🤖 KI-Assistent
Owl Meeting lässt sich in verschiedene große Sprachmodelle (LLM) integrieren, um eine intelligente Verarbeitung von Besprechungsinhalten direkt in der Anwendung zu ermöglichen.
1. KI-Dienst konfigurieren
Lokales Ollama (empfohlen, vollständig offline)
- Besuchen Sie ollama.com/download, um Ollama herunterzuladen und zu installieren.
- Überprüfen Sie die Dienstadresse in den KI-Einstellungen von Owl Meeting (Standard ist
http://localhost:11434/api). - Klicken Sie auf „Testen“, um zu bestätigen, dass die Verbindung ordnungsgemäß funktioniert.
- Suchen Sie in der Ollama-Modellbibliothek nach dem gewünschten Modell (z. B.
qwen3:4b) und laden Sie es herunter.
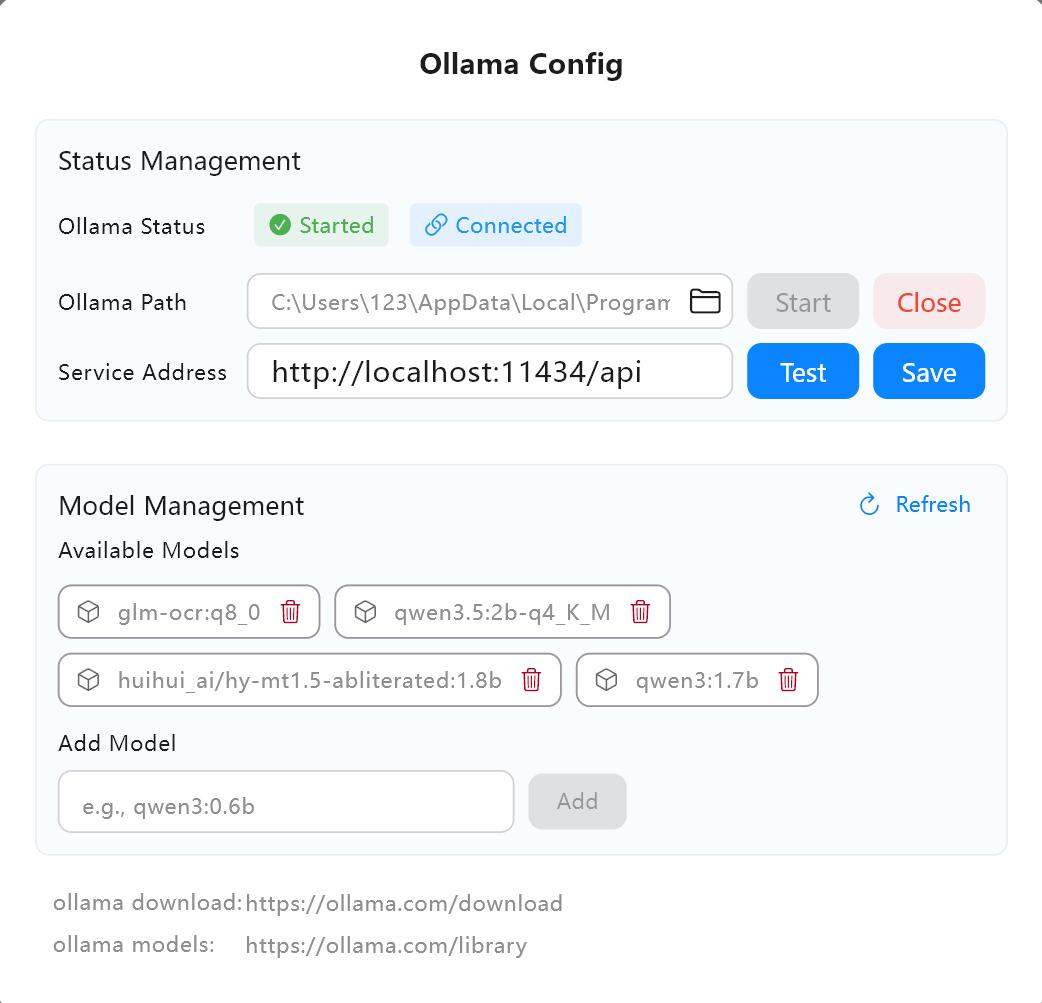 Benutzeroberfläche zur Konfiguration des KI-Dienstes
Benutzeroberfläche zur Konfiguration des KI-Dienstes
2. Vier Aufgabentypen
- Übersetzung: Übersetzt Erkennungsergebnisse in andere Sprachen. Sie können die Quellsprache und die Zielsprache festlegen.
- Korrektur: Korrigiert Tippfehler und grammatikalische Fehler und optimiert die Satzstruktur für einen besseren Lesefluss.
- Zusammenfassung: Erstellt Besprechungsprotokolle oder Inhaltszusammenfassungen.
- Benutzerdefiniert: Verwenden Sie benutzerdefinierte Prompt-Vorlagen, um Ergebnisse nach Ihren Bedürfnissen zu verarbeiten (z. B. Extrahieren von Aktionselementen, Erstellen von To-do-Listen).
3. Drei Eingabemodi
- Einzeln: Verarbeitet Segmente einzeln nacheinander. Dies ist der einzige Modus, der bei Verwendung der KI während der Echtzeit-Transkription verfügbar ist.
- Batch: Fasst mehrere Ergebnisse zusammen und sendet sie gemeinsam an das Modell, um die Effizienz zu steigern. Die Batch-Größe ist anpassbar.
- Volltext: Sendet alle Erkennungsergebnisse auf einmal als vollständigen Text. Ideal für Besprechungszusammenfassungen oder vollständige Übersetzungen.
4. Echtzeit-KI vs. Offline-KI
- Echtzeit-KI: Während der Echtzeit-Transkription wird jedes erkannte Segment automatisch zur Verarbeitung an das Modell gesendet und synchron angezeigt. Erfordert den Start der KI-Aufgabe in der Seitenleiste. Nur der Modus „Einzeln“ wird unterstützt.
- Offline-KI: Verarbeitet abgeschlossene Transkriptionsergebnisse auf der Verlaufsdetailseite. Unterstützt die Modi „Einzeln“, „Batch“ und „Volltext“.
5. Benutzerdefinierte Modellparameter
Integrierte Konfiguration für gängige LLM-Parameter (z. B. Temperature, Top_p). Fortgeschrittene Benutzer können das Modellparameter-Panel für eine Feinabstimmung aktivieren oder benutzerdefinierte Parameter im JSON-Format übergeben.
6. Häufig gestellte Fragen (FAQ)
- Q: Verbindung zu Ollama nicht möglich?
A: Überprüfen Sie, ob Ollama ausgeführt wird und ob die Dienstadresse korrekt ist (Standard:http://localhost:11434/api). - Q: Langsame Ausgabe?
A: Wechseln Sie zu einem Modell mit weniger Parametern (z. B. 1.5B oder 4B) oder ändern Sie den Eingabemodus von „Volltext“ auf „Einzeln“. - Q: Echtzeitmodus meldet „Bitte zuerst die blaue Taste klicken“?
A: Echtzeit-KI-Aufgaben erfordern, dass das KI-Modul zuerst über die blaue Taste in der Seitenleiste gestartet wird.
7. Empfohlene Modelle
- Übersetzung: Empfohlen HY-MT1.5-1.8B – ein professionelles Übersetzungsmodell, das mehrere Sprachen unterstützt und extrem schnell arbeitet.
- Allgemein: Empfohlen Qwen-Serie (z. B. 4B oder 8B), die eine hervorragende Verständnisfähigkeit besitzt.
Profi-Tipp: Für höchste Datensicherheit empfehlen wir die Kombination der Transkription mit
einem lokal betriebenen Llama-Modell über Ollama.