🤖 Integración del asistente de IA
Utilice modelos desplegados en Ollama para procesar los resultados del reconocimiento. Puede personalizar plantillas para diversas tareas.
1. Configurar el servicio de IA
Ollama local (recomendado, totalmente offline)
- Visite ollama.com/download para descargar e instalar Ollama.
- Confirme la dirección del servicio en los ajustes de IA de Owl Meeting (por defecto es
http://localhost:11434/api). - Haga clic en "Probar" para confirmar que la conexión es normal.
- Busque y descargue el modelo necesario (ej.
qwen3:4b) en la biblioteca de modelos de Ollama.
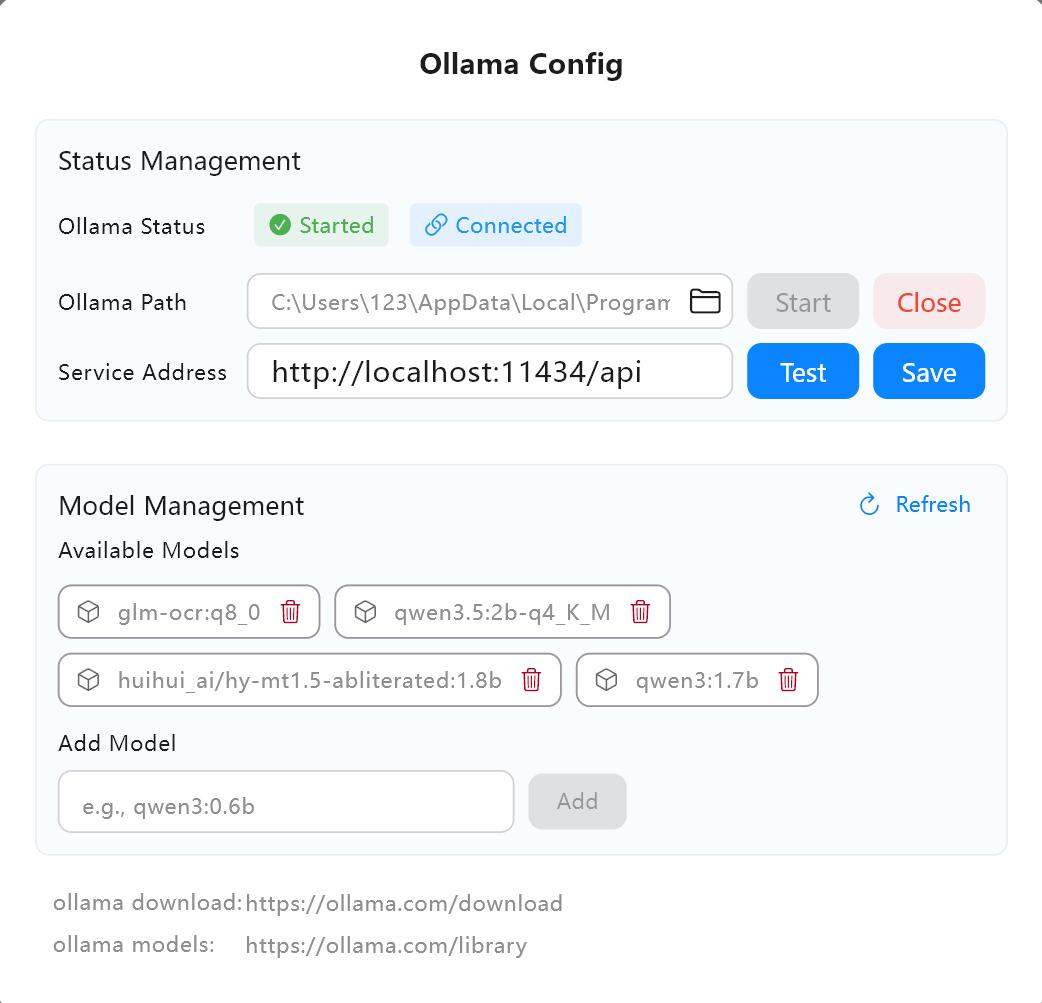 Interfaz de configuración de servicios de IA
Interfaz de configuración de servicios de IA
2. Cuatro tipos de tareas
- Traducción: Traduce los resultados del reconocimiento a otros idiomas. Puede especificar el idioma de origen y el de destino.
- Corrección: Corrige erratas y errores gramaticales, y optimiza la estructura de las frases para que sean más fluidas.
- Resumen: Genera actas de reuniones o resúmenes de contenido.
- Personalizado: Utilice plantillas de prompts personalizadas para procesar los resultados según sus necesidades (por ejemplo, extraer puntos de acción, generar listas de tareas, etc.).
3. Tres modos de entrada
- Individual: Procesa los fragmentos uno por uno. Este es el único modo disponible cuando se utiliza la IA durante la transcripción en tiempo real.
- Lote: Combina varios resultados y los envía al modelo juntos para una mayor eficiencia. El tamaño del lote es personalizable.
- Texto completo: Envía todos los resultados del reconocimiento como un texto completo de una sola vez. Ideal para generar resúmenes de reuniones o traducciones de textos completos.
4. IA en tiempo real vs. IA offline
- IA en tiempo real: Durante el proceso de transcripción en tiempo real, cada fragmento reconocido se envía automáticamente al modelo para su procesamiento y los resultados se muestran de forma síncrona. Requiere iniciar primero la tarea de IA en la barra lateral. Solo se admite el modo "Individual".
- IA offline: Procesa los resultados de transcripción completados en la página de detalles del historial. Admite los modos "Individual", "Lote" y "Texto completo".
5. Parámetros de modelo personalizados
Configuración integrada para los parámetros comunes de los LLM (como temperature, top_p, etc.). Los usuarios avanzados pueden activar el panel de parámetros del modelo para realizar ajustes precisos o pasar parámetros personalizados en formato JSON.
6. Preguntas frecuentes (FAQ)
- Q: ¿No se puede conectar con Ollama?
A: Compruebe si Ollama está en ejecución y si la dirección del servicio es correcta (por defecto:http://localhost:11434/api). - Q: ¿Velocidad de salida lenta?
A: Cambie a un modelo con menos parámetros (por ejemplo, 1.5B o 4B), o cambie el modo de entrada de "Texto completo" a "Individual". - Q: ¿El modo en tiempo real indica "Haga clic primero en el botón azul"?
A: Las tareas de IA en tiempo real requieren que el motor de IA se inicie primero haciendo clic en el botón azul de la barra lateral.
7. Modelos recomendados
- Tareas de traducción: Se recomienda HY-MT1.5-1.8B, un modelo de traducción profesional que admite varios idiomas con una velocidad de inferencia muy rápida.
- Tareas generales: Se recomiendan las series Qwen (por ejemplo, 4B u 8B), que tienen una excelente capacidad de comprensión.