🎞️ Trascrizione di file audio e video
La modalità di trascrizione audio e video (modalità offline) è progettata specificamente per l'elaborazione di file audio e video esistenti. Tutta l'elaborazione viene completata localmente, garantendo il segreto aziendale e la sicurezza dei dati.
🚀 Avvio rapido
- Importa file: Trascina direttamente i file audio/video nella finestra del software o fai clic su [Select File]
- Seleziona modalità e modello: Seleziona il metodo di elaborazione richiesto sul lato destro dell'interfaccia.
- Avvia immediatamente: Fai clic sul pulsante di avvio in basso. Puoi vedere l'avanzamento dell'elaborazione in tempo reale (Inizializzazione -> Pre-elaborazione -> Segmentazione -> Riconoscimento).
1. Formati audio e pre-elaborazione
Owl Meeting possiede una forte compatibilità di file, ma comprendere i seguenti dettagli prima di iniziare può migliorare significativamente la precisione:
- Supporto formati: Supporto nativo per MP3, WAV, M4A, MP4, MKV, MOV, FLAC e quasi tutti gli altri formati audio/video principali.
- Miglioramento riduzione rumore: Se la registrazione presenta un rumore di fondo significativo, si consiglia di abilitare il "Miglioramento riduzione rumore" nel pannello di destra. Al termine dell'elaborazione, è possibile passare liberamente tra l'audio originale e quello migliorato nel lettore per testarne l'effetto.
- Raccomandazione canale: Per i file video multicanale, si consiglia di utilizzare gli strumenti integrati per estrarre/convertire prima in audio mono per ottenere un'esperienza di riconoscimento più accurata.
 Trascinamento dei file e supporto dei formati
Trascinamento dei file e supporto dei formati
2. Modalità di riconoscimento e segmentazione
È possibile combinare in modo flessibile le strategie di riconoscimento in base alla complessità del contenuto del file:
- Modalità regolare: L'intero file utilizza lo stesso modello di riconoscimento vocale per la trascrizione. Semplice e diretto, velocità massima.
- Smart: Utilizzata in combinazione con l'identificazione dei relatori. È possibile assegnare modelli esclusivi a diversi relatori identificati (ad esempio, assegnare il Modello 1 al Relatore A e il Modello 2 al Relatore B).
- Strategia di segmentazione:
- Intervallo di tempo (VAD): Segmenta automaticamente in base alle pause vocali, adatto per dichiarazioni personali e podcast.
- Separazione dei relatori: Taglia automaticamente in base alle caratteristiche vocali. Suggerimento: Prima di iniziare, è necessario specificare un modello di impronta vocale (Cinese/Inglese); altre lingue possono essere selezionate in base alla famiglia linguistica.
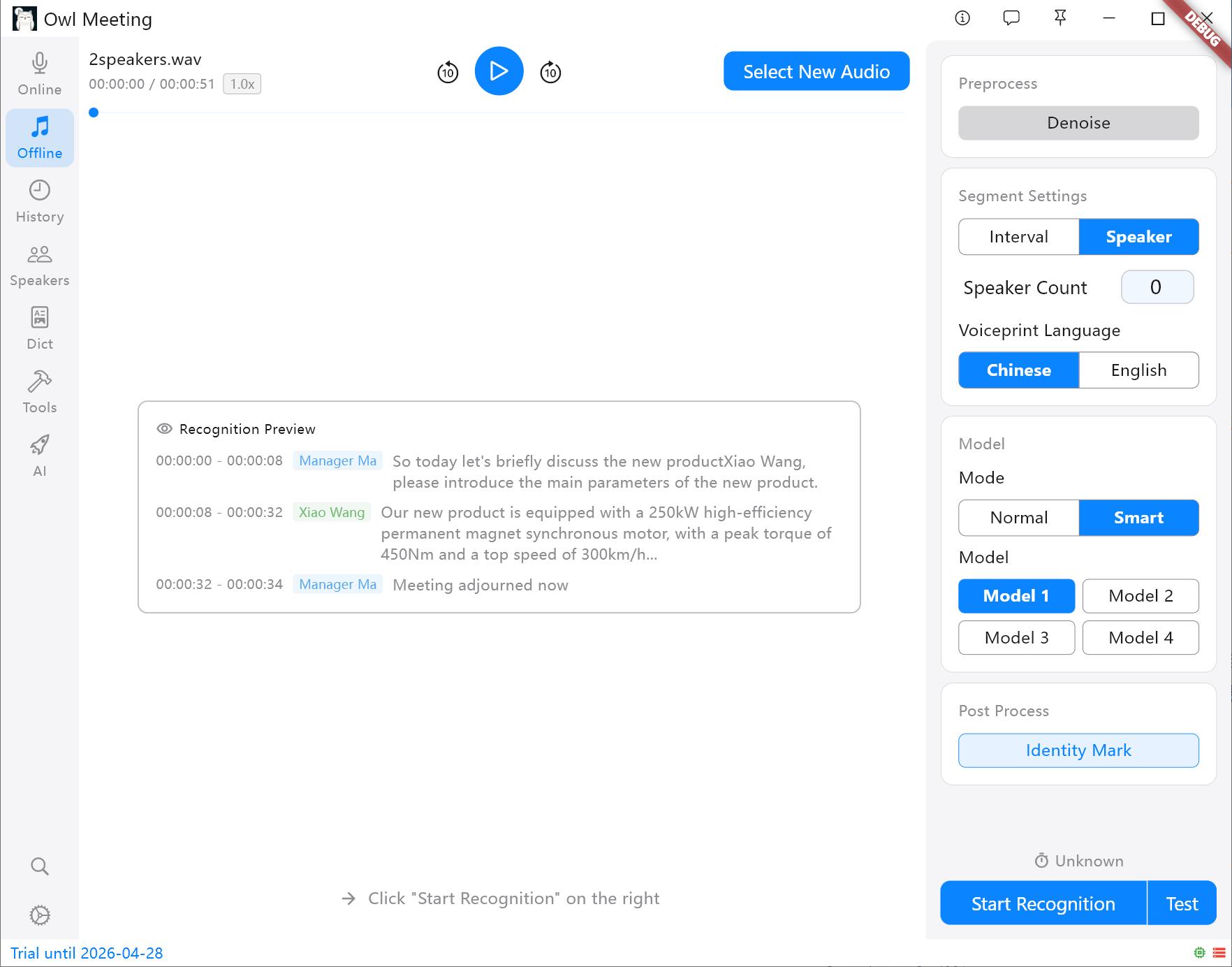 Metodi di segmentazione e pannello delle impostazioni
Metodi di segmentazione e pannello delle impostazioni
3. Modalità di test
Visualizza in anteprima l'effetto di riconoscimento delle impostazioni.
- Modalità di test: Prima di elaborare audio molto lunghi, è possibile utilizzare la funzione di test per verificare se i parametri correnti soddisfano le aspettative (verranno utilizzati i parametri correnti per selezionare casualmente tre minuti di audio per il riconoscimento).
4. Impostazioni esclusive e messa a punto
Nel pannello delle impostazioni offline, i parametri di segmentazione VAD (soglia di rilevamento vocale, tempo di silenzio/voce min/voce max, riempimento bordi) sono gli stessi del riconoscimento in tempo reale. Per i dettagli, vedere la documentazione sulla Trascrizione in tempo reale. Di seguito sono riportate le voci di configurazione esclusive per la trascrizione dei file:
Separazione e tagging dei relatori
Quando il metodo di segmentazione è impostato su "Relatore", i seguenti parametri determinano la qualità della separazione:
- Numero di relatori: Se si sa chiaramente quante persone parlano nell'audio, specificare direttamente il numero esatto (1~10) per ottenere l'effetto migliore. Impostando su "Auto", la soglia di clustering determinerà il numero di persone.
- Cluster Threshold (efficace solo in modalità "Auto"): Controlla la sensibilità del sistema alle differenze sonore. Più basso è il valore, più facile è separare timbri diversi in persone diverse (una persona può essere divisa in due); più alto è il valore, più facile è raggruppare timbri simili come la stessa persona (due persone possono essere unite).
- Tempo di voce min: I segmenti vocali più brevi di questa durata verranno scartati, filtrando rumori molto brevi come colpi di tosse o interiezioni.
- Intervallo di unione max: I segmenti adiacenti dello stesso relatore con un intervallo di tempo inferiore a questo valore verranno uniti automaticamente per ridurre la segmentazione frammentata.
- Identity Mark: Quando abilitato, il sistema confronterà i relatori identificati con quelli già inseriti nella libreria delle impronte vocali ed etichetterà automaticamente i loro nomi reali. Questo è anche un prerequisito per l'utilizzo della [Smart].
- Lingua impronta vocale: Seleziona "Cinese" per scenari in cinese e "Inglese" per scenari in inglese. Nota: Gli spazi delle caratteristiche dei modelli di impronta vocale cinese e inglese sono incompatibili; la scelta sbagliata causerà il fallimento totale della corrispondenza. Altre lingue devono essere testate in base alle rispettive famiglie linguistiche.
- Soglia di corrispondenza del riconoscimento (richiede il Tagging identità): L'identità viene determinata solo quando il risultato del confronto dell'impronta vocale è superiore a questo valore. Non deve essere impostato troppo alto, altrimenti il personale noto potrebbe non essere riconosciuto.
Configurazione avanzata della segmentazione
- Unione intelligente: Unisce automaticamente frasi brevi in base all'intervallo di tempo tra segmenti adiacenti, riducendo i segmenti frammentati e contribuendo a migliorare la precisione complessiva del riconoscimento.
- Intervallo di unione: L'unione viene attivata quando l'intervallo tra due segmenti è inferiore a questo valore (secondi).
Configurazione specifica del modello
- Modello 1 versione quantizzata: Quando abilitata, la velocità di inferenza è leggermente superiore, ma la precisione è leggermente ridotta, il che ha scarso impatto sulla maggior parte degli scenari.
- Modello 1 lingua: Generalmente, "Auto" va bene; specificare manualmente la lingua (cinese/inglese/giapponese/coreano) quando è chiaramente nota può migliorare la qualità dell'output.
- Modello 1 punteggiatura integrata + testo in numeri: Abilita la punteggiatura integrata del modello e la conversione dei numeri, ad esempio emettendo "cinquanta chilometri" come "50 chilometri".
Servizi di sistema
- Testo in numeri: Supportato solo per il cinese, converte i numeri parlati in formati standard.
- Punteggiatura (cinese, inglese): Se la punteggiatura nei risultati del riconoscimento è anormale (ad esempio, se appare un gran numero di punti dopo l'abilitazione di Unione intelligente), questa voce può essere abilitata per la riparazione della punteggiatura (i modelli di punteggiatura devono essere prima scaricati in "Gestione modelli").
5. Pos-elaborazione più efficiente
Al termine del riconoscimento, è possibile utilizzare strumenti integrati per generare direttamente trascrizioni di alta qualità:
- Conversione Semplificato/Tradizionale: Conversione con un clic tra cinese semplificato e tradizionale (supporta la corrispondenza per il cinese tradizionale di Taiwan e Hong Kong).
- Deduplicazione dei contenuti: Rimuove automaticamente le parole duplicate causate dalla sovrapposizione dell'audio o dalle allucinazioni del modello.
- Sostituzione di termini professionali: Utilizza la funzione [Dict] per correggere con un clic i termini professionali o le sigle dei nomi nel testo.
6. Prestazioni estreme
Grazie al motore di inferenza locale profondamente ottimizzato, Owl Meeting può raggiungere velocità estreme anche sulla CPU di un normale computer da ufficio:
- Computer entry-level/vecchi (ad es. i5-4210m): Un file audio di 30 minuti può essere completato in circa 3 minuti.
- Computer domestici/da ufficio comuni (ad es. i5-11400H): Un file audio di 30 minuti richiede solitamente solo circa 1 minuto.
7. FAQ e suggerimenti
- D: Perché nella documentazione viene ripetutamente sottolineato di convertire il multicanale in mono?
R: Le registrazioni multicanale (stereo) sono soggette a interferenze di eco in ambienti complessi. Dopo la conversione in mono, l'estrazione delle caratteristiche dell'impronta vocale da parte del motore AI sarà più pura, il che può migliorare significativamente la precisione della separazione dei relatori. - D: I relatori identificati sono diventati Speaker_0, Speaker_1...?
R: Questi sono ID temporanei assegnati dal sistema. Puoi fare clic direttamente su questi ID nella pagina dei risultati per la ridenominazione globale. Il sistema li registrerà automaticamente e diventeranno effettivi nei file SRT o TXT esportati successivamente. - D: Voglio che il testo riconosciuto sia convertito direttamente in cinese tradizionale?
R: Al termine del riconoscimento, fai clic sul pulsante "Conversione Semplificato/Tradizionale" in basso e seleziona il codice regionale corrispondente (come "Cinese tradizionale" o "Taiwan Tradizionale") per convertire l'intero testo con un clic.