Voiceprint en sprekerbeheer
De voiceprint-bibliotheek is de kernfunctie van Owl Meeting om te "weten wie er spreekt". Door vooraf stemmonsters van elke persoon op te slaan, kan het systeem automatisch de naam van de spreker identificeren en labelen tijdens de transcriptie van bestanden, en zelfs het meest geschikte herkenningsmodel voor verschillende personen specificeren.
1. Een spreker toevoegen
- Ga naar de "Voiceprint-bibliotheek" in de linker werkbalk.
- Klik op [Add Speaker], vul de naam in (verplicht) en eventuele opmerkingen (optioneel).
- Wijs een herkenningsmodel toe aan de spreker: wanneer de [Smart]file-transcription.html">Bestandstranscriptie is ingeschakeld, gebruikt het systeem automatisch het hier gespecificeerde model om de stem van de spreker te herkennen.
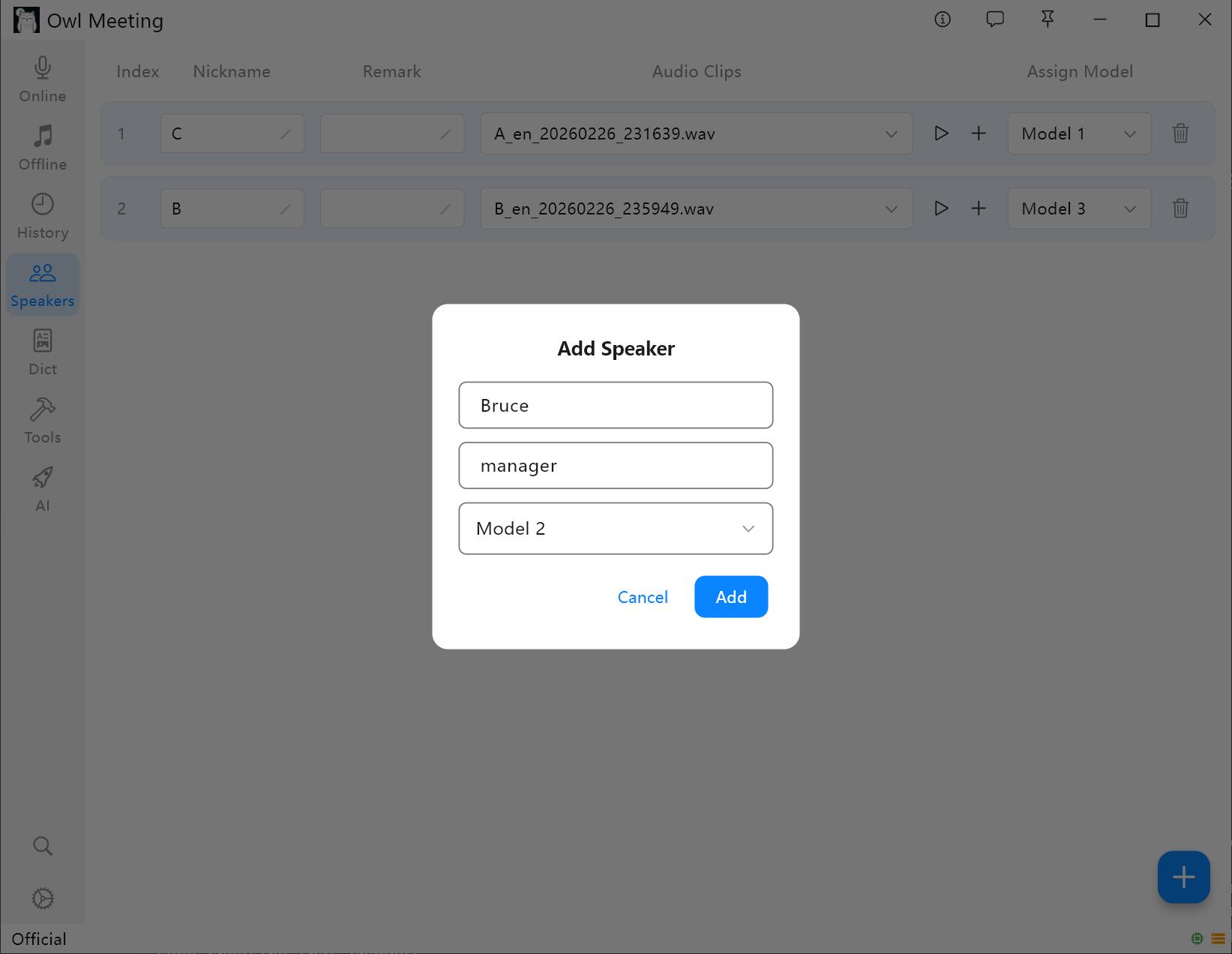 Beheerinterface voiceprint-bibliotheek
Beheerinterface voiceprint-bibliotheek
2. Voiceprint-monsters toevoegen
- Selecteer een spreker en klik op [Add Audio].
- Selecteer een audiobestand met de duidelijke stem van de spreker.
- Stel de begin-/eindtijd in het venster in en klik op luisteren om te bevestigen.
- Selecteer Voiceprint Language: selecteer "Chinees" voor Chinese monsters en "English" voor Engelse monsters. Andere talen kunnen worden geselecteerd op basis van de taalfamilie.
- Klik op opslaan en het systeem zal automatisch de voiceprint-kenmerken extraheren en deze koppelen aan de spreker.
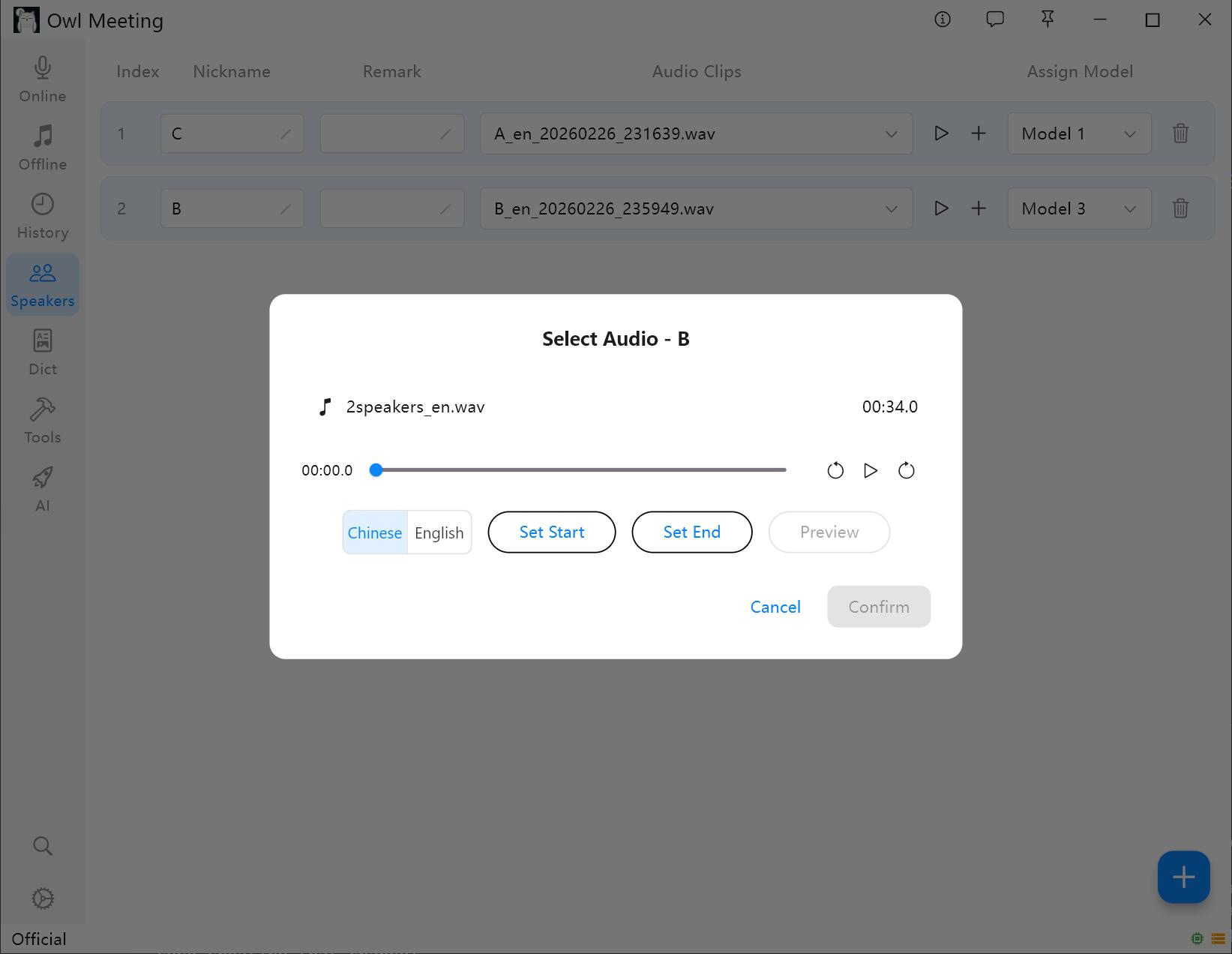 Voiceprint-monsters toevoegen en bijsnijden
Voiceprint-monsters toevoegen en bijsnijden
Best practices voor monsterverzameling
- Audiokwaliteit: kies clips met een rustige achtergrond en alleen de stem van de doelspreker, en vermijd segmenten waarin meerdere mensen tegelijkertijd spreken.
- Aanbeveling duur: elk monstersegment moet 5 tot 30 seconden duren. Kenmerken zijn onvoldoende als het te kort is, en er is geen extra voordeel als het te lang is.
- Meerdere monsters: een spreker kan meerdere monsters hebben. Als dezelfde persoon grote verschillen in timbre vertoont in verschillende scenario's (zoals face-to-face/telefoon), kan het toevoegen van meer monsters van verschillende scenario's de herkenningsgraad verbeteren.
- Taalovereenkomst: de taal die wordt geselecteerd bij het toevoegen van monsters moet consistent zijn met de [Voiceprint Language] in de Bestandstranscriptie-instellingen; anders zal de matching volledig mislukken. De kenmerkruimtes van de Chinese en Engelse voiceprint-modellen zijn incompatibel met elkaar.
3. Dagelijks onderhoud
- U kunt de naam, opmerkingen en het gespecificeerde model van de spreker op elk gewenst moment wijzigen.
- Schakel tussen het bekijken van verschillende monsters en luister er direct naar.
- Bij het verwijderen van een monster wordt ook het bijbehorende lokale audiobestand gewist.
4. Hoe de voiceprint-bibliotheek van kracht wordt in de transcriptie
De voiceprint-bibliotheek speelt voornamelijk een rol bij Offline bestandstranscriptie. Om de transcriptieresultaten automatisch de naam van de spreker te laten weergeven, moet tegelijkertijd aan de volgende voorwaarden worden voldaan:
- Selecteer [Speaker] als segmentatiemethode.
- Schakel de schakelaar [Identity Mark] in.
- De [Voiceprint Language] in de bestandstranscriptie-instellingen is consistent met de taal die is geselecteerd bij het toevoegen van monsters.
Nadat aan de bovenstaande voorwaarden is voldaan, wordt het sprekerlabel in het herkenningsresultaat automatisch vervangen door de echte naam die is ingevoerd in de voiceprint-bibliotheek.
5. Veelgestelde vragen en probleemoplossing
- V: Waarom tonen de herkenningsresultaten alleen Speaker_0, Speaker_1 en geen namen?
A: Controleer de drie punten uit "Hoe de voiceprint-bibliotheek van kracht wordt in de transcriptie" een voor een. De meest voorkomende reden is dat men vergeet [Identity Mark] in te schakelen of een mismatch in de voiceprint-taal. - V: Namen zijn gelabeld, maar ze zijn verkeerd toegewezen aan de verkeerde mensen?
A: Probeer de "Herkenning-matchdrempel" te verhogen (in het gedeelte [Separation]file-transcription.html">Bestandstranscriptie-instellingen), of voeg opnieuw duidelijkere voiceprint-monsters toe voor de betreffende spreker. - V: Het aantal automatisch herkende personen is onjuist?
A: Het wordt aanbevolen om het [Speaker Count] handmatig op te geven in de instellingen. Bij gebruik van de automatische modus kunt u de "Clusteringdrempel" fijnmaken om de gevoeligheid van het systeem voor geluidsverschillen te regelen.