🎞️ Audio- und Videodatei-Transkription
Der Audio- und Videotranskriptionsmodus (Offline-Modus) ist speziell für die Verarbeitung vorhandener Audio- und Videodateien konzipiert. Die gesamte Verarbeitung erfolgt lokal, wodurch Ihr Geschäftsgeheimnis und Ihre Datensicherheit gewährleistet sind.
🚀 Schnelleinstieg
- Dateien importieren: Ziehen Sie Audio-/Videodateien direkt in das Softwarefenster oder klicken Sie in der Mitte auf „[Select File]
- Modus und Modell wählen: Wählen Sie auf der rechten Seite der Benutzeroberfläche die gewünschte Verarbeitungsmethode aus.
- Sofort starten: Klicken Sie unten auf die Schaltfläche „Start“. Sie können den Verarbeitungsfortschritt in Echtzeit verfolgen (Initialisierung -> Vorverarbeitung -> Segmentierung -> Erkennung).
1. Audioformate und Vorverarbeitung
Owl Meeting verfügt über eine starke Dateikompatibilität, aber das Verständnis der folgenden Details vor Beginn kann die Genauigkeit erheblich verbessern:
- Format-Unterstützung: Native Unterstützung für MP3, WAV, M4A, MP4, MKV, MOV, FLAC und fast alle anderen gängigen Audio-/Videoformate.
- Denoise: Wenn Ihre Aufnahme erhebliche Hintergrundgeräusche aufweist, wird empfohlen, im rechten Bereich die „Rauschunterdrückung“ zu aktivieren. Nach der Verarbeitung können Sie im Player frei zwischen Original- und verbessertem Ton wechseln, um den Effekt zu testen.
- Kanal-Empfehlung: Für Mehrkanal-Videodateien wird empfohlen, integrierte Tools zu verwenden, um diese zuerst in Mono-Audio zu extrahieren/konvertieren, um ein präziseres Erkennungserlebnis zu erzielen.
 Datei per Drag-and-Drop und Format-Unterstützung
Datei per Drag-and-Drop und Format-Unterstützung
2. Erkennungsmodus und Segmentierung
Sie können Erkennungsstrategien basierend auf der Komplexität des Dateiinhalts flexibel kombinieren:
- Regulärer Modus: Die gesamte Datei verwendet dasselbe Spracherkennungsmodell für die Transkription. Einfach und direkt, schnellste Geschwindigkeit.
- Smart: Wird in Verbindung mit der Sprecheridentifizierung verwendet. Sie können verschiedenen identifizierten Sprechern exklusive Modelle zuweisen (z. B. Sprecher A Modell 1 und Sprecher B Modell 2 zuweisen).
- Segmentierungsstrategie:
- Zeitintervall (VAD): Segmentiert automatisch basierend auf Sprechpausen, geeignet für persönliche Erklärungen und Podcasts.
- Separation: Schneidet automatisch basierend auf Sprachmerkmalen. Tipp: Vor dem Start müssen Sie ein Voiceprint-Modell (Chinesisch/Englisch) festlegen; andere Sprachen können basierend auf der Sprachfamilie ausgewählt werden.
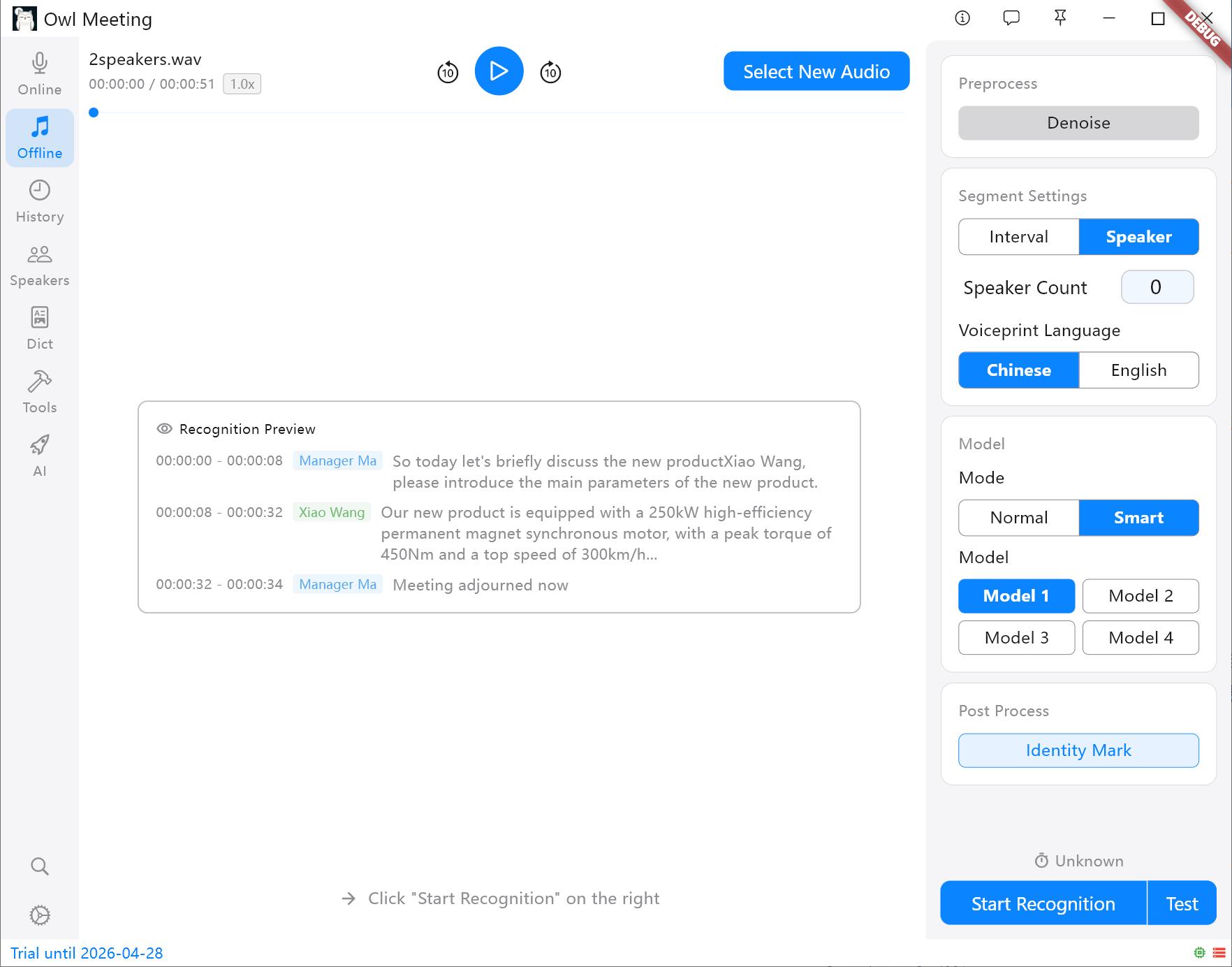 Segmentierungsmethoden und Einstellungsbereich
Segmentierungsmethoden und Einstellungsbereich
3. Testmodus
Vorschau des Erkennungseffekts der Einstellungen.
- Testmodus: Vor der Verarbeitung sehr langer Audiodaten können Sie die Testfunktion verwenden, um zu überprüfen, ob die aktuellen Parameter den Erwartungen entsprechen (es werden die aktuellen Parameter verwendet, um zufällig drei Minuten Audio zur Erkennung auszuwählen).
4. Exklusive Einstellungen und Feinanpassung
Im Offline-Einstellungsbereich entsprechen die VAD-Segmentierungsparameter (Spracherkennungsschwelle, min. Stille-/Sprach-/max. Sprachzeit, Padding) denen der Echtzeiterkennung. Einzelheiten finden Sie in der Dokumentation zur Echtzeit-Transkription. Hier sind die exklusiven Konfigurationselemente für die Dateitranskription:
Sprechertrennung und Markierung
Wenn die Segmentierungsmethode auf „Sprecher“ eingestellt ist, bestimmen die folgenden Parameter die Qualität der Trennung:
- Anzahl der Sprecher: Wenn Sie genau wissen, wie viele Personen im Audio sprechen, geben Sie direkt die spezifische Anzahl an (1 bis 10), um das beste Ergebnis zu erzielen. Wenn Sie „Auto“ wählen, bestimmt die Clustering-Schwelle die Anzahl der Personen.
- Clustering-Schwelle (nur im „Auto“-Modus wirksam): Steuert die Empfindlichkeit des Systems gegenüber Klangunterschieden. Je niedriger der Wert, desto einfacher ist es, unterschiedliche Klangfarben in verschiedene Personen zu trennen (eine Person kann in zwei aufgeteilt werden); je höher der Wert, desto einfacher ist es, ähnliche Klangfarben als dieselbe Person zu gruppieren (zwei Personen können zusammengeführt werden).
- Min. Sprachzeit: Sprachsegmente, die kürzer als diese Dauer sind, werden verworfen, wodurch sehr kurze Geräusche wie Husten oder Interjektionen gefiltert werden.
- Max. Zusammenführungsintervall: Benachbarte Segmente desselben Sprechers mit einem Zeitintervall von weniger als diesem Wert werden automatisch zusammengeführt, um eine fragmentierte Segmentierung zu reduzieren.
- Identity Mark: Wenn aktiviert, vergleicht das System die identifizierten Sprecher mit denen, die bereits in der Voiceprint-Bibliothek eingegeben wurden, und beschriftet automatisch deren echte Namen. Dies ist auch eine Voraussetzung für die Verwendung des „Intelligenten Modus“.
- Voiceprint-Sprache: Wählen Sie „Chinesisch“ für chinesische Szenarien und „Englisch“ für englische Szenarien. Hinweis: Die Merkmalsräume von chinesischen und englischen Voiceprint-Modellen sind inkompatibel; die Wahl der falschen Sprache führt zum vollständigen Fehlschlagen des Abgleichs. Andere Sprachen müssen basierend auf ihren Sprachfamilien getestet werden.
- Erkennungs-Match-Schwelle (erfordert Identitätsmarkierung): Die Identität wird nur bestimmt, wenn das Ergebnis des Voiceprint-Vergleichs höher als dieser Wert ist. Er sollte nicht zu hoch eingestellt werden, da bekannte Personen sonst möglicherweise nicht erkannt werden.
Erweiterte Segmentierungskonfiguration
- Intelligente Zusammenführung: Führt kurze Sätze automatisch basierend auf dem Zeitintervall zwischen benachbarten Segmenten zusammen, wodurch fragmentierte Segmente reduziert und die allgemeine Erkennungsgenauigkeit verbessert wird.
- Zusammenführungsintervall: Die Zusammenführung wird ausgelöst, wenn das Intervall zwischen zwei Segmenten geringer als dieser Wert (Sekunden) ist.
Modellspezifische Konfiguration
- Modell 1 Quantisierte Version: Wenn aktiviert, ist die Inferenzgeschwindigkeit etwas schneller, aber die Genauigkeit etwas geringer, was auf die meisten Szenarien kaum Auswirkungen hat.
- Modell 1 Sprache: Im Allgemeinen ist „Auto“ in Ordnung; das manuelle Festlegen der Sprache (Chinesisch/Englisch/Japanisch/Koreanisch), wenn diese eindeutig bekannt ist, kann die Ausgabequalität verbessern.
- Modell 1 integrierte Interpunktion + Text-zu-Zahl: Aktiviert die in das Modell integrierte Interpunktion und Zahlenkonvertierung, z. B. die Ausgabe von „fünfzig Kilometer“ als „50 Kilometer“.
Systemdienste
- Text-zu-Zahl: Wird nur für Chinesisch unterstützt und wandelt gesprochene Zahlen in Standardformate um.
- Interpunktion (Chinesisch, Englisch): Wenn die Interpunktion in den Erkennungsergebnissen abnormal ist (z. B. wenn nach der Aktivierung von Intelligenter Zusammenführung eine große Anzahl von Punkten erscheint), kann dieser Punkt zur Reparatur der Interpunktion aktiviert werden (Interpunktionsmodelle müssen zuerst unter „Modellverwaltung“ heruntergeladen werden).
5. Effizientere Nachbearbeitung
Nach Abschluss der Erkennung können Sie integrierte Tools verwenden, um direkt hochwertige Manuskripte zu erstellen:
- Vereinfacht/Traditionell Konvertierung: Ein-Klick-Konvertierung zwischen vereinfachtem und traditionellem Chinesisch (unterstützt den Abgleich für Taiwan und Hongkong traditionelles Chinesisch).
- Inhaltsdeduplizierung: Automatische Entfernung doppelter Wörter, die durch Audioüberschneidungen oder Modellhalluzinationen verursacht werden.
- Ersetzung von Fachwörtern: Verwenden Sie die Funktion „Fachwörterbuch“, um Fachtermini oder Namenskürzel im Text mit einem Klick zu korrigieren.
6. Extreme Leistung
Dank der tief optimierten lokalen Inferenz-Engine kann Owl Meeting selbst auf der CPU eines gewöhnlichen Bürocomputers extreme Geschwindigkeiten erreichen:
- Einsteiger-/Alte Computer (z. B. i5-4210m): Eine 30-minütige Audiodatei kann in etwa 3 Minuten abgeschlossen werden.
- Gängige Heim-/Bürocomputer (z. B. i5-11400H): Eine 30-minütige Audiodatei dauert normalerweise nur etwa 1 Minute.
7. FAQ und Tipps
- F: Warum wird in der Dokumentation wiederholt betont, Mehrkanal in Mono umzuwandeln?
A: Mehrkanalaufnahmen (Stereo) sind in komplexen Umgebungen anfällig für Echostörungen. Nach der Konvertierung in Mono erfolgt die Extraktion des Voiceprints durch die KI-Engine reiner, was die Genauigkeit der Sprechertrennung erheblich verbessern kann. - F: Aus den identifizierten Sprechern wurden Speaker_0, Speaker_1...?
A: Dies sind temporäre IDs, die vom System zugewiesen werden. Sie können direkt auf der Ergebnisseite auf diese IDs klicken, um sie global umzubenennen. Das System zeichnet sie automatisch auf und sie werden in den anschließend exportierten SRT- oder TXT-Dateien wirksam. - F: Ich möchte, dass der erkannte Text direkt in traditionelles Chinesisch umgewandelt wird?
A: Klicken Sie nach Abschluss der Erkennung auf die Schaltfläche „Vereinfacht/Traditionell Konvertierung“ unten und wählen Sie den entsprechenden Regionalcode (z. B. „Traditionelles Chinesisch“ oder „Taiwan Traditionell“) aus, um den gesamten Text mit einem Klick zu konvertieren.