🎞️ 音视频文件转写
音视频转写模式(离线模式)专为处理现有的录音、视频文件而设计。所有处理均在本地完成,确保您的商业隐私与数据安全。
🚀 快速开启
- 导入文件:直接将音视频文件拖入软件窗口,或点击中央的“选择文件”。
- 选择模式、模型:界面右侧选择需要的处理方式
- 即刻开始:点击下方的开始按钮,您可以实时看到处理进度(初始化 -> 预处理 -> 分段 -> 识别)。
1. 音频格式与预处理
Owl Meeting 具备极强的文件兼容性,但在开始前了解以下细节可以显著提升准确率:
- 格式支持:原生支持 MP3, WAV, M4A, MP4, MKV, MOV, FLAC 等几乎所有主流音视频格式。
- 降噪增强:如果您的录音背景杂音较大,建议开启右侧面板的“降噪增强”。处理完成后,您可以在播放器中自由切换原音与增强音,试听效果。
- 声道建议:对于多声道视频文件,建议利用内置工具先提取/转换为单声道音频,以获得更精准的识别体验。
 文件拖入与格式支持
文件拖入与格式支持
2. 识别模式与分段
您可以根据文件内容的复杂程度灵活组合识别策略:
- 常规模式:全篇使用同一个语音识别模型进行转录。简单直接,速度最快。
- 智能模式:配合说话人身份标记使用。您可以为识别出的不同发言人指定专属模型(如给 A 分配模型1,给 B 分配模型2)。
- 分段策略:
- 时间间隔 (VAD):基于语气停顿自动分段,适用于个人陈述、播客。
- 说话人分离:根据声音特征自动切分。提示:开始处理前需指定声纹模型(中/英),其他语言可根据语系选择。
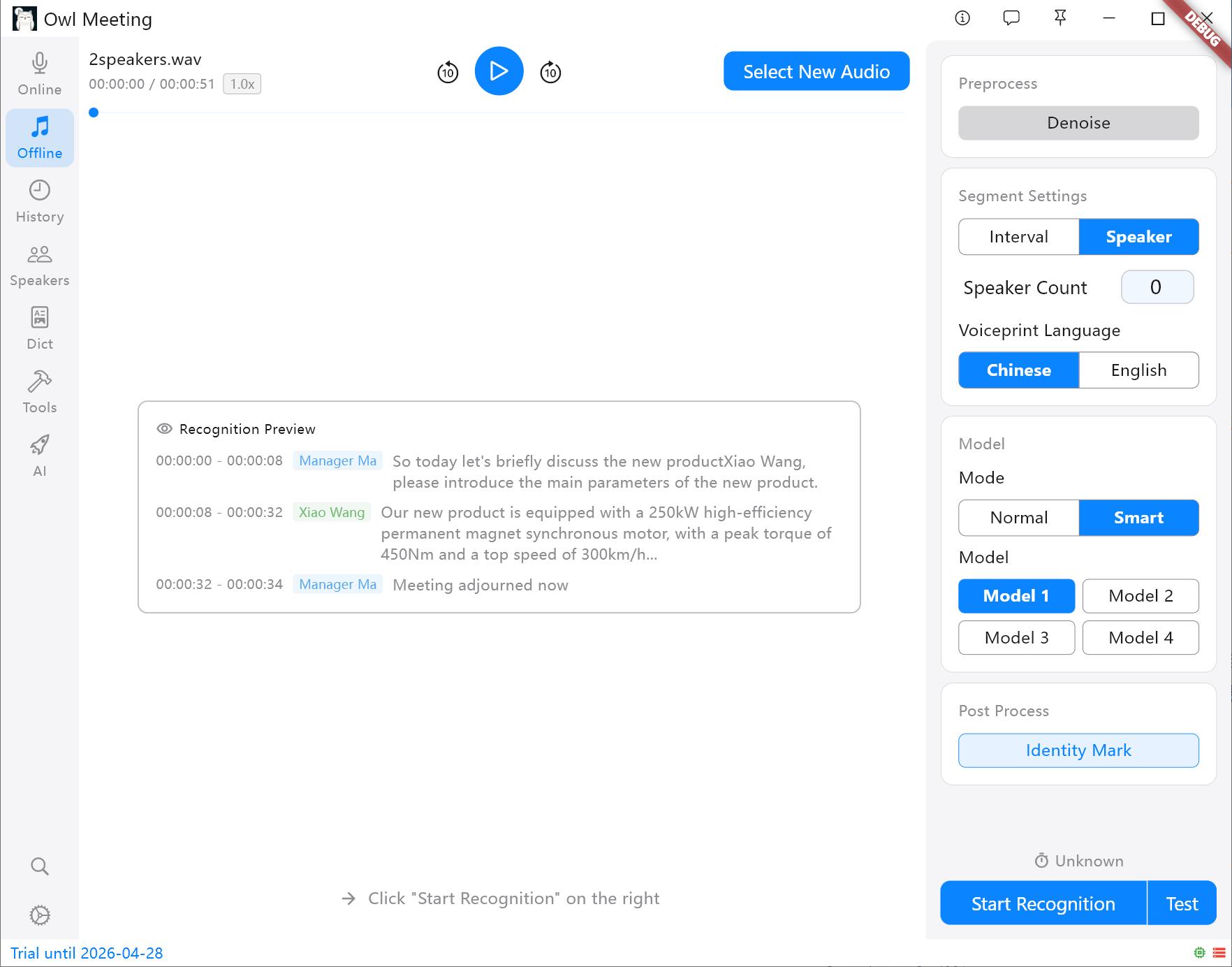 分段方式与设置面板
分段方式与设置面板
3. 测试模式
预览设置项识别效果。
- 测试模式:处理超长音频前,可以使用测试功能,验证当前参数是否符合预期(会使用当前参数,随机抽取三分钟音频进行识别)。
4. 专属设置与微调
离线设置面板中,VAD 分段参数(语音判定阈值、最小静音/语音/最大语音时间、边缘填充)与实时识别相同,详见实时转写文档。以下是文件转写专属的配置项:
说话人分离与标记
当分段方式选择"说话人"时,以下参数决定分离质量:
- 说话人数量:明确知道音频中有几人说话时,直接指定具体数字(1~10),效果最佳。设为"自动"则由聚类阈值自行判断人数。
- 聚类阈值(仅"自动"模式生效):控制系统对声音差异的敏感度。值越低,越容易把不同音色分成不同的人(可能一人被拆成两人);值越高,越容易将相近音色归为同一人(可能两人被合并)。
- 最小语音时间:低于此时长的语音片段会被丢弃,可过滤咳嗽、语气词等极短杂音。
- 最大合并间隔:时间间隔小于此值的相邻同一说话人片段会被自动合并,减少碎片化分段。
- 身份标记:开启后,系统会将识别出的说话人与声纹库中已录入的人员进行比对,自动标注真实姓名。这也是使用"智能模式"的前提条件。
- 声纹语言:中文场景选"中文",英文场景选"英文"。注意:中英文声纹模型的特征空间互不兼容,选错会导致匹配完全失效。其他语言需根据语系自行测试。
- 识别匹配阈值(需开启身份标记):声纹比对结果高于此值才判定身份。不宜设置过高,否则已知人员可能无法被识别。
分段进阶配置
- 智能合并:根据相邻语音片段的时间间隔自动合并短句,可减少碎片分段,有助于提升整体识别准确率。
- 合并间隔:两个片段间隔小于此值(秒)时触发合并。
模型特定配置
- 模型1 量化版本:启用后推理速度稍快,但精度略有损失,对大多数场景影响不大。
- 模型1 语言:一般选"自动"即可;明确知道音频语种(中/英/日/韩)时手动指定可提高输出质量。
- 模型1 内置标点 + 文本转数字:启用模型自带的标点和数字转换,例如将"五十公里"输出为"50公里"。
系统服务
- 文本转数字:仅支持中文,将口语化数字转为标准格式,如"五十公里" → "50km"。
- 标点(中,英):当识别结果标点异常时(比如开启 智能合并 后出现大量句号)可开启此项进行标点修复(需先在"模型管理"中下载标点模型)。
5. 更高效的后处理
识别完成后,您可以利用内置工具直接生成高质量文稿:
- 简繁转换:一键转换简体、繁体(支持台繁、港繁匹配)。
- 内容去重:自动剔除由于音频重叠或模型幻觉产生的重复文字。
- 专业词替换:利用“专业词库”功能,一键修正文中出现的专业术语或姓名缩写。
6. 极致性能表现
得益于深度优化的本地推理引擎,即便在普通办公电脑的 CPU 上,Owl Meeting 也能跑出极速:
- 入门级/旧电脑 (如 i5-4210m):30 分钟音频约 3 分钟即可完成。
- 主流家用/办公电脑 (如 i5-11400H):30 分钟音频通常只需约 1 分钟。
7. 常见问题与技巧
- Q: 为什么文档中多次强调要将多声道转换为单声道?
A: 多声道(立体声)录音在复杂环境下容易产生回声干扰。转换为单声道后,AI 引擎对声纹特征的提取会更加纯净,能显著提升说话人分离的准确率。 - Q: 识别出的发言人变成了 Speaker_0, Speaker_1...?
A: 这是系统赋予的临时 ID。您可以在结果页面直接点击这些 ID 进行全局重命名。系统会自动记录并在后续导出的 SRT 或 TXT 中生效。 - Q: 我想让识别出的文字直接转为繁体?
A: 识别完成后,点击下方的“简繁转换”按钮,选择对应的地区编码(如“繁体中文”或“台繁”),即可一键全篇转换。
提示: 对于多通道视频文件,建议利用内置工具先提取/转换为单声道音频,以获得最精准的识别体验。