🎞️ Transcripción de archivos de audio y video
El modo de transcripción de audio y video (modo offline) está diseñado específicamente para procesar archivos de audio y video existentes. Todo el procesamiento se completa localmente, lo que garantiza su secreto comercial y la seguridad de sus datos.
🚀 Inicio rápido
- Importar archivos: Arrastre directamente los archivos de audio/video a la ventana del software o haga clic en "Seleccionar archivo" en el centro.
- Seleccionar modo y modelo: Seleccione el método de procesamiento requerido en el lado derecho de la interfaz.
- Comenzar de inmediato: Haga clic en el botón de comenzar de abajo. Puede ver el progreso del procesamiento en tiempo real (Inicialización -> Preprocesamiento -> Segmentación -> Reconocimiento).
1. Formatos de audio y preprocesamiento
Owl Meeting tiene una fuerte compatibilidad de archivos, pero comprender los siguientes detalles antes de comenzar puede mejorar significativamente la precisión:
- Soporte de formatos: Soporte nativo para MP3, WAV, M4A, MP4, MKV, MOV, FLAC y casi todos los demás formatos de audio/video principales.
- Mejora de reducción de ruido: Si su grabación tiene un ruido de fondo significativo, se recomienda activar "Mejora de reducción de ruido" en el panel derecho. Después del procesamiento, puede alternar libremente entre el sonido original y el mejorado en el reproductor para probar el efecto.
- Recomendación de canal: Para archivos de video multicanal, se recomienda utilizar las herramientas integradas para extraer/convertir a audio mono primero para obtener una experiencia de reconocimiento más precisa.
 Arrastrar y soltar archivos y soporte de formatos
Arrastrar y soltar archivos y soporte de formatos
2. Modo de reconocimiento y segmentación
Puede combinar de manera flexible estrategias de reconocimiento basadas en la complejidad del contenido del archivo:
- Modo regular: Todo el archivo utiliza el mismo modelo de reconocimiento de voz para la transcripción. Simple y directo, la velocidad más rápida.
- Modo inteligente: Se usa junto con la identificación de hablantes. Puede asignar modelos exclusivos a diferentes hablantes identificados (por ejemplo, asignar el Modelo 1 al Hablante A y el Modelo 2 al Hablante B).
- Estrategia de segmentación:
- Intervalo de tiempo (VAD): Segmenta automáticamente en función de las pausas de voz, adecuado para declaraciones personales y podcasts.
- Separación de hablantes: Corta automáticamente en función de las características de la voz. Sugerencia: Debe especificar un modelo de huella de voz (chino/inglés) antes de comenzar; otros idiomas se pueden seleccionar según la familia lingüística.
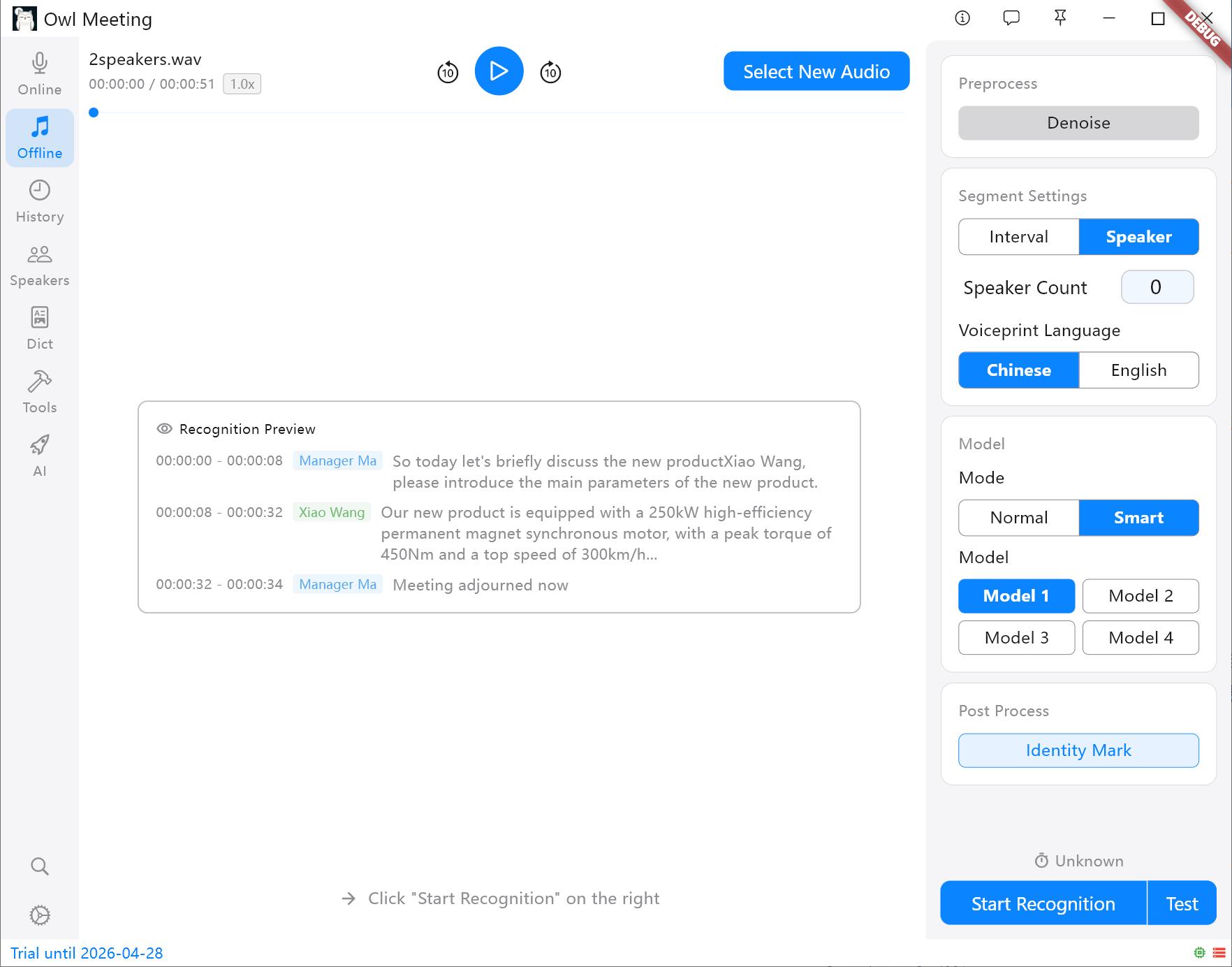 Métodos de segmentación y panel de configuración
Métodos de segmentación y panel de configuración
3. Modo de prueba
Previsualice el efecto de reconocimiento de los ajustes.
- Modo de prueba: Antes de procesar audio muy largo, puede usar la función de prueba para verificar si los parámetros actuales cumplen con las expectativas (utilizará los parámetros actuales para seleccionar aleatoriamente tres minutos de audio para el reconocimiento).
4. Ajustes exclusivos y ajuste fino
En el panel de ajustes offline, los parámetros de segmentación VAD (Umbral de detección de voz, Tiempo mín de silencio/voz/máx de voz, Relleno de bordes) son los mismos que en el reconocimiento en tiempo real. Para obtener más información, consulte la documentación de Transcripción en tiempo real. Los siguientes son los elementos de configuración exclusivos para la transcripción de archivos:
Separación y marcado de hablantes
Cuando el método de segmentación se establece en "Hablante", los siguientes parámetros determinan la calidad de la separación:
- Número de hablantes: Si sabe claramente cuántas personas están hablando en el audio, especifique directamente el número específico (1~10) para obtener el mejor efecto. Si lo establece en "Auto", el umbral de agrupación determinará el número de personas.
- Umbral de agrupación (solo efectivo en el modo "Auto"): Controla la sensibilidad del sistema a las diferencias de sonido. Cuanto más bajo sea el valor, más fácil será separar diferentes timbres en diferentes personas (una persona puede dividirse en dos); cuanto más alto sea el valor, más fácil será agrupar timbres similares como la misma persona (dos personas pueden fusionarse).
- Tiempo mín de voz: Los segmentos de voz más cortos que esta duración se descartarán, filtrando ruidos muy cortos como tos o interjecciones.
- Intervalo máx de fusión: Los segmentos adyacentes del mismo hablante con un intervalo de tiempo menor que este valor se fusionarán automáticamente para reducir la segmentación fragmentada.
- Marcado de identidad: Cuando está activado, el sistema comparará los hablantes identificados con los ya ingresados en la biblioteca de huellas de voz y etiquetará automáticamente sus nombres reales. Este es también un requisito previo para usar el "Modo inteligente".
- Idioma de la huella de voz: Seleccione "Chino" para escenarios en chino e "Inglés" para escenarios en inglés. Nota: Los espacios de características de los modelos de huella de voz en chino e inglés son incompatibles; elegir el incorrecto hará que la coincidencia falle por completo. Otros idiomas deben probarse en función de sus familias lingüísticas.
- Umbral de coincidencia de reconocimiento (requiere marcado de identidad): La identidad se determina solo cuando el resultado de la comparación de la huella de voz es superior a este valor. No debe establecerse demasiado alto, de lo contrario, es posible que no se reconozca al personal conocido.
Configuración avanzada de segmentación
- Fusión inteligente: Fusiona automáticamente oraciones cortas en función del intervalo de tiempo entre segmentos adyacentes, lo que reduce los segmentos fragmentados y ayuda a mejorar la precisión general del reconocimiento.
- Intervalo de fusión: La fusión se activa cuando el intervalo entre dos segmentos es menor que este valor (segundos).
Configuración específica del modelo
- Modelo 1 Versión cuantizada: Cuando está habilitado, la velocidad de inferencia es un poco más rápida, pero la precisión se reduce ligeramente, lo que tiene poco impacto en la mayoría de los escenarios.
- Modelo 1 Idioma: Generalmente, "Auto" está bien; especificar manualmente el idioma (chino/inglés/japonés/coreano) cuando se conoce claramente puede mejorar la calidad de salida.
- Modelo 1 Puntuación incorporada + Texto a número: Habilita la puntuación y la conversión de números incorporadas del modelo, como la salida de "cincuenta kilómetros" como "50 kilómetros".
Servicios del sistema
- Texto a número: Solo se admite para chino, convirtiendo números hablados a formatos estándar.
- Puntuación (chino, inglés): Si la puntuación en los resultados del reconocimiento es anormal (por ejemplo, después de activar la Fusión inteligente aparece una gran cantidad de puntos), este elemento se puede activar para la reparación de la puntuación (los modelos de puntuación deben descargarse primero en "Gestión de modelos").
5. Posprocesamiento más eficiente
Una vez completado el reconocimiento, puede utilizar herramientas integradas para generar directamente manuscritos de alta calidad:
- Conversión Simplificado/Tradicional: Conversión con un clic entre chino simplificado y tradicional (admite la coincidencia para chino tradicional de Taiwán y Hong Kong).
- Deduplicación de contenido: Elimina automáticamente las palabras duplicadas causadas por la superposición de audio o las alucinaciones del modelo.
- Reemplazo de palabras profesionales: Utilice la función "Diccionario profesional" para corregir con un clic términos profesionales o abreviaturas de nombres en el texto.
6. Rendimiento extremo
Gracias al motor de inferencia local profundamente optimizado, Owl Meeting puede alcanzar velocidades extremas incluso en la CPU de un ordenador de oficina normal:
- Ordenadores de nivel de entrada/antiguos (p. ej., i5-4210m): Un archivo de audio de 30 minutos se puede completar en aproximadamente 3 minutos.
- Ordenadores domésticos/de oficina convencionales (p. ej., i5-11400H): Un archivo de audio de 30 minutos suele tardar solo aproximadamente 1 minuto.
7. Preguntas frecuentes y consejos
- P: ¿Por qué se enfatiza repetidamente en la documentación la conversión de multicanal a mono?
R: Las grabaciones multicanal (estéreo) son propensas a la interferencia de eco en entornos complejos. Después de convertir a mono, la extracción de las características de la huella de voz por parte del motor de IA será más pura, lo que puede mejorar significativamente la precisión de la separación de hablantes. - P: ¿Los hablantes identificados se convirtieron en Speaker_0, Speaker_1...?
R: Estos son ID temporales asignados por el sistema. Puede hacer clic directamente en estos ID en la página de resultados para el cambio de nombre global. El sistema los registrará automáticamente y entrarán en vigor en los archivos SRT o TXT exportados posteriormente. - P: ¿Quiero que el texto reconocido se convierta directamente a chino tradicional?
R: Una vez completado el reconocimiento, haga clic en el botón "Conversión Simplificado/Tradicional" de abajo y seleccione el código regional correspondiente (como "Chino tradicional" o "Taiwán tradicional") para convertir todo el texto con un clic.