Impronte vocali e gestione dei locutori
La libreria delle impronte vocali è la funzione principale di Owl Meeting per "sapere chi sta parlando". Registrando preventivamente campioni vocali di ogni persona, il sistema può identificare ed etichettare automaticamente il nome del locutore durante la trascrizione dei file e persino specificare il modello di riconoscimento più adatto per diverse persone.
1. Aggiungere un locutore
- Accedi a "Libreria impronte vocali" nella barra degli strumenti a sinistra.
- Fai clic su [Add Speaker], inserisci il nome (obbligatorio) e note (facoltativo).
- Assegna un modello di riconoscimento per il locutore: quando la [Smart]file-transcription.html">Trascrizione file è attiva, il sistema utilizzerà automaticamente il modello qui specificato per riconoscere la voce del locutore.
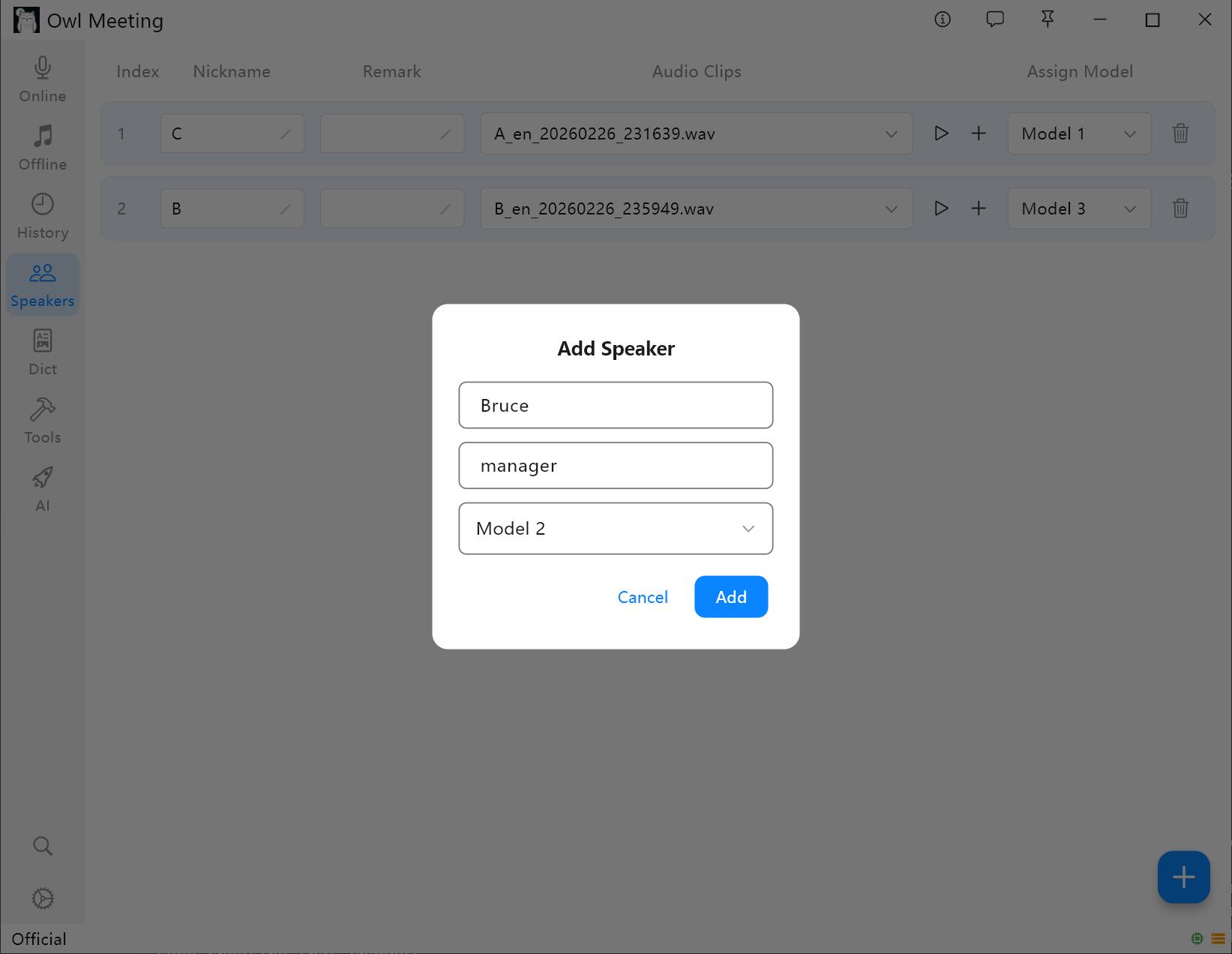 Interfaccia gestione libreria impronte vocali
Interfaccia gestione libreria impronte vocali
2. Aggiungere campioni di impronte vocali
- Seleziona un locutore e fai clic su [Add Audio].
- Seleziona un file audio contenente una voce umana chiara del locutore.
- Imposta l'ora di inizio/fine nella finestra di ritaglio e fai clic su ascolto per confermare.
- Seleziona Lingua impronta vocale: seleziona "Cinese" per i campioni in cinese e "English" per i campioni in inglese. Altre lingue possono essere selezionate in base alla famiglia linguistica.
- Fai clic su salva: il sistema estrarrà automaticamente le caratteristiche dell'impronta vocale e le assocerà al locutore.
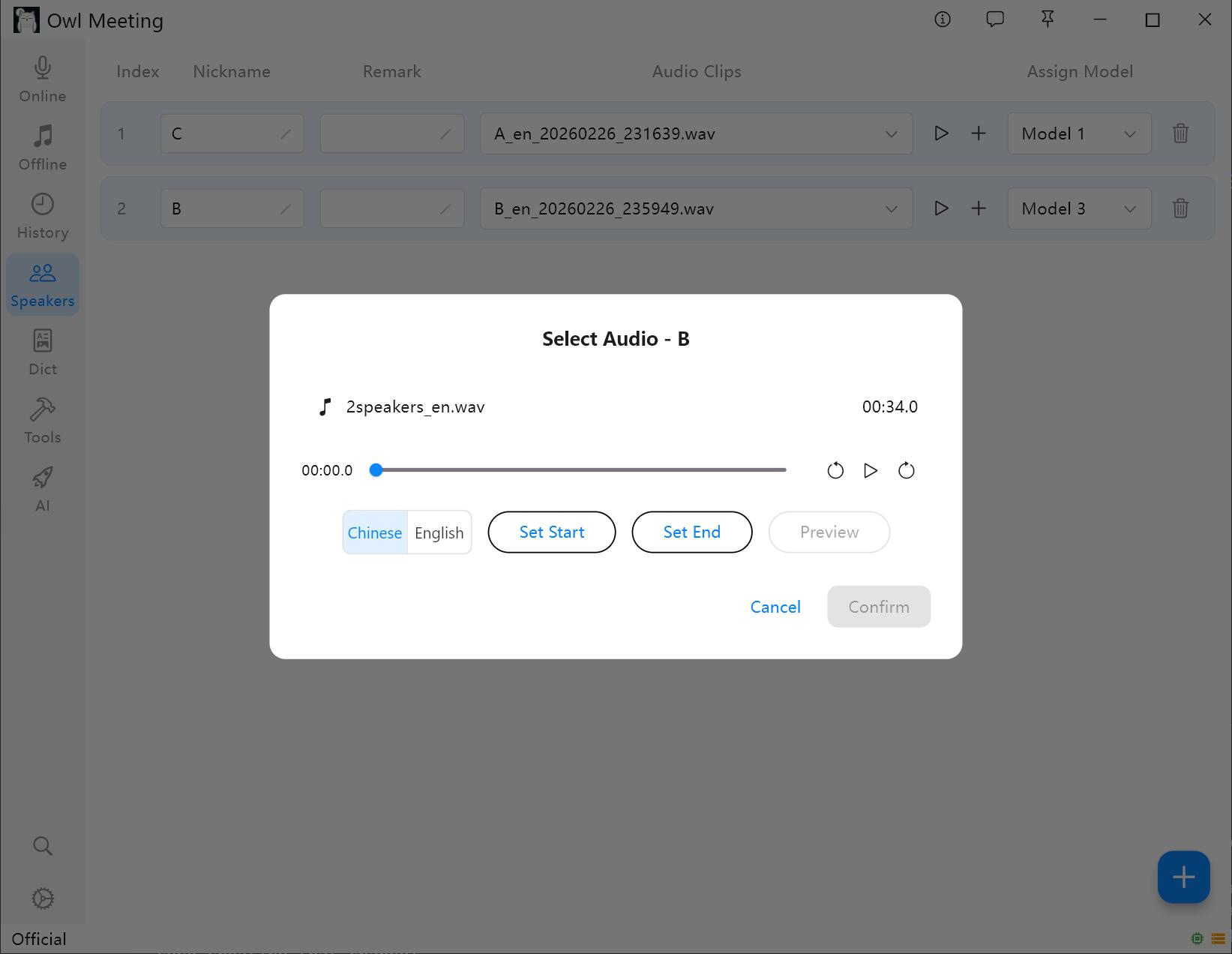 Aggiunta e ritaglio campioni impronte vocali
Aggiunta e ritaglio campioni impronte vocali
Migliori pratiche per la raccolta dei campioni
- Qualità audio: scegli clip con un sottofondo silenzioso e solo la voce del locutore target, evitando i segmenti in cui più persone parlano contemporaneamente.
- Consigli sulla durata: ogni segmento di campione dovrebbe durare 5-30 secondi. Caratteristiche insufficienti se troppo breve, nessun beneficio aggiuntivo se troppo lungo.
- Campioni multipli: un locutore può avere più campioni aggiunti. Se la stessa persona presenta grandi differenze di timbro in scenari diversi (es. di persona/telefono), l'aggiunta di più campioni da scenari differenti può migliorare il tasso di riconoscimento.
- Corrispondenza lingua: la lingua selezionata durante l'aggiunta dei campioni deve essere coerente con la "Lingua impronta vocale" nelle Impostazioni trascrizione file; in caso contrario, la corrispondenza fallirà completamente. Gli spazi delle caratteristiche dei modelli di impronte vocali in cinese e inglese sono incompatibili tra loro.
3. Manutenzione giornaliera
- Modifica il nome del locutore, le note e il modello specificato in qualsiasi momento.
- Passa alla visualizzazione di diversi campioni e ascoltali direttamente.
- Quando si elimina un campione, il file audio locale corrispondente verrà ripulito contemporaneamente.
4. Come la libreria delle impronte vocali diventa operativa nella trascrizione
La libreria delle impronte vocali svolge un ruolo principalmente nella Trascrizione file offline. Affinché i risultati della trascrizione mostrino automaticamente il nome del locutore, devono essere soddisfatte contemporaneamente le seguenti condizioni:
- Seleziona "Locutore" come metodo di segmentazione.
- Attiva l'interruttore "Etichettatura identità".
- La "Lingua impronta vocale" nelle impostazioni della trascrizione file è coerente con la lingua selezionata durante l'aggiunta dei campioni.
Dopo aver soddisfatto le condizioni sopra descritte, il tag del locutore nel risultato del riconoscimento verrà automaticamente sostituito con il nome reale inserito nella libreria delle impronte vocali.
5. FAQ e risoluzione dei problemi
- D: Perché i risultati del riconoscimento mostrano solo Speaker_0, Speaker_1 e nessun nome?
R: Controlla le tre voci in "Come la libreria delle impronte vocali diventa operativa nella trascrizione" una per una. Il motivo più comune è aver dimenticato di attivare "Etichettatura identità" o un'incoerenza nella lingua dell'impronta vocale. - D: I nomi sono etichettati, ma sono assegnati erroneamente alle persone sbagliate?
R: Prova ad aumentare la "Soglia corrispondenza riconoscimento" (nell'area [Separation] delle Impostazioni trascrizione file), oppure aggiungi nuovamente campioni di impronte vocali più chiari per il locutore corrispondente. - D: Il numero di persone riconosciute automaticamente è errato?
R: Si consiglia di specificare manualmente il "Numero di locutori" nelle impostazioni. Se utilizzi la modalità automatica, puoi ottimizzare la [Cluster Threshold] per controllare la sensibilità del sistema alle differenze sonore.