声纹与说话人管理
声纹库是 Owl Meeting 实现"知道谁在说话"的核心功能。通过预先录入每个人的声音样本,系统在文件转写时可以自动识别并标注发言人姓名,还能为不同的人指定最合适的识别模型。
1. 新增说话人
- 进入左侧工具栏的 [声纹库]。
- 点击 [添加人员],填写姓名(必填)和备注(可选)。
- 为该说话人 指定识别模型:当开启文件转写中的 [智能模式] 时,系统会自动使用此处指定的模型来识别该说话人的语音。
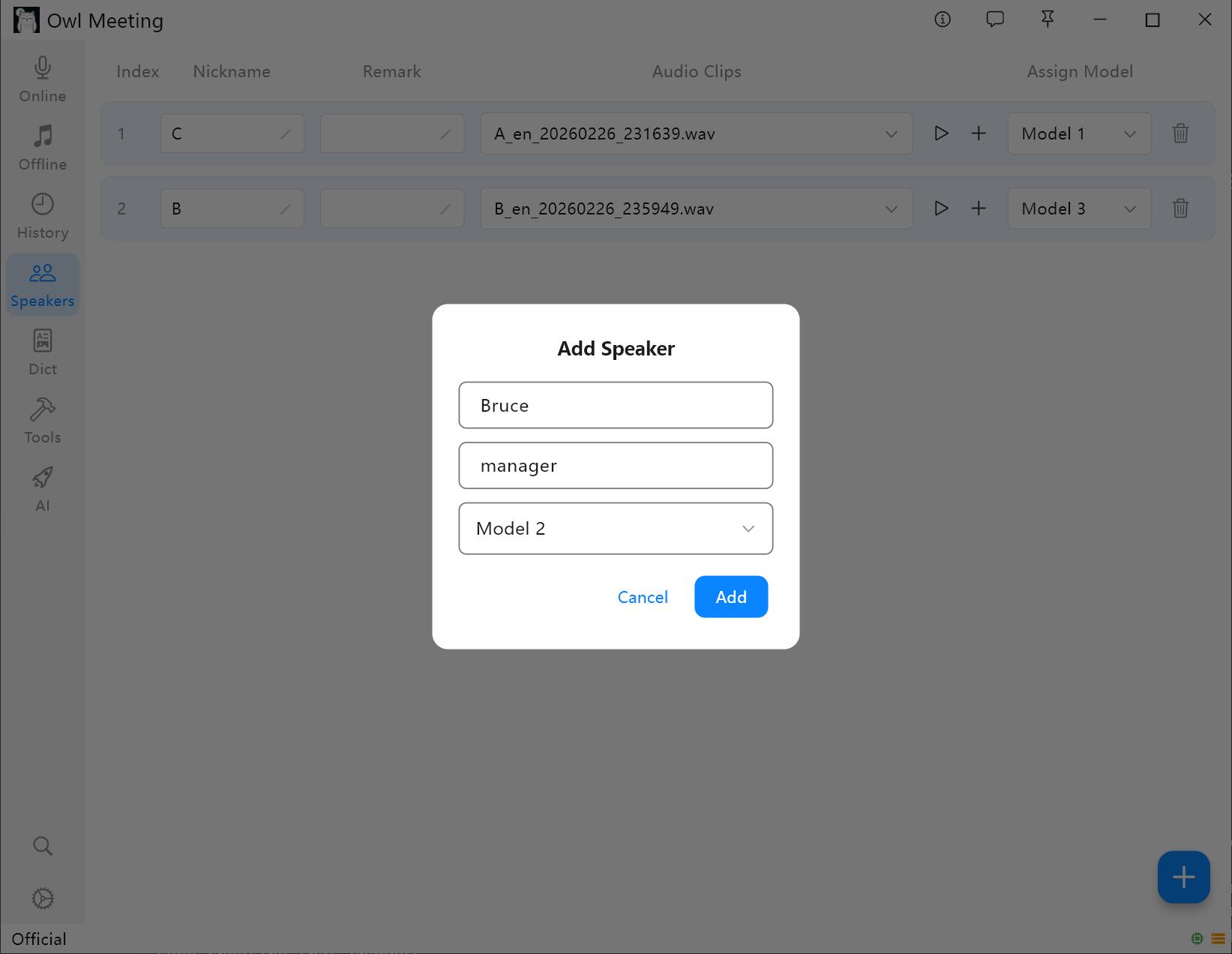 声纹库管理界面
声纹库管理界面
2. 添加声纹样本
- 选中一个说话人,点击 [添加音频]。
- 选择一段包含该说话人清晰人声的音频文件。
- 在裁剪窗口中设置开始/结束时间,可点击试听确认。
- 选择 [声纹语言] :中文样本选 [中文],英文样本选 [英文]。其他语言可根据语系选择最接近的一个。
- 点击保存,系统会自动提取声纹特征并关联到该说话人。
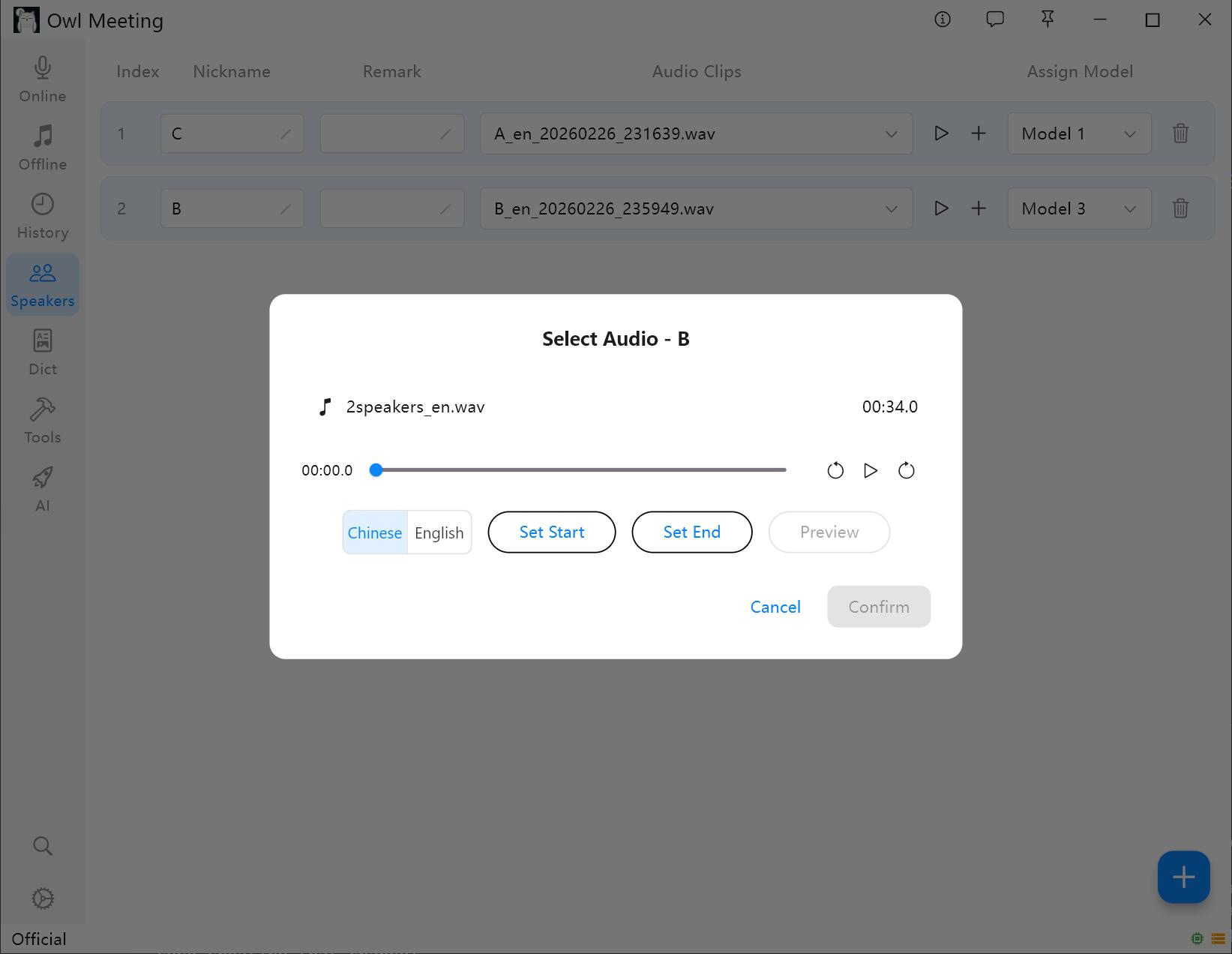 声纹样本添加与裁剪
声纹样本添加与裁剪
样本采集最佳实践
- 音频质量:选择背景安静、只有目标说话人声音的片段,避免多人同时说话的段落。
- 时长建议:每段样本 5~30 秒即可。过短特征不够,过长无额外收益。
- 多段样本:一个说话人可以添加多段样本。如果同一个人在不同场景(如面对面/电话)下音色差异较大,添加多段不同场景的样本可以提高识别率。
- 语言匹配:添加样本时选择的语言,必须与文件转写设置中的 [声纹语言] 一致,否则匹配会完全失效。中英文声纹模型的特征空间互不兼容。
3. 日常维护
- 可随时修改说话人的姓名、备注和指定模型。
- 可切换查看不同样本并直接试听。
- 删除样本时会同时清理对应的本地音频文件。
4. 声纹库如何在转写中生效
声纹库主要在 离线文件转写 中发挥作用。要让转写结果自动显示说话人姓名,需要同时满足以下条件:
- 分段方式选择 [说话人] 。
- 开启 [身份标记] 开关。
- 文件转写设置中的 [声纹语言] 与添加样本时选择的语言一致。
满足以上条件后,识别结果中的说话人标签将自动替换为声纹库中录入的真实姓名。
5. 常见问题排查
- Q: 识别结果只显示 Speaker_0、Speaker_1,没有名字?
A: 请逐一检查上方"声纹生效条件"中的三项设置。最常见的原因是忘记开启 [身份标记] 或声纹语言不匹配。 - Q: 名字标注出来了,但张冠李戴?
A: 尝试提高 [识别匹配阈值](在文件转写设置的 [说话人分离与标记] 区域),或者为对应说话人重新添加更清晰的声纹样本。 - Q: 自动识别出的人数不对?
A: 推荐在设置中手动指定 [说话人数量] 。如果使用自动模式,可微调 [聚类阈值] 来控制系统对声音差异的敏感度。
建议: 建库时为每个常见参会人员添加 1~2 段清晰的人声样本。声纹库建好后,后续所有文件转写都能自动识别身份,无需重复配置。