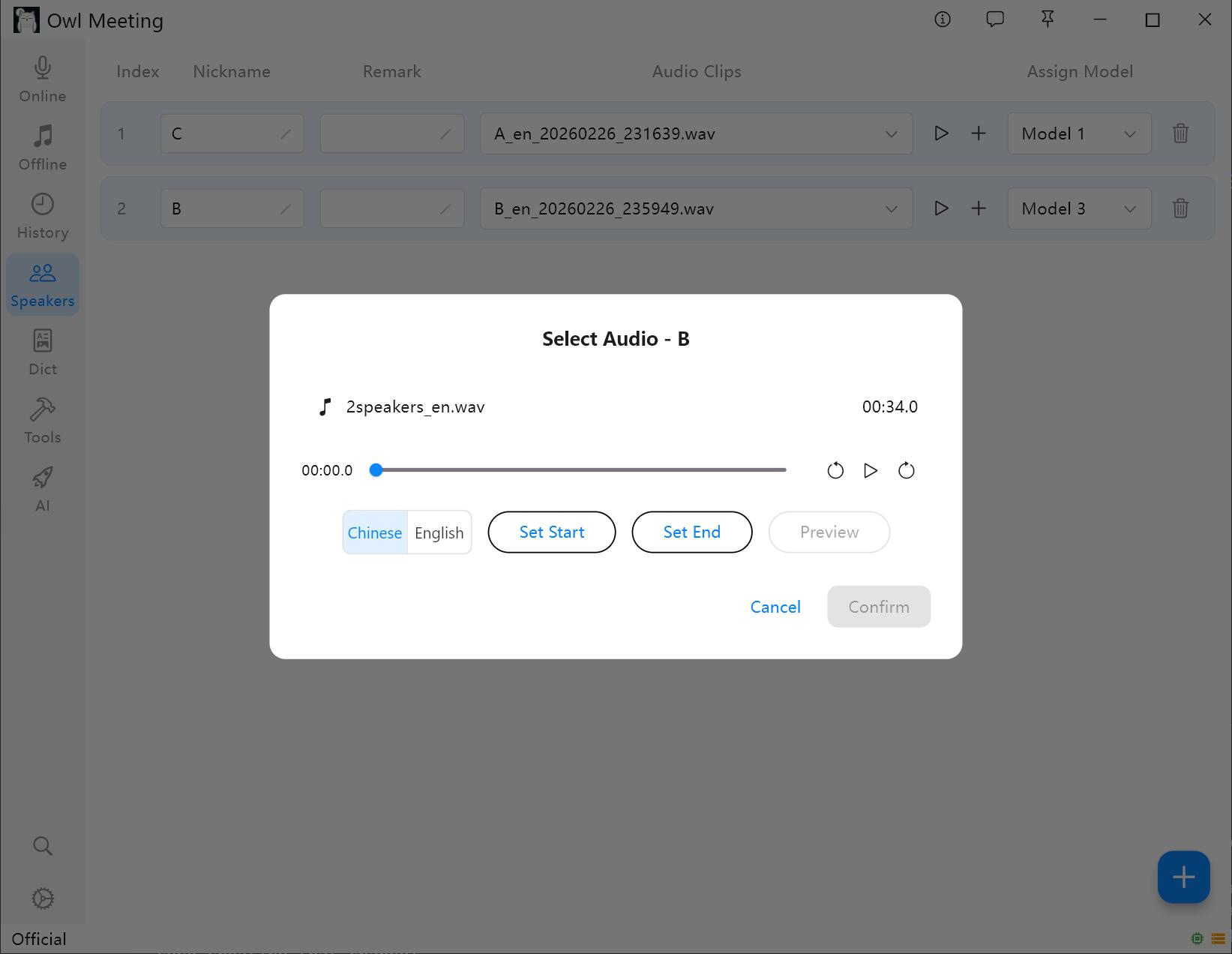 Добавление и обрезка образцов голоса
Добавление и обрезка образцов голоса
Лучшие практики сбора образцов
- Качество аудио: выбирайте фрагменты с тихим фоном и только голосом целевого диктора; избегайте моментов, где говорят несколько человек одновременно.
- Рекомендуемая длительность: каждый фрагмент должен быть от 5 до 30 секунд. Слишком короткие записи не дадут достаточно характеристик, а слишком длинные не принесут пользы.
- Несколько образцов: для одного диктора можно добавить несколько записей. Если голос человека сильно меняется в разных ситуациях (например, при личном общении или по телефону), добавление разных образцов повысит точность распознавания.
- Соответствие языка: язык, выбранный при добавлении образца, должен совпадать с «Языком голосового отпечатка» в настройках транскрибации файлов; иначе сопоставление не сработает. Характеристики китайской и английской моделей голоса несовместимы.
3. Текущее обслуживание
- Вы можете в любое время изменить имя диктора, примечания и назначенную модель.
- Переключайтесь между разными образцами и прослушивайте их напрямую.
- При удалении образца соответствующий локальный аудиофайл также будет удален.
4. Как голосовые отпечатки работают при транскрибации
Библиотека голосов в основном используется в режиме оффлайн-транскрибации файлов. Чтобы имена дикторов отображались автоматически, должны быть соблюдены следующие условия:
- Выбран метод сегментации «По дикторам».
- Включен переключатель «Маркировка личности».
- «Язык голосового отпечатка» в настройках транскрибации файлов совпадает с языком, выбранным при добавлении образцов.
При соблюдении этих условий метки дикторов в результатах распознавания будут автоматически заменены на реальные имена из библиотеки.
5. Часто задаваемые вопросы и решение проблем
- В: Почему в результатах отображается только Speaker_0, Speaker_1, а не имена?
О: Проверьте три пункта из раздела «Как голосовые отпечатки работают при транскрибации». Самая частая причина — забыли включить «Маркировку личности» или не совпадает язык голосового отпечатка. - В: Имена проставились, но они перепутаны?
О: Попробуйте повысить «Порог соответствия распознавания» (в разделе «Разделение и маркировка дикторов» в настройках транскрибации файлов) или добавьте более четкие образцы голоса для соответствующего диктора. - В: Автоматически определено неверное количество человек?
О: Рекомендуется вручную указать «Количество дикторов» в настройках. При использовании автоматического режима можно подстроить [Cluster Threshold], чтобы отрегулировать чувствительность системы к различиям в голосах.
Совет: При создании библиотеки добавьте по 1-2 четких образца голоса для каждого постоянного участника. После настройки библиотеки все последующие транскрибации будут автоматически определять личности без повторной настройки.