Голосові відбитки та управління дикторами
Бібліотека голосових відбитків — це ключова функція Owl Meeting, що дає змогу системі «знати, хто говорить». Завдяки попередньому запису зразків голосу кожної особи, система може автоматично розпізнавати та позначати ім’я диктора під час транскрибування файлів, а також призначати найбільш підходящу модель розпізнавання для різних людей.
1. Додавання диктора
- Перейдіть до розділу «Бібліотека голосів» на лівій панелі інструментів.
- Натисніть «Додати людину», вкажіть ім'я (обов'язково) та примітки (необов'язково).
- Призначте модель розпізнавання для диктора: при увімкненні «Інтелектуального режиму» в транскрибуванні файлів система автоматично використовуватиме вказану тут модель для розпізнавання голосу цього диктора.
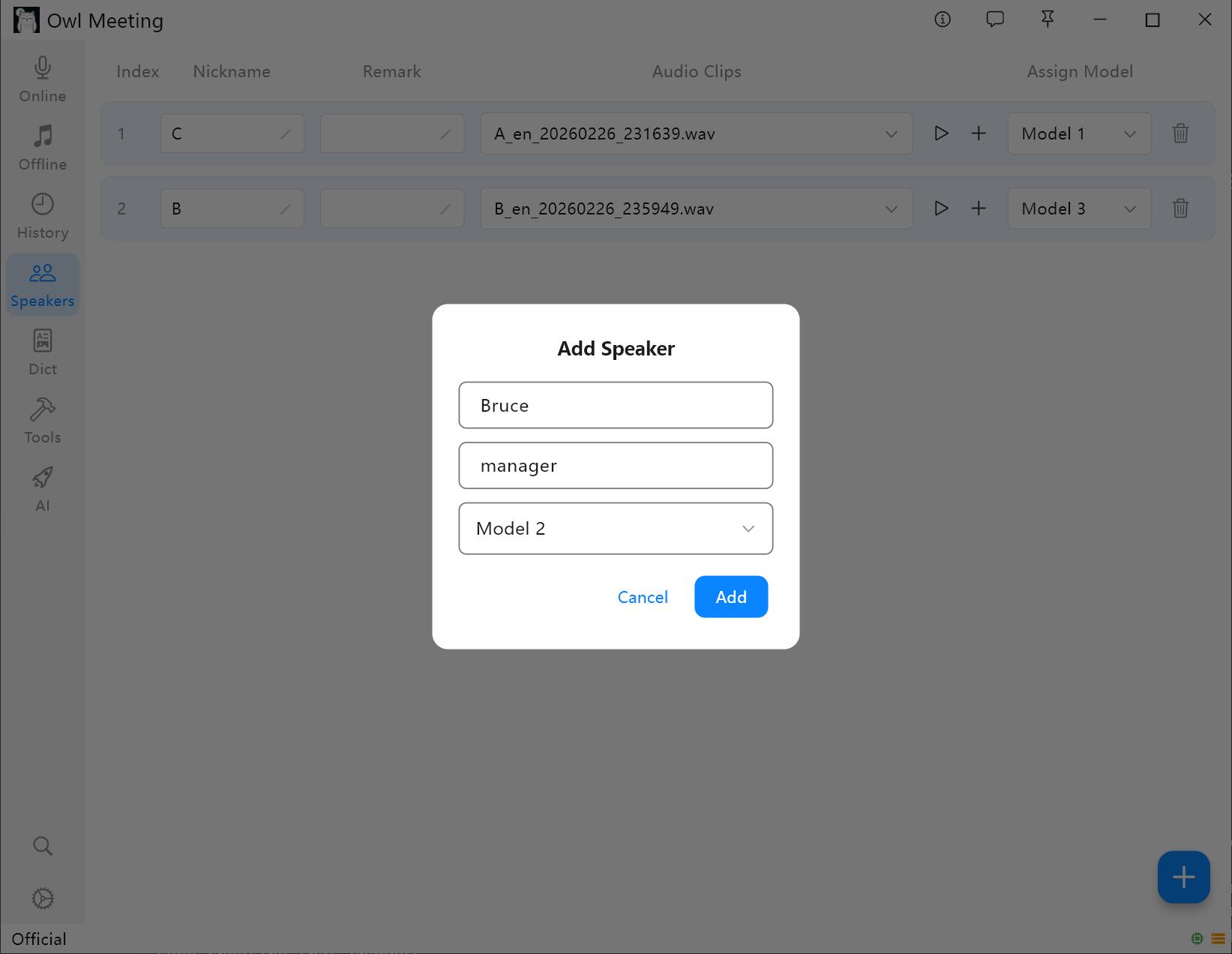 Інтерфейс управління бібліотекою голосових відбитків
Інтерфейс управління бібліотекою голосових відбитків
2. Додавання зразків голосу
- Виберіть диктора та натисніть «Додати аудіо».
- Виберіть аудіофайл, що містить чітку людську мову цього диктора.
- Встановіть час початку/завершення у вікні обрізки та натисніть кнопку прослуховування для підтвердження.
- Виберіть Мова голосового відбитка: виберіть «Китайська» для китайських зразків та «English» для англійських. Інші мови можна вибирати за мовною групою.
- Натисніть «Зберегти», система автоматично вилучить характеристики голосу та зв'яже їх із диктором.
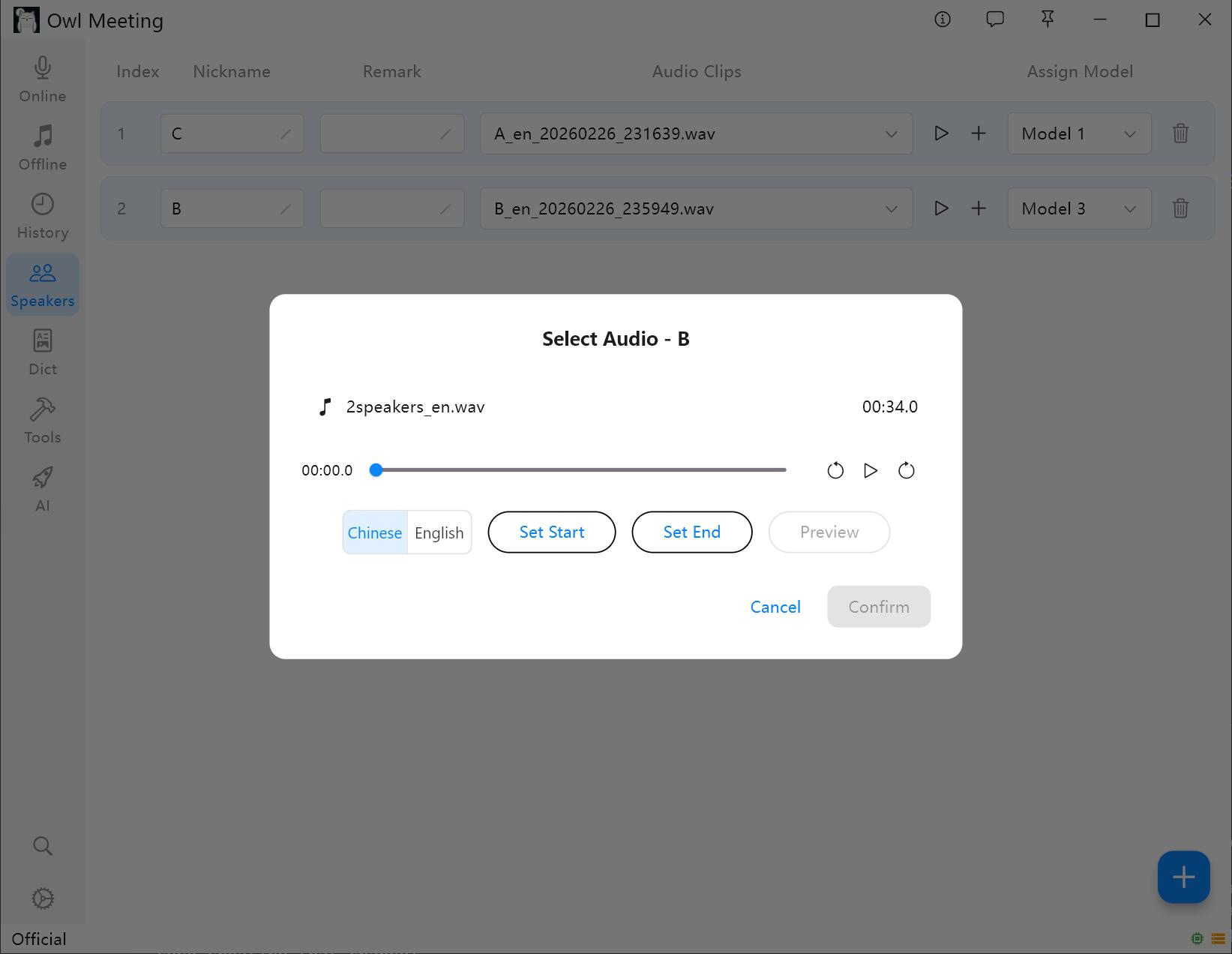 Додавання та обрізка зразків голосу
Додавання та обрізка зразків голосу
Найкращі практики збору зразків
- Якість аудіо: вибирайте фрагменти з тихим фоном і тільки голосом цільового диктора; уникайте моментів, де говорять кілька людей одночасно.
- Рекомендована тривалість: кожен фрагмент має бути від 5 до 30 секунд. Занадто короткі записи не дадуть достатньо характеристик, а занадто довгі не принесуть користі.
- Кілька зразків: для одного диктора можна додати кілька зразків. Якщо голос людини сильно змінюється в різних ситуаціях (наприклад, при особистому спілкуванні або по телефону), додавання різних зразків покращитьточність розпізнавання.
- Відповідність мови: мова, обрана при додаванні зразка, має збігатися з «Мовою голосового відбитка» в налаштуваннях транскрибування файлів; інакше зіставлення не спрацює. Характеристики китайської та англійської моделей голосу несумісні.
3. Поточне обслуговування
- Ви можете будь-коли змінити ім'я диктора, примітки та призначену модель.
- Перемикайтеся між різними зразками та прослуховуйте їх безпосередньо.
- При видаленні зразка відповідний локальний аудіофайл також буде видалено.
4. Як голосові відбитки працюють при транскрибуванні
Бібліотека голосів в основному використовується в режимі офлайн-транскрибування файлів. Щоб імена дикторів відображалися автоматично, мають бути дотримані такі умови:
- Вибрано метод сегментації «За дикторами».
- Увімкнено перемикач «Маркування особистості».
- «Мова голосового відбитка» в налаштуваннях транскрибування файлів збігається з мовою, обраною при додаванні зразків.
При дотриманні цих умов мітки дикторів у результатах розпізнавання будуть автоматично замінені на реальні імена з бібліотеки.
5. Часті запитання та вирішення проблем
- З: Чому в результатах відображається тільки Speaker_0, Speaker_1, а не імена?
В: Перевірте три пункти з розділу «Як голосові відбитки працюють при транскрибуванні» один за одним. Найчастіша причина — забули увімкнути «Маркування особистості» або не збігається мова голосового відбитка. - З: Імена проставилися, але вони переплутані?
В: Спробуйте підвищити «Поріг відповідності розпізнавання» (у розділі «Розподіл та маркування дикторів» у налаштуваннях транскрибування файлів) або додайте чіткіші зразки голосу для відповідного диктора. - З: Автоматично визначено невірна кількість осіб?
В: Рекомендується вручну вказати «Кількість дикторів» у налаштуваннях. При використанні автоматичного режиму можна підлаштувати «Поріг кластеризації», щоб відрегулювать чутливість системи до відмінностей у голосах.
Порада: При створенні бібліотеки додайте по 1-2 чітких зразки голосу для кожного постійного учасника. Після налаштування бібліотеки всі подальші транскрибування будуть автоматично визначати особистості без повторного налаштування.