Voiceprint und Sprecherverwaltung
Die Voiceprint-Bibliothek ist die Kernfunktion von Owl Meeting, um zu „wissen, wer spricht“. Durch das Vorab-Aufzeichnen von Sprachproben jeder Person kann das System den Namen des Sprechers während der Dateitranskription automatisch identifizieren und kennzeichnen und sogar das am besten geeignete Erkennungsmodell für verschiedene Personen festlegen.
1. Hinzufügen eines Sprechers
- Rufen Sie die „Voiceprint-Bibliothek“ in der linken Symbolleiste auf.
- Klicken Sie auf „Person hinzufügen“, geben Sie den Namen ein (erforderlich) und fügen Sie Anmerkungen hinzu (optional).
- Zuweisen eines Erkennungsmodells für den Sprecher: Wenn der „Intelligente Modus“ in der Dateitranskription aktiviert ist, verwendet das System automatisch das hier angegebene Modell, um die Stimme des Sprechers zu erkennen.
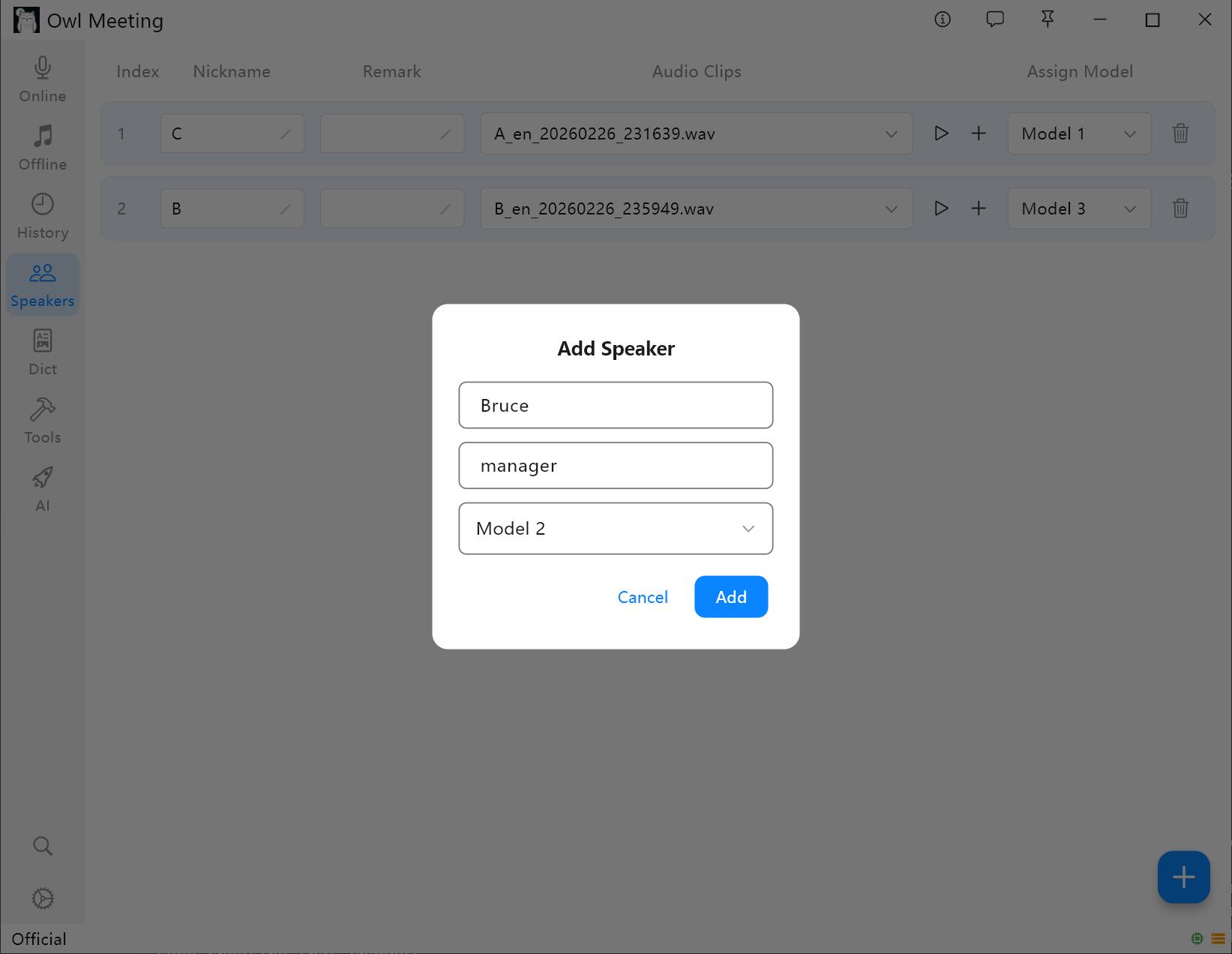 Verwaltungsoberfläche der Voiceprint-Bibliothek
Verwaltungsoberfläche der Voiceprint-Bibliothek
2. Hinzufügen von Voiceprint-Proben
- Wählen Sie einen Sprecher aus und klicken Sie auf „Audio hinzufügen“.
- Wählen Sie eine Audiodatei aus, die eine klare menschliche Stimme des Sprechers enthält.
- Legen Sie Start- und Endzeit im Zuschneidefenster fest und klicken Sie zur Bestätigung auf „Anhören“.
- Wählen Sie die Voiceprint-Sprache: Wählen Sie „Chinesisch“ für chinesische Proben und „Englisch“ für englische Proben. Andere Sprachen können basierend auf der Sprachfamilie ausgewählt werden.
- Klicken Sie auf Speichern; das System extrahiert automatisch die Voiceprint-Merkmale und ordnet sie dem Sprecher zu.
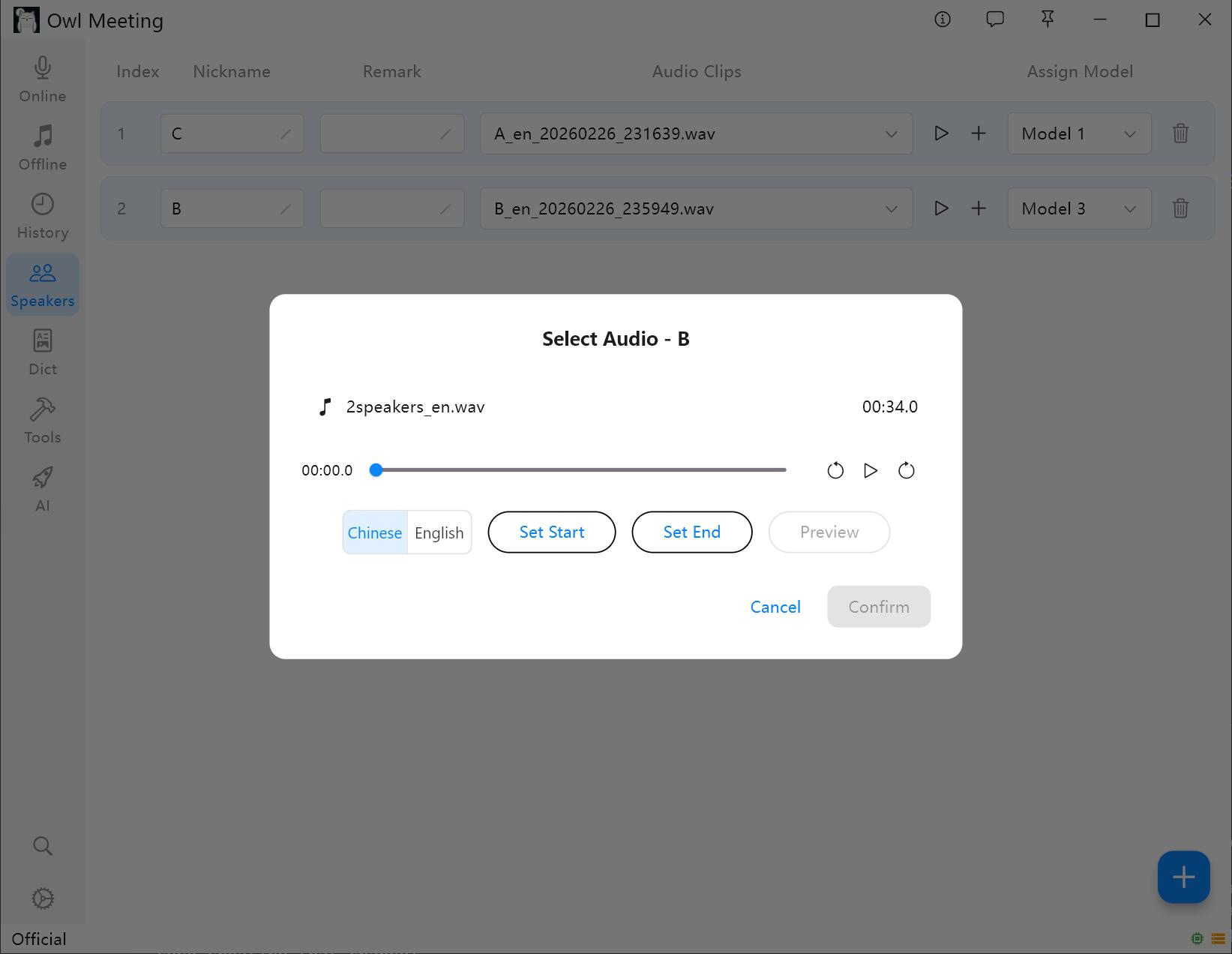 Hinzufügen und Zuschneiden von Voiceprint-Proben
Hinzufügen und Zuschneiden von Voiceprint-Proben
Best Practices für die Probennahme
- Audioqualität: Wählen Sie Clips mit ruhigem Hintergrund und nur der Stimme des Zielsprechers aus; vermeiden Sie Segmente, in denen mehrere Personen gleichzeitig sprechen.
- Dauer-Empfehlung: Jedes Proben-Segment sollte 5 bis 30 Sekunden lang sein. Bei zu kurzen Segmenten reichen die Merkmale nicht aus, und bei zu langen Segmenten gibt es keinen zusätzlichen Nutzen.
- Mehrere Proben: Einem Sprecher können mehrere Proben hinzugefügt werden. Wenn dieselbe Person unter verschiedenen Szenarien (z. B. persönlich/Telefon) große Unterschiede im Timbre aufweist, kann das Hinzufügen mehrerer Proben aus verschiedenen Szenarien die Erkennungsrate verbessern.
- Sprachanpassung: Die beim Hinzufügen von Proben ausgewählte Sprache muss mit der „Voiceprint-Sprache“ in den Dateitranskriptionseinstellungen übereinstimmen; andernfalls schlägt der Abgleich vollständig fehl. Die Merkmalräume der chinesischen und englischen Voiceprint-Modelle sind nicht miteinander kompatibel.
3. Tägliche Wartung
- Ändern Sie den Namen, die Anmerkungen und das angegebene Modell des Sprechers jederzeit.
- Wechseln Sie zwischen der Anzeige verschiedener Proben und hören Sie diese direkt an.
- Beim Löschen einer Probe wird auch die entsprechende lokale Audiodatei bereinigt.
4. Wie die Voiceprint-Bibliothek bei der Transkription wirksam wird
Die Voiceprint-Bibliothek spielt hauptsächlich bei der Offline-Dateitranskription eine Rolle. Damit in den Transkriptionsergebnissen der Name des Sprechers automatisch angezeigt wird, müssen folgende Bedingungen gleichzeitig erfüllt sein:
- Wählen Sie „Sprecher“ als Segmentierungsmethode aus.
- Aktivieren Sie den Schalter „Identitäts-Tagging“.
- Die „Voiceprint-Sprache“ in den Dateitranskriptionseinstellungen stimmt mit der beim Hinzufügen von Proben ausgewählten Sprache überein.
Nach Erfüllung der oben genannten Bedingungen wird das Sprecher-Tag im Erkennungsergebnis automatisch durch den in der Voiceprint-Bibliothek eingegebenen Realnamen ersetzt.
5. FAQ und Fehlerbehebung
- F: Warum zeigen die Erkennungsergebnisse nur Speaker_0, Speaker_1 und keine Namen an?
A: Bitte überprüfen Sie nacheinander die drei Punkte in „Wie die Voiceprint-Bibliothek bei der Transkription wirksam wird“. Der häufigste Grund ist das Vergessen der Aktivierung von „Identitäts-Tagging“ oder ein Nichtübereinstimmen der Voiceprint-Sprache. - F: Namen werden getaggt, aber sie sind falsch zugeordnet?
A: Versuchen Sie, den „Erkennungsabgleich-Schwellenwert“ zu erhöhen (im Bereich „Sprecher-Diarisierung und Tagging“ der Dateitranskriptionseinstellungen) oder fügen Sie für den entsprechenden Sprecher klarere Voiceprint-Proben hinzu. - F: Die Anzahl der automatisch erkannten Personen ist falsch?
A: Es wird empfohlen, die „Anzahl der Sprecher“ in den Einstellungen manuell anzugeben. Wenn Sie den automatischen Modus verwenden, können Sie den „Cluster-Schwellenwert“ feinabstimmen, um die Empfindlichkeit des Systems gegenüber Klangunterschieden zu steuern.