🎞️ Transcriptie van audio- en videobestanden
De modus bestandstranscriptie (offline-modus) is specifiek ontworpen voor het verwerken van bestaande audio- en videobestanden. Alle verwerking vindt lokaal plaats, waardoor uw bedrijfsgeheimen en gegevensbeveiliging zijn gewaarborgd.
🚀 Snelstartgids
- Bestanden importeren: Sleep audio-/videobestanden rechtstreeks naar het programmavenster of klik in het midden op [Select File]
- Modus en model kiezen: Selecteer de gewenste verwerkingsmethode aan de rechterkant van de interface.
- Direct beginnen: Klik op de startknop onderaan. U kunt de voortgang in real-time zien (Initialisatie -> Voorverwerking -> Segmentatie -> Herkenning).
1. Audioformaten en voorverwerking
Owl Meeting heeft een sterke bestandscompatibiliteit, maar het begrijpen van de volgende details voor aanvang kan de nauwkeurigheid aanzienlijk verbeteren:
- Ondersteunde formaten: Native ondersteuning voor MP3, WAV, M4A, MP4, MKV, MOV, FLAC en bijna alle andere gangbare audio-/videoformaten.
- Denoise: Als uw opname veel achtergrondruis bevat, wordt geadviseerd om in het rechterpaneel [Denoise] in te schakelen. Na verwerking kunt u in de speler vrij wisselen tussen het originele en het verbeterde geluid om het effect te testen.
- Zender-aanbeveling: Voor videobestanden met meerdere kanalen wordt geadviseerd om de ingebouwde tools te gebruiken om eerst de audio te extraheren/converteren naar mono voor een nauwkeuriger herkenningsresultaat.
 Bestanden verslepen en formaatondersteuning
Bestanden verslepen en formaatondersteuning
2. Herkenningsmodus en segmentatie
U kunt herkenningsstrategieën flexibel combineren op basis van de complexiteit van de bestandsinhoud:
- Standaardmodus: Het gehele bestand gebruikt hetzelfde spraakherkenningsmodel voor de transcriptie. Eenvoudig en direct, de snelste methode.
- Smart: Wordt gebruikt in combinatie met spreker-identificatie. U kunt exclusieve modellen toewijzen aan verschillende geïdentificeerde sprekers (bijv. Model 1 aan spreker A en Model 2 aan spreker B).
- Segmentatiestrategie:
- Tijdsinterval (VAD): Segmenteert automatisch op basis van spraakpauzes, geschikt voor persoonlijke verklaringen en podcasts.
- Spreker-scheiding: Snijdt automatisch op basis van stemkenmerken. Tip: Geef voor aanvang een voiceprint-model (Chinees/Engels) op; andere talen kunnen worden geselecteerd op basis van de taalfamilie.
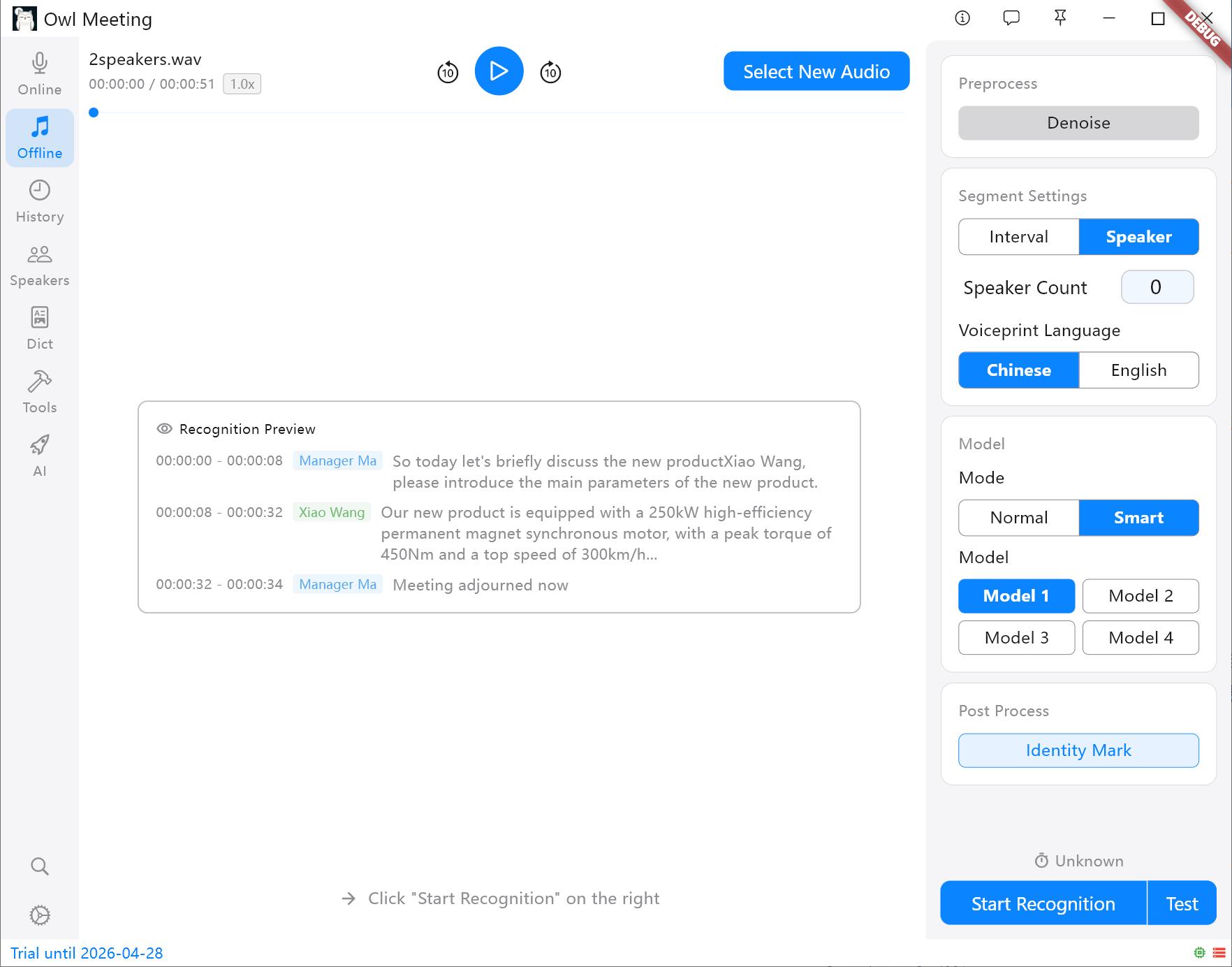 Segmentatiemethoden en instellingenpaneel
Segmentatiemethoden en instellingenpaneel
3. Testmodus
Bekijk een voorbeeld van het herkenningseffect van de instellingen.
- Testmodus: Voordat u zeer lange audio verwerkt, kunt u de testfunctie gebruiken om te controleren of de huidige parameters aan de verwachtingen voldoen (er wordt drie minuten audio willekeurig geselecteerd met de huidige instellingen).
4. Exclusieve instellingen en fijnafstelling
In het offline-instellingenpaneel zijn de VAD-segmentatieparameters (Stemherkenningsdrempel, minimale stilte-/spraak-/maximale spraaktijd, opvulling) gelijk aan die van real-time herkenning. Zie de documentatie over Real-time Transcriptie voor details. De volgende configuratie-items zijn exclusief voor bestandstranscriptie:
Spreker-scheiding en tagging
Wanneer de segmentatiemethode is ingesteld op [Speaker], bepalen de volgende parameters de kwaliteit van de scheiding:
- Speaker Count: Als u precies weet hoeveel mensen er in de audio spreken, geef dan direct het specifieke aantal op (1~10) voor het beste resultaat. Bij de instelling "Auto" bepaalt de clusteringdrempel het aantal mensen.
- Clusteringdrempel (alleen effectief in de modus "Auto"): Regelt de gevoeligheid van het systeem voor geluidsverschillen. Hoe lager de waarde, hoe makkelijker verschillende klanken als verschillende personen worden gescheiden (één persoon kan als twee worden opgeplitst); hoe hoger de waarde, hoe makkelijker vergelijkbare klanken als dezelfde persoon worden gegroepeerd (twee personen kunnen worden samengevoegd).
- Min Speech (s): Spraaksegmenten korter dan deze duur worden genegeerd om zeer kortstondige geluiden zoals hoesten of tussenwerpsels weg te filteren.
- Maximaal samenvoegingsinterval: Naburige segmenten van dezelfde spreker met een tijdsinterval kleiner dan deze waarde worden automatisch samengevoegd om gefragmenteerde segmentatie te verminderen.
- Identiteitstagging: Indien ingeschakeld, vergelijkt het systeem de geïdentificeerde sprekers met degenen die al zijn ingevoerd in de voiceprint-bibliotheek en labelt het automatisch hun echte namen. Dit is ook een voorwaarde voor het gebruik van de [Smart].
- Voiceprint Language: Selecteer "Chinees" voor Chinese scenario's en "Engels" voor Engelse scenario's. Let op: De feature-ruimtes van Chinese en Engelse voiceprint-modellen zijn incompatibel; een verkeerde keuze leidt tot een mislukte matching. Andere talen moeten worden getest op basis van hun taalfamilie.
- Herkenning-matchingdrempel (vereist Identiteitstagging): De identiteit wordt alleen vastgesteld als het resultaat van de voiceprint-vergelijking hoger is dan deze waarde. Stel deze niet te hoog in, omdat bekende personen anders mogelijk niet worden herkend.
Geavanceerde segmentatie-instellingen
- Slim samenvoegen: Voegt korte zinnen automatisch samen op basis van het tijdsinterval tussen naburige segmenten, wat gefragmenteerde segmenten vermindert en de algemene nauwkeurigheid verbetert.
- Samenvoegingsinterval: Samenvoeging wordt geactiveerd wanneer het interval tussen twee segmenten kleiner is dan deze waarde (in seconden).
Modelspecifieke instellingen
- Model 1 Gekwantiseerde versie: Indien ingeschakeld, is de verwerkingssnelheid iets hoger, maar de nauwkeurigheid iets lager, wat in de meeste gevallen weinig effect heeft.
- Model 1 Taal: Doorgaans is "Auto" prima; handmatige opgave (Chinees/Engels/Japans/Koreaans) kan de resultaten verbeteren als de taal bekend is.
- Model 1 Ingebouwde interpunctie + Tekst naar cijfers: Schakelt de in het model ingebouwde interpunctie en getalconversie in, bijvoorbeeld "vijftig kilometer" als "50 kilometer".
Systeemdiensten
- Tekst naar cijfers: Alleen ondersteund voor Chinees, zet uitgesproken getallen om naar standaardformaten.
- Interpunctie (Chinees, Engels): Indien de interpunctie in de resultaten abnormaal is (bijv. veel punten na Slim samenvoegen), kan dit item worden ingeschakeld (interpunctiemodellen moeten eerst worden gedownload in "Modelbeheer").
5. Efficiëntere nabewerking
Nadat de herkenning is voltooid, kunt u de ingebouwde tools gebruiken om direct hoogwaardige documenten te genereren:
- Conversie Vereenvoudigd/Traditioneel: Schakel met één klik tussen Vereenvoudigd en Traditioneel Chinees (met ondersteuning voor varianten uit Taiwan en Hongkong).
- Inhoud ontdubbelen: Automatische verwijdering van dubbele woorden die worden veroorzaakt door audio-overlap of modelhallucinaties.
- Vervangen van vaktermen: Gebruik de functie "Vakwoordenboek" om vaktermen of initialen van namen met één klik te corrigeren.
6. Extreme prestaties
Dankzij de diep geoptimaliseerde lokale inferentie-engine kan Owl Meeting extreme snelheden bereiken, zelfs op de CPU van een gewone kantoorcomputer:
- Instapmodellen/Oude computers (bijv. i5-4210m): Een audiobestand van 30 minuten kan in ongeveer 3 minuten worden voltooid.
- Gangbare thuis-/kantoorcomputers (bijv. i5-11400H): Een audiobestand van 30 minuten duurt doorgaans slechts ongeveer 1 minuut.
7. Veelgestelde vragen en tips
- V: Waarom wordt in de documentatie herhaaldelijk benadrukt dat meerkanaals naar mono moet worden omgezet?
A: Meerkanaalsopnames (stereo) zijn in complexe omgevingen gevoelig voor echo-interferentie. Na het omzetten naar mono is de extractie van voiceprint-kenmerken door de AI-engine zuiverder, wat de nauwkeurigheid van spreker-scheiding aanzienlijk kan verbeteren. - V: Zijn de geïdentificeerde sprekers hernoemd naar Speaker_0, Speaker_1...?
A: Dit zijn tijdelijke ID's die door het systeem zijn toegewezen. U kunt op deze ID's klikken op de resultatenpagina om ze wereldwijd te hernoemen. Het systeem onthoudt deze automatisch voor toekomstige SRT- of TXT-exports. - V: Ik wil dat de herkende tekst direct naar Traditioneel Chinees wordt geconverteerd?
A: Klik na afloop van de herkenning onderaan op de knop "Conversie Vereenvoudigd/Traditioneel" en selecteer de juiste regiocode (zoals "Traditioneel Chinees" of "Taiwan") om de hele tekst met één klik te converteren.