实时会议识别
实时模式可用于会议、讲座、网络直播或视频通话等场景。它不仅能同步记录文字,还能叠加 AI 翻译、纠错等处理,让您在会议进行中就获得高质量的文字记录。
快速开启
- 选择声源:在侧边栏选择"麦克风"、"系统"或"双路"。
- 选择模型:根据语种选择合适的识别模型。
- 选择模式:根据需要选择合适的模式
- 配置 AI(可选):如需实时翻译等功能,在下方选择 AI 任务并启动。
- 点击开始:点击"开始录音"按钮,即刻开启 AI 识别。
1. 音频输入源
根据您的应用场景,Owl Meeting 提供了三种灵活的方案:
- 麦克风:采集您通过输入设备(如耳机麦克风、笔记本内置麦克)说出的内容。适用于个人笔记、演讲或面对面会议。
- 系统声音:直接采集电脑内部发出的声音——正在播放的视频、浏览器中的播客或在线报告等。
- 双路模式:同时采集麦克风(您说的话)和系统音频(对方说的话)。使用 腾讯会议、Zoom、飞书 等远程会议工具时推荐此模式。
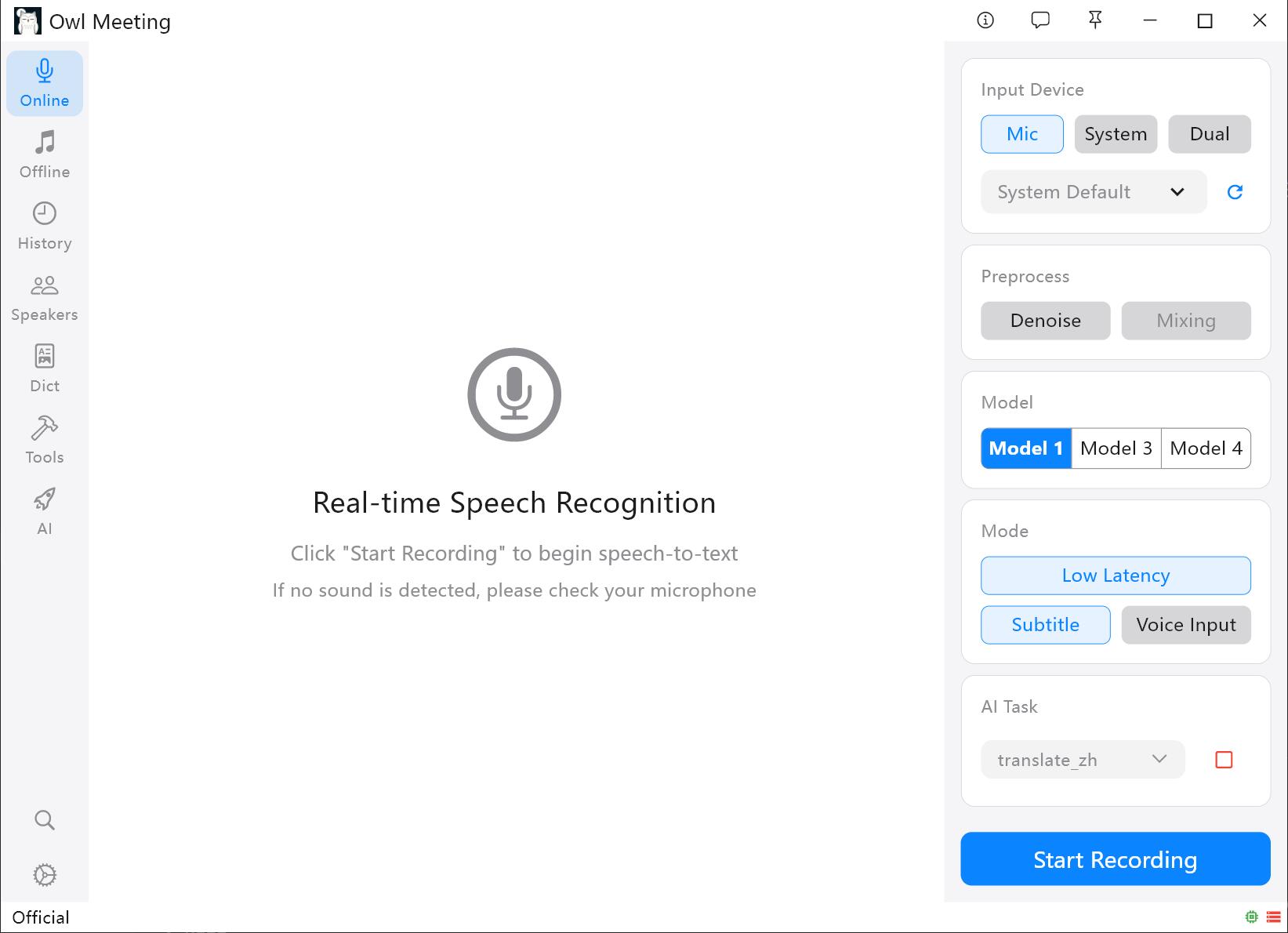 音频输入源选择与侧边栏配置
音频输入源选择与侧边栏配置
2. 识别预处理
在声音送入识别引擎之前,您可以开启以下选项来优化质量:
- 降噪增强:开启后系统会滤除环境背景噪音,可改善丢失句首或句尾字眼的情况。
- 音频混合:在开启降噪后可用。它能合并背景音轨,在特定嘈杂环境下有助于提高识别准确率。混合比例需要根据实际场景从低到高自行测试。
3. 三种交互模式:适配您的工作流
除了在软件主界面查看文字,您还可以选择更高效的展现方式:
- 低延迟模式:
开启后,还没说完一句话,屏幕上就会显示灰色的预测文字,实时跟随您的语音滚动。
- 提示:可在设置中调整"刷新间隔"和"上下文窗口"来平衡延迟与 CPU 占用。 - 字幕模式:
桌面弹出一个半透明的悬浮字幕窗,可自由拖动位置。
- 场景:把它拖到视频窗口下方,像看电影一样阅读会议或直播内容。支持同时显示原文和 AI 处理结果。 字幕悬浮窗效果
字幕悬浮窗效果
- 语音输入助手:
将 Owl Meeting 变成一个语音输入工具,识别结果会自动输入到当前光标位置。
- 进阶用法:可设置唤醒词(如"语音助手"),30 秒不说话自动休眠,说出唤醒词即可唤醒。还可配合 AI 任务,设置指令词触发 AI 处理后再输入结果。
4. 专属设置与微调
如果在使用中遇到不顺手的地方,通常可以通过以下参数解决:
| 场景 | 调节建议 |
|---|---|
| 我明明说话了,但是识别结果中会丢句首或句尾。 | 降低[语音判定阈值]。调低它可以让软件变灵敏。 |
| 每次识别都识别出一大段话,输出结果太慢,读起来费劲。 | 降低[最小静音时间],让模型更快地分段。 |
| 有些很短的句子(比如:"好的"、"嗯嗯"),识别不出来。 | 降低[最小语音时间]。 |
| 字幕一次蹦出来一长串,读不过来;或低延迟模式反应越来越慢。 | 降低[最大语音时长]。通过限制单次处理的时长,尽快输出结果。使用模型2或模型4时适当调低此值,可显著提升响应速度。 |
5. 常见问题与技巧
- Q: 我想让识别结果直接显示繁体中文?
A: 在"设置 → 在线"中将"简繁转换"切换为对应的繁体选项即可。 - Q: 启动大模型时提示"请先点击上方蓝色按钮"?
A: 实时 AI 任务(如翻译、纠错)需要先在侧边栏启动 AI 引擎,请根据提示完成启动。 - Q: 识别过程中 CPU 占用太高?
A: 如果开启了低延迟模式,可以增大"刷新间隔"(如调至 0.8s)来降低负载。也可以关闭低延迟模式,改用普通模式。 - Q: 录音保存在哪里?
A: 默认保存在Music\owl_meeting\audio目录下,可在"设置 → 通用"中自定义路径。详见数据存储文档。
隐私承诺: Owl Meeting 的所有实时识别均在本地完成,处理过程完全不需要联网。您的会议声音和文字记录永远留在您的电脑上。