🎞️ Транскрипція аудіо- та відеофайлів
Режим транскрипції аудіо та відео (офлайн-режим) спеціально розроблений для обробки існуючих аудіо- та відеофайлів. Вся обробка виконується локально, що гарантує збереження вашої комерційної таємниці та безпеки даних.
🚀 Швидкий старт
- Імпорт файлів: Перетягніть аудіо/відеофайли безпосередньо у вікно програми або натисніть «Вибрати файл» у центрі.
- Вибір режиму та моделі: Виберіть необхідний спосіб обробки у правій частині інтерфейсу.
- Негайний запуск: Натисніть кнопку запуску внизу. Ви зможете спостерігати за ходом обробки в реальному часі (Ініціалізація -> Попередня обробка -> Сегментація -> Розпізнавання).
1. Аудіоформати та попередня обробка
Owl Meeting має потужну сумісність із файлами, але розуміння наступних деталей перед початком може значно підвищити точність:
- Підтримка форматів: Нативна підтримка MP3, WAV, M4A, MP4, MKV, MOV, FLAC та майже всіх інших основних аудіо/відеоформатів.
- Покращення шумозаглушення: Якщо у вашому записі присутній значний фоновий шум, рекомендується ввімкнути «Покращення шумозаглушення» на правій панелі. Після завершення обробки ви можете вільно перемикатися між оригінальним та покращеним звуком у плеєрі, щоб перевірити ефект.
- Рекомендація щодо каналів: Для багатоканальних відеофайлів рекомендується використовувати вбудовані інструменти для попереднього вилучення/конвертації в монофонічний звук для отримання точнішого результату розпізнавання.
 Перетягування файлів та підтримка форматів
Перетягування файлів та підтримка форматів
2. Режим розпізнавання та сегментація
Ви можете гнучко комбінувати стратегії розпізнавання залежно від складності вмісту файлу:
- Звичайний режим: Для транскрипції всього файлу використовується одна й та сама модель розпізнавання голосу. Просто та ефективно, найвища швидкість.
- Інтелектуальний режим: Використовується в поєднанні з ідентифікацією мовців. Ви можете призначати ексклюзивні моделі для різних ідентифікованих мовців (наприклад, призначити Модель 1 Мовцю А, а Модель 2 — Мовцю Б).
- Стратегія сегментації:
- Часовий інтервал (VAD): Автоматично сегментує на основі пауз у голосі, підходить для особистих заяв та подкастів.
- Розділення мовців: Автоматично нарізає на основі характеристик голосу. Порада: Перед початком необхідно вказати модель голосових відбитків (китайська/англійська); інші мови можна вибрати на основі мовної сім'ї.
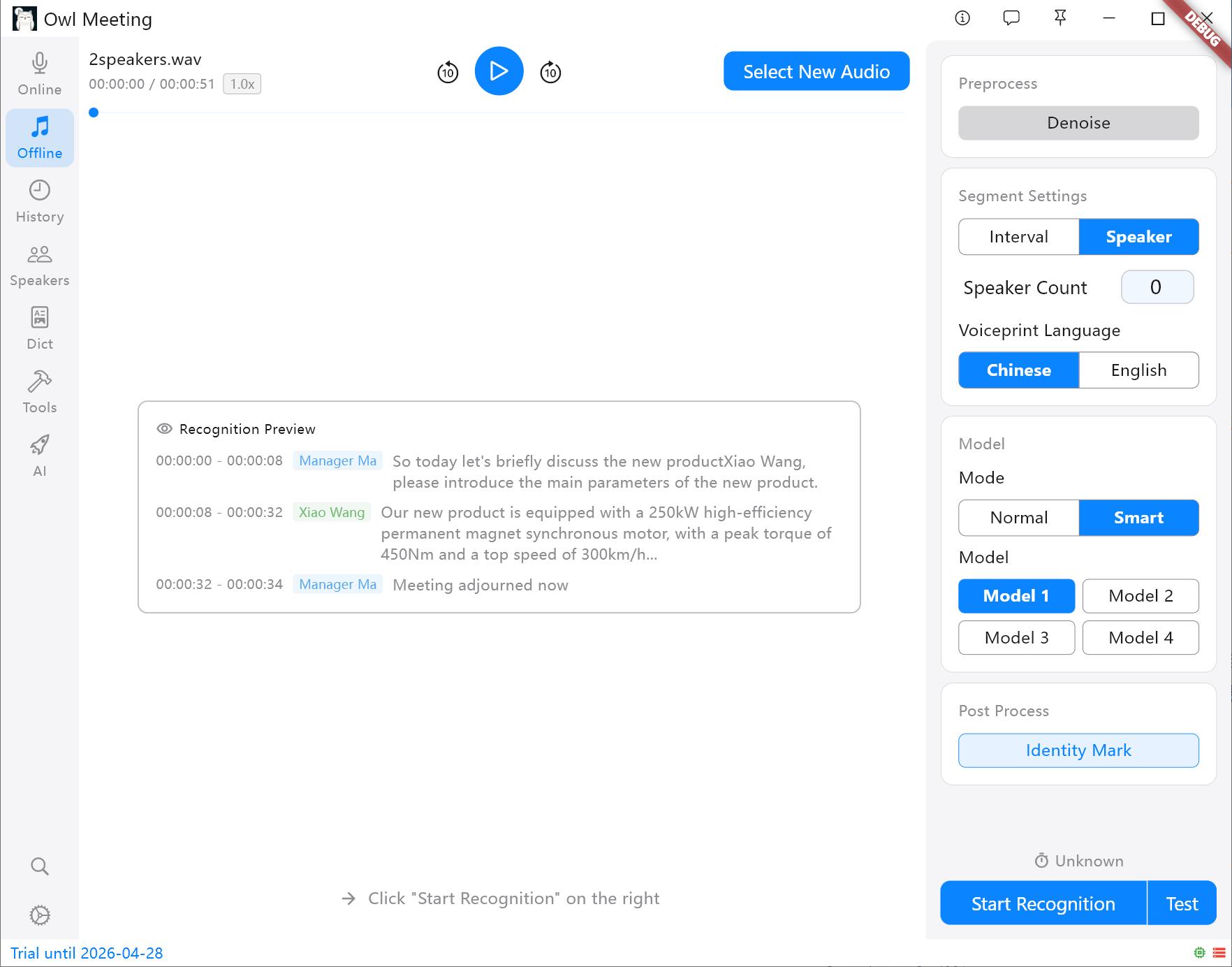 Методи сегментації та панель налаштувань
Методи сегментації та панель налаштувань
3. Тестовий режим
Попередній перегляд ефекту розпізнавання налаштувань.
- Тестовий режим: Перед обробкою дуже довгого аудіо ви можете використовувати функцію тестування, щоб перевірити, чи відповідають поточні параметри очікуванням (буде використано поточні параметри для випадкового вибору трьох хвилин аудіо для розпізнавання).
4. Ексклюзивні налаштування та тонке налаштування
У панелі офлайн-налаштувань параметри сегментації VAD (поріг виявлення голосу, мінімальний час тиші/голосу/максимальний час голосу, заповнення країв) такі самі, як і в розпізнаванні в реальному часі. Подробиці див. у документації Транскрипція в реальному часі. Нижче наведено елементи конфігурації, доступні виключно для транскрипції файлів:
Розділення мовців та маркування
Якщо як метод сегментації вибрано «Мовець», наступні параметри визначають якість розділення:
- Кількість мовців: Якщо ви точно знаєте, скільки людей говорять в аудіозаписі, вкажіть конкретне число (1–10) для кращого ефекту. Якщо встановлено значення «Авто», поріг кластеризації сам визначить кількість людей.
- Поріг кластеризації (діє лише в режимі «Авто»): Контролює чутливість системи к звуковим відмінностям. Чим нижче значення, тим легше розділити різні тембри на різних людей (одна людина може бути розділена на двох); чим вище значення, тим легше згрупувати схожі тембри як одну й ту саму людину (дві людини можуть бути об'єднані).
- Мінімальний час голосу: Голосові сегменти, коротші за цю тривалість, будуть відкинуті, що дозволить відфільтрувати дуже короткі шуми, такі як кашель або вигуки.
- Максимальний інтервал об'єднання: Сусідні сегменти одного й того самого мовця з часовим інтервалом менше цього значення будуть автоматично об'єднані для зменшення фрагментації сегментації.
- Маркування особистості: При ввімкненні система порівнюватиме ідентифікованих мовців із тими, хто вже внесений до бібліотеки голосових відбитків, і автоматично підписуватиме їхні справжні імена. Це також є обов'язковою умовою для використання «Інтелектуального режиму».
- Мова голосового відбитка: Виберіть «китайська» для китайських сценаріїв та «англійська» для англійських сценаріїв. Примітка: Простори ознак моделей голосових відбитків китайської та англійської мов несумісні; вибір неправильної мови призведе до повної невдачі зіставлення. Інші мови необхідно тестувати на основі їхніх мовних сімей.
- Поріг відповідності розпізнавання (потребує маркування особистості): Особистість визначається лише тоді, коли результат порівняння голосового відбитка вищий за це значення. Не слід встановлювати його занадто високим, інакше відомі співробітники можуть бути не розпізнані.
Розширена конфігурація сегментації
- Інтелектуальне об'єднання: Автоматично об'єднує короткі речення на основі часового інтервалу між сусідніми сегментами, що скорочує кількість фрагментованих сегментів та допомагає підвищити загальну точність розпізнавання.
- Інтервал об'єднання: Об'єднання запускається, коли інтервал між двома сегментами менший за це значення (у секундах).
Специфічна конфігурація моделі
- Квантована версія Моделі 1: При ввімкненні швидкість виведення трохи вища, але точність трохи нижча, що мало впливає на більшість сценаріїв.
- Мова Моделі 1: Як правило, варіанта «Авто» достатньо; ручне вказання мови (китайська/англійська/японська/корейська), коли вона явно відома, може покращити якість виведення.
- Вбудована пунктуація Моделі 1 + Перетворення тексту на цифри: Вмикає вбудовану пунктуацію моделі та перетворення чисел, наприклад, виводячи «п'ятдесят кілометрів» як «50 кілометрів».
Системні служби
- Перетворення тексту на цифри: Підтримується лише для китайської мови, перетворює розмовні числа на стандартні формати.
- Пунктуація (китайська, англійська): Якщо пунктуація в результатах розпізнавання ненормальна (наприклад, після ввімкнення інтелектуального об'єднання з'являється велика кількість крапок), цей пункт можна ввімкнути для виправлення пунктуації (моделі пунктуації необхідно спочатку завантажити у розділі «Управління моделями»).
5. Ефективніша післяобробка
Після завершення розпізнавання ви можете використовувати вбудовані інструменти для прямої генерації високоякісних документів:
- Перетворення спрощеного/традиційного письма: В один клік перемикайтеся між спрощеним та традиційним китайським письмом (з підтримкою варіантів Тайваню та Гонконгу).
- Видалення дублікатів вмісту: Автоматично видаляє слова, що повторюються, спричинені накладанням аудіо або галюцинаціями моделі.
- Заміна професійних слів: Скористайтеся функцією «Професійний словник», щоб одним кліком виправити технічні терміни або ініціали імен у тексті.
6. Екстремальна продуктивність
Завдяки глибоко оптимізованому локальному двигуну виведення Owl Meeting може досягати екстремальних швидкостей навіть на процесорі звичайного офісного комп'ютера:
- Комп'ютери початкового рівня/старі (наприклад, i5-4210m): 30-хвилинний аудіофайл може бути оброблений приблизно за 3 хвилини.
- Основні домашні/офісні комп'ютери (наприклад, i5-11400H): 30-хвилинний аудіофайл зазвичай займає лише близько 1 хвилини.
7. Часті запитання та поради
- З: Чому в документації неодноразово наголошується на необхідності конвертації багатоканального звуку в моно?
В: Багатоканальні записи (стерео) у складних умовах схильні до перешкод через відлуння. Після конвертації в моно вилучення характеристик голосового відбитка ШІ-двигуном буде чистішим, що може значно підвищити точність розділення мовців. - З: Ідентифіковані мовці перетворилися на Speaker_0, Speaker_1...?
В: Це тимчасові ідентифікатори, призначені системою. Ви можете натиснути на ці ідентифікатори прямо на сторінці результатів для глобального перейменування. Система автоматично їх зареєструє, і вони наберуть чинності у виекспортованих пізніше файлах SRT або TXT. - З: Я хочу, щоб розпізнаний текст був безпосередньо конвертований у традиційну китайську?
В: Після завершення розпізнавання натисніть кнопку «Перетворення спрощеного/традиційного письма» внизу та виберіть відповідний код регіону (наприклад, «традиційна китайська» або «Тайвань»), щоб одним кліком конвертувати весь текст.